“Eh? La build è già finita?”
Dopo aver provato la comodità di Docker, ho iniziato di nascosto, senza dirlo al team leader, a spostare poco a poco il mio ambiente di sviluppo su Docker. Ho scritto un progetto chiamato Dockerfile e lanciato il comando docker build.
La prima volta ci ha messo un po’. Tra il download di Ubuntu, l’installazione di Java e il recupero delle librerie, i JAR, del mio progetto, ci sono voluti circa cinque minuti. “Beh, essendo la prima volta, è normale che ci metta un po’.”
Ma quando ho corretto un semplice refuso nel codice e ho lanciato di nuovo la build, non credevo ai miei occhi. Appena ho premuto Enter, nel terminale è comparso Successfully built. Tempo impiegato: appena 0,1 secondi.
“Aspetta, si è rotto? Poco fa ci metteva cinque minuti. Com’è possibile che ora finisca in un istante?”
Ho avviato il server con un po’ di ansia, ma il codice era stato corretto perfettamente. Quindi che cosa stava succedendo dentro Docker? Il segreto di quella velocità folle si trovava in un particolare sistema di salvataggio chiamato ‘layer’.
Image e container
Prima di entrare nel meccanismo vero e proprio, chiariamo due termini che spesso si confondono.
Ciò che inviamo al server durante il deploy non è un ‘container’, ma un ‘image’. Il server deve solo ricevere quell’image ed eseguirla.
Layer: la magia del cellophane trasparente
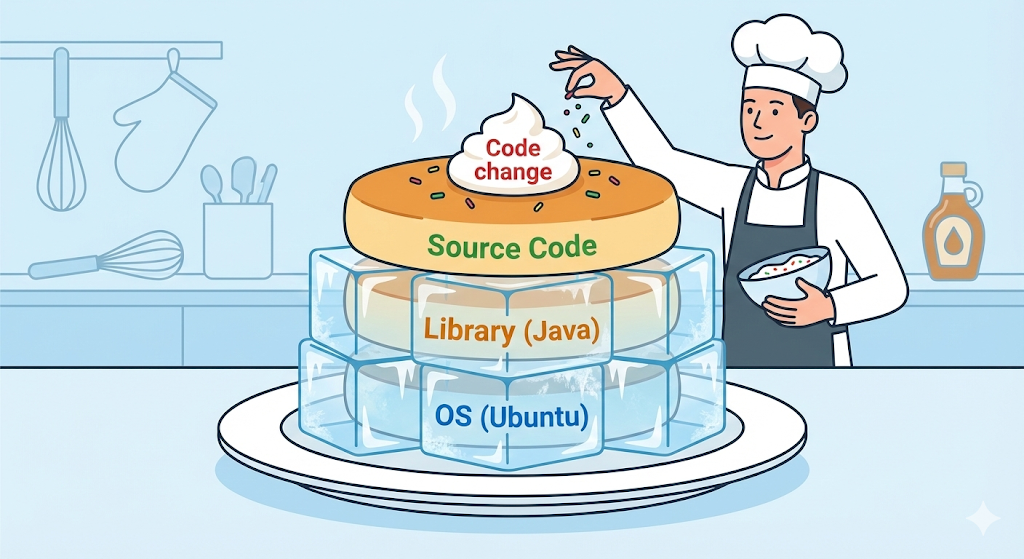
Una Docker image non è un unico file monolitico. Assomiglia piuttosto a più fogli di cellophane trasparente, layer, sovrapposti uno sopra l’altro. Ogni singola riga di istruzioni scritta in un Dockerfile diventa un layer a sé.
Facciamo un esempio.
# Strato 1: installa Ubuntu (OS)
FROM ubuntu:20.04
# Strato 2: installa Java
RUN apt-get install openjdk-17-jdk
# Strato 3: copia il mio codice
COPY my-app.jar /app/my-app.jar
# Strato 4: esegui
CMD ["java", "-jar", "/app/my-app.jar"]
Se si legge con calma il contenuto di un Dockerfile, ci si accorge che la struttura non è poi così complicata. “Installa Ubuntu, FROM, installa Java, RUN, porta dentro il mio codice, COPY, ed eseguilo, CMD.”
