”Dataduplicering är absolut ondska”
På databaskursen på universitetet brukade professorn understryka det så ivrigt att spottet flög. ”Första normalformen, andra normalformen, tredje normalformen… duplicerad data slösar lagringsutrymme och skadar integriteten. Dela upp det, och dela sedan upp det ännu mer!”
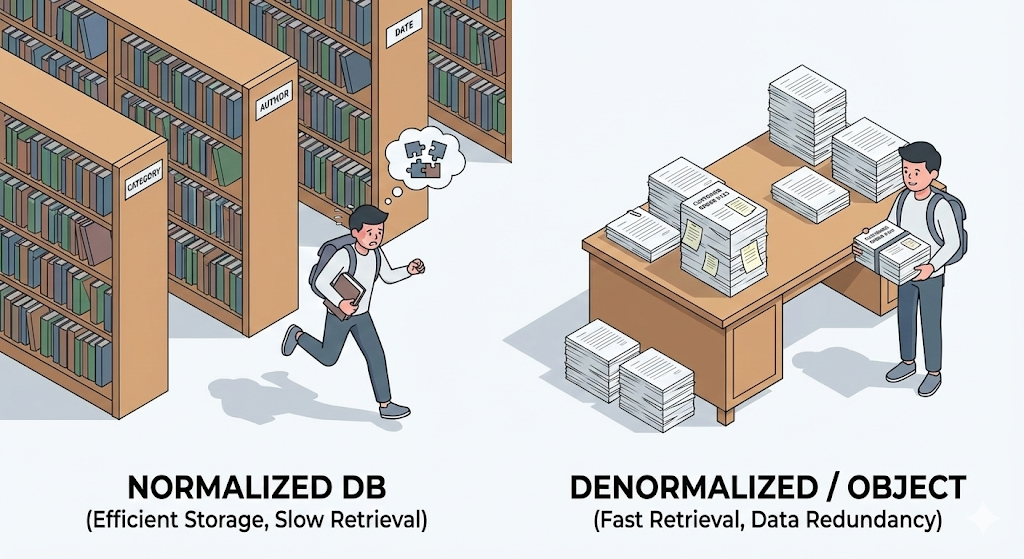
Jag följde den lärdomen troget. I mitt examensprojekt delade jag upp tabeller i 10, sedan 20 delar. ’User’, ’Address’, ’City’, ’Zipcode’… Min databasskiss var så perfekt ”enligt läroboken” att det krävdes tre tabeller bara för att lagra en enda adress.
Men i verkligt arbete blev det där perfekta upplägget en katastrof. Jag ville bara hämta en kundlista, men var tvungen att skriva fem JOINs. Frågan blev komplicerad, prestandan sjönk, och värst av allt: att flytta över den datan till Java-objekt var otroligt smärtsamt.
”Hur kan koden bli så här komplicerad när jag bara vill hämta en enda rad data för att visa den på skärmen?”
Först då förstod jag det. I skolan lärde man oss hur man optimerar lagring. I praktiken är läseffektivitet mycket viktigare. Och mellan ett objektorienterat språk som Java och en relationsdatabas flyter en flod som är mycket svårare att ta sig över än man först tror.
Paradigmkrock: fyrkanter och cirklar
Grundorsaken till den här smärtan är det som kallas paradigmkollision, eller Impedance Mismatch.
Under studietiden tvingade jag ihop de här två världarna genom att skriva SQL direkt själv. Jag plockade isär Java-objekt för att spara dem i databasen med INSERT, hämtade sedan tillbaka dem med SELECT, läste dem rad för rad ur ett ResultSet och flyttade dem mödosamt till Java-samlingar som Set eller List. Jag kände mig inte som en utvecklare, utan som en dataöversättare.
Tekniken som dök upp för att lösa det där tröttsamma upprepningsarbetet var just JPA (Java Persistence API), alltså världen av ORM (Object-Relational Mapping).
JPA och ORM: att hantera databasen genom objekt
ORM är bokstavligen en teknik som kopplar samman objekt och relationsdatabaser. Som namnet antyder är kärnan att definiera och hantera databastabeller som om de vore Java-objekt.
Vi behöver inte längre skriva CREATE TABLE-frågor för hand. I stället skapar vi en Java-klass och sätter på den en etikett som heter @Entity. Sedan tittar JPA, som är ORM-standarden i Java-världen, på klassen och tänker: ”Aha, det är alltså så här tabellen ska se ut”, och skapar den automatiskt i databasen.
Att spara data handlar inte heller längre om att skriva SQL själv. Det räcker med något som repository.save(member), nästan som om man lägger in ett element i en Java-samling. Utvecklaren stannar helt kvar i ett objektorienterat tankesätt, medan det smutsiga arbetet med att översätta till SQL lämnas över till JPA.
Men, precis som vi lärde oss i Re: Booting-serien, har bekvämlighet alltid ett pris. Och just för att jag litade för mycket på den där automatiska översättaren som heter JPA planterade jag en tidsinställd bomb i min kod: N+1-problemet.
[Code Verification] N+1-problemet, en bomb av frågor
Det här är ett problem som praktiskt taget varje juniorutvecklare råkar ut för första gången de använder JPA. Situationen är enkel: ”Visa alla medlemmar tillsammans med namnet på teamet de tillhör.”
// 1. Hamta alla medlemmar (1 forfragan)
List<Member> members = memberRepository.findAll();
for (Member member : members) {
// 2. Skriv ut varje medlems lagnamn
// Med 100 medlemmar gors 100 extra forfragningar for laginformation!
System.out.println(member.getTeam().getName());
}
Frågan vi förväntade oss: SELECT * FROM Member JOIN Team ... (bara en gång)
Frågan som faktiskt uppstod:
Om det finns 100 medlemmar skickas 101 frågor: 1 + N. Och om det finns 10 000 medlemmar? Då slår 10 001 frågor in i databasen. Det är exakt det berömda N+1-problemet, den sortens fel som kan få en server att gå ner. JPA försökte vara bekvämt genom att hämta relaterad data lazy, alltså först när den behövdes, och just den bekvämligheten förvandlades till katastrofen.
Praktiskt råd: pragmatisk databasdesign
Vad ska man då göra i praktiken? Man måste hitta en balans mellan läroboksnormalisering och den bekvämlighet som JPA erbjuder.
Avslutning: för att få det bekvämare måste du kunna mer
JPA är utan tvekan en revolution. Det har befriat oss från den tröttande upprepningen av att skriva SQL om och om igen. Men att tänka ”nu använder jag JPA, så jag behöver inte längre kunna SQL” är farligt.
JPA är ingen trollkarl. Det är bara en sekreterare som skriver SQL åt dig. Om du ger den sekreteraren dåliga instruktioner, genom felaktiga mappingar, EAGER loading och liknande, kommer den tyst att skjuta iväg hundra frågor och ta död på databasen. För att övervaka och trimma om SQL:en som JPA genererar verkligen är effektiv måste du paradoxalt nog förstå SQL ännu bättre. Bekvämlighet kommer alltid med ansvar.
Nu vet vi hur man lägger data i objekt. Men kan vi verkligen skicka de objekten, alltså entities, rakt vidare till frontend, till exempel Vue.js? Vad händer om User-entityn innehåller ett lösenord? Och vad händer med säkerheten om vi ger frontend information som den aldrig borde ha sett?
Nästa gång ska vi prata om DTO:er, Data Transfer Objects, och REST API-design, alltså teknikerna som används för att paketera och leverera data på ett säkert sätt.