“La duplicazione dei dati è il male assoluto”
Durante il corso di basi di dati all’università, il professore lo ripeteva con tale enfasi da sputacchiare mentre parlava. “Prima forma normale, seconda forma normale, terza forma normale… i dati duplicati sprecano spazio e rovinano l’integrità. Spezzate tutto, e poi spezzatelo ancora!”
Io ho seguito quell’insegnamento con grande diligenza. Nel progetto di laurea ho suddiviso le tabelle in 10, poi 20 frammenti. ‘User’, ‘Address’, ‘City’, ‘Zipcode’… Il mio schema era così perfettamente “da manuale” che per memorizzare un solo indirizzo servivano tre tabelle diverse.
Ma nel lavoro reale quella perfezione si è trasformata in un disastro. Volevo soltanto recuperare una lista clienti, e invece mi ritrovavo a scrivere cinque JOIN. La query diventava complessa, le prestazioni peggioravano e, soprattutto, il processo di trasportare quei dati dentro oggetti Java era dolorosissimo.
“Possibile che, per recuperare una sola riga di dati da mostrare a schermo, il codice debba diventare così complicato?”
Fu allora che capii davvero. A scuola ci insegnavano come ottimizzare il salvataggio. Nel lavoro vero conta molto di più l’efficienza della lettura. E tra un linguaggio orientato agli oggetti come Java e un database relazionale scorre un fiume molto più difficile da attraversare di quanto sembri.
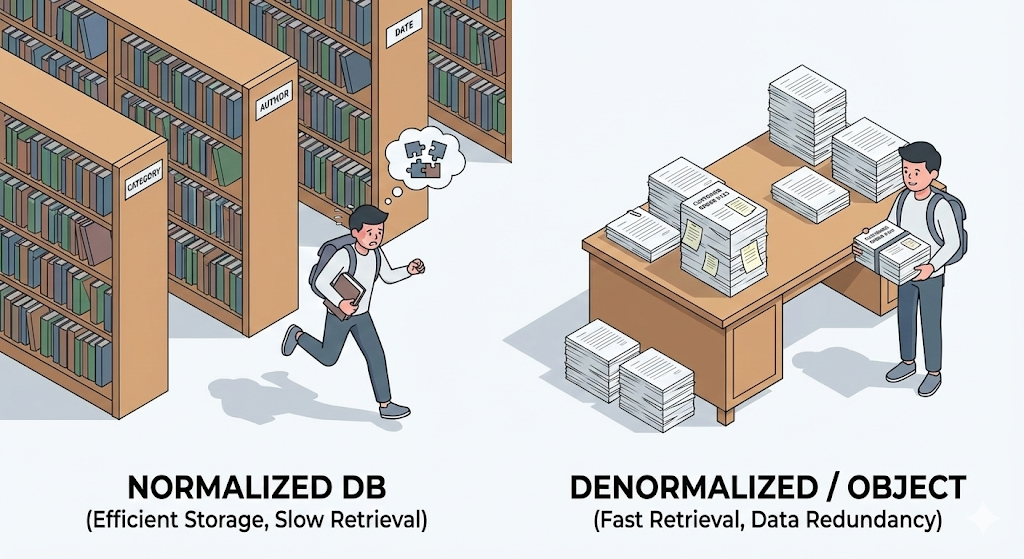
Disallineamento di paradigma: quadrati e cerchi
La causa profonda di questa sofferenza è ciò che si chiama disallineamento di paradigma, o Impedance Mismatch.
Ai tempi dell’università costringevo questi due mondi a incastrarsi scrivendo SQL a mano. Scomponevo gli oggetti Java per salvarli nel database con INSERT, poi li recuperavo con SELECT, leggevo i dati riga per riga dal ResultSet e li trasferivo uno a uno in collezioni Java come Set o List. Non mi sentivo uno sviluppatore, ma un traduttore di dati.