Alla fine non abbiamo fatto altro che prendere il processo di configurazione del server che prima digitavamo a mano in una VM o in un terminale di server e trascriverlo in un documento. Con quel solo documento, Docker esegue tutta l’installazione da solo, senza che nessuno debba guidarlo passo passo. Questo concetto si collega anche, più avanti, al principio centrale dell’automazione CI/CD.
Ma allora perché Docker non schiaccia tutto il processo in un solo passaggio? Perché lo divide appositamente riga per riga in layer e li impila con cura?
La risposta è riuso, cioè caching. Se modifico il codice e faccio di nuovo la build, Docker ragiona in modo intelligente: “Il primo piano, il sistema operativo, e il secondo, Java, sono identici a prima. Allora non c’è bisogno di ricostruirli. Basta riutilizzare i layer già presenti in cache.”
Poi ricostruisce solo a partire dal terzo piano che è cambiato, cioè il passaggio di copia del codice. Ecco perché la seconda build si è chiusa in appena 0,1 secondi.
[Code Verification] Vedere la cache dei layer con i propri occhi
Non fermiamoci alle parole: verifichiamolo con il codice. Basta creare un semplice Dockerfile e fare la build due volte.
FROM alpine:latest
RUN echo "1. Installazione utility di base..." && sleep 2 # Richiede 2 secondi
COPY test.txt /app/test.txt
CMD ["cat", "/app/test.txt"]
$ docker build -t my-test:v1 .
# Risultato:
# [2/3] RUN echo "1. Installazione utility di base..." ... 2.1s (2s impiegati)
$ docker build -t my-test:v2 .
# Risultato:
# [2/3] RUN echo "1. Installazione utility di base..." ... CACHED (0s!)
Vedi la parola CACHED stampata chiaramente nel log? Quella è la prova che Docker ha saltato un’operazione che normalmente richiederebbe due secondi.
Consiglio pratico: l’ordine è tutto
Quando si capisce il principio del caching dei layer, diventa chiaro anche come scrivere un Dockerfile. L’idea centrale è semplice: “Metti in basso, quindi prima, ciò che cambia poco, e in alto, quindi dopo, ciò che cambia spesso.”
Cattivo esempio:
# 1. Copia prima il codice sorgente (cambia spesso)
COPY . .
# 2. Installa le librerie (raramente cambia)
RUN npm install
Il codice sorgente cambia decine di volte al giorno. Se cambia il passaggio 1, Docker invalida anche la cache del passaggio 2, l’installazione delle librerie, e rilancia tutto. Correggi una sola riga di codice e ti ritrovi ad aspettare di nuovo npm install.
Buon esempio:
# 1. Copia prima solo package.json
COPY package.json .
# 2. Installa le librerie (resta in cache)
RUN npm install
# 3. Copia il codice sorgente
COPY . .
Basta cambiare l’ordine e la velocità della build può aumentare di dieci volte. È proprio questa la differenza tra chi è alle prime armi con Docker e chi lo sa usare davvero.
Consiglio pratico 2: i tag sono la tua linea di vita
Nell’esempio sopra ho scritto docker build -t my-test:v1 .. Qui, il v1 dopo i due punti, :, è il tag.
Molti principianti non usano i tag perché li trovano scomodi. Quando lo fanno, Docker assegna automaticamente il tag latest.
Questa sola abitudine dei tag ti proteggerà molte serate in futuro.
In chiusura: tenere tra le mani la magia degli 0,1 secondi
Una Docker image non è un semplice mucchio di file, ma un concentrato di tecnologia impilato nel modo più efficiente possibile per consegnare un ambiente. Se capisci il caching dei layer e ordini bene il tuo Dockerfile, puoi costruire un ambiente di deploy leggero e veloce che si completa in 0,1 secondi.
Ora è tutto pronto per congelare perfettamente l’ambiente del mio computer in un’image e inviarlo al server.
Ma quando ho provato davvero ad avviare questa image sul server, è comparso un nuovo problema. Un servizio web non funziona con un solo container server. Ha bisogno anche di un database, di Redis e di un server frontend.
Si possono davvero gestire tutti questi container accendendoli e spegnendoli uno a uno con comandi separati? Come comunicano tra loro? Come si costruisce un’intera applicazione andando oltre la singola ‘image’? La prossima volta allarghiamo l’orizzonte di Docker con i concetti di container, service e stack.