La tecnologia arrivata per eliminare questa ripetizione estenuante è stata proprio JPA (Java Persistence API), cioè il mondo di ORM (Object-Relational Mapping).
JPA e ORM: gestire il database attraverso gli oggetti
ORM, letteralmente, è una tecnologia che collega oggetti e database relazionali. Come dice il nome, il punto centrale è definire e trattare le tabelle del database come se fossero oggetti Java.
Non abbiamo più bisogno di scrivere a mano query CREATE TABLE. Al loro posto creiamo una classe Java e ci attacchiamo sopra un’etichetta chiamata @Entity. Poi JPA, lo standard ORM nel mondo Java, guarda quella classe e pensa: “Ah, quindi ti serve una tabella fatta così”, e la crea automaticamente nel database.
Anche quando salviamo i dati non dobbiamo più scrivere SQL. Basta un repository.save(member), quasi come se stessimo aggiungendo un elemento a una collezione Java. Lo sviluppatore resta completamente nel proprio modo di pensare orientato agli oggetti, mentre il lavoro sporco di tradurre in SQL viene scaricato su JPA.
Ma, come abbiamo imparato nella serie Re: Booting, la comodità ha sempre un prezzo. E proprio perché mi sono fidato troppo di questo traduttore automatico chiamato JPA, ho finito per piantare nel mio codice una bomba a orologeria: il problema N+1.
[Code Verification] Il problema N+1, una bomba di query
È un problema in cui si imbatte praticamente qualsiasi sviluppatore junior alla prima esperienza con JPA. La situazione è semplice: “Stampa tutti i membri e il nome del team a cui appartengono.”
// 1. Recupera tutti i membri (1 query eseguita)
List<Member> members = memberRepository.findAll();
for (Member member : members) {
// 2. Stampa il nome della squadra di ciascun membro
// Con 100 membri, vengono eseguite 100 query aggiuntive per recuperare le squadre!
System.out.println(member.getTeam().getName());
}
La query che ci aspettavamo: SELECT * FROM Member JOIN Team ... (una sola volta)
La query che si è verificata davvero:
Se i membri sono 100, le query diventano 101: 1 + N. E se sono 10.000? Allora 10.001 query si abbattono sul database. Questo è il famigerato problema N+1, il tipo di problema che può mandare in crisi un server. JPA ha cercato di essere comodo caricando i dati collegati in modo lazy, cioè al momento del bisogno, e proprio quella comodità si è trasformata nel disastro.
Consiglio pratico: progettazione pragmatica del database
Cosa bisogna fare, allora, nella pratica? Occorre trovare un equilibrio tra la normalizzazione da manuale e la comodità di JPA.
In chiusura: per stare più comodi bisogna sapere di più
JPA è senza dubbio una rivoluzione. Ci ha liberati dalla ripetizione estenuante di scrivere SQL ancora e ancora. Ma pensare “ormai uso JPA, quindi non ho più bisogno di conoscere SQL” è pericoloso.
JPA non è un mago. È soltanto una segretaria che scrive SQL al posto tuo. Se dai istruzioni sbagliate a quella segretaria, per esempio con mapping errati, caricamenti EAGER e così via, lei lancerà silenziosamente cento query e finirà per abbattere il database. Per controllare e ottimizzare se il SQL generato da JPA sia davvero efficiente, paradossalmente, bisogna conoscere SQL ancora più a fondo. La comodità porta sempre con sé una responsabilità.
Ora sappiamo come mettere i dati dentro oggetti. Ma possiamo davvero mandare quegli oggetti, cioè le entity, così come sono al frontend, per esempio a Vue.js? E se l’entity User contenesse una password? E cosa succede alla sicurezza se finiamo per inviare al frontend informazioni che non avrebbe mai dovuto vedere?
La prossima volta parleremo di DTO, Data Transfer Object, e di progettazione delle API REST, cioè delle tecniche con cui i dati vengono impacchettati e consegnati in modo sicuro.