Povertà in abbondanza, ricordi dimenticati
Ho imparato la “struttura della memoria” durante le lezioni di sistema operativo o di programmazione di sistema a scuola. Ricordo anche termini come stack e heap usati come domande d’esame.
Ma a dire il vero, raramente ho prestato seria attenzione alla memoria finché non mi sono laureato. Al giorno d’oggi, la RAM del laptop personale è fondamentalmente 16 GB o 32 GB. Praticamente non c’era carenza di memoria durante lo svolgimento dei compiti di livello universitario. Inoltre, in linguaggi come Java, il Garbage Collector (GC) pulisce lo spazio automaticamente, quindi non devo preoccuparmi dell’indirizzo di memoria.
Così, inebriato dall’abbondanza di hardware e dalla comodità del linguaggio, mi sono buttato nel lavoro pratico dimenticandomi del “senso della memoria”, che è l’abilità di base di uno sviluppatore.
Lezioni dolorose apprese dalla pratica
Quando mi esercitavo per i test di codifica a scuola, tutto quello che potevo fare era inserire alcuni numeri in una matrice e girarli. Al massimo, il numero di dati immessi non ha superato i 100.000. Ma la pratica era diversa. Non importa quanto piccola fosse una startup, nel database venivano accumulati decine o milioni di dati reali sui clienti.
In pratica, per gestire comodamente questa grande quantità di dati viene utilizzata una tecnologia chiamata “ORM (Object Relational Mapping)”. È uno strumento molto utile che ti consente di gestire dati come oggetti Java senza dover scrivere tu stesso le query SQL. (Hibernate è un esempio rappresentativo nel campo Java.)
Il problema era che questo strumento era “troppo conveniente”. Premendo semplicemente un pulsante, tutti i dati nel DB venivano inseriti nell’elenco, quindi non potevo stimare il peso dei dati nascosti dietro di esso. Semplicemente scrivendo una singola riga di codice che diceva “Ottieni informazioni sui clienti”, decine di migliaia di informazioni sulle persone e i relativi dettagli sull’ordine venivano tutti caricati in memoria.
I risultati furono disastrosi. La RAM da 32 GB si è riempita in un istante. Il server soffriva di un “ritardo estremo” dovuto al tentativo di GC (pulizia) di proteggere la memoria e alla fine si è fermato.
Stack familiare, heap sconosciuto
Mentre guardavo il registro degli errori generato dal server, la mia attenzione è stata catturata da una parola.
java.lang.OutOfMemoryError: spazio heap Java
In realtà, la parola “stack” era abbastanza familiare. L’ho imparato fino alla nausea nel corso sulla struttura dei dati, ed è anche il nome di un sito (Stack Overflow) che gli sviluppatori visitano una volta al giorno. Era anche risaputo che se una funzione ricorsiva fosse stata scritta in modo errato, lo stack sarebbe scoppiato.
Tuttavia, in pratica, ogni volta che un server muore, il colpevole non è lo stack. Il registro degli errori puntava sempre a “Heap”.
“Non è che lo stack è pieno, è che non c’è abbastanza spazio heap?”
In quel momento mi è venuta in mente una domanda. Capisco lo stack, ma qual è l’heap? Perché esplode così spesso nella pratica? È lo stesso dell’heap nella struttura dei dati? Perché il mio codice disturba l’heap e non lo stack?
Questa domanda mi ha riportato al mondo dei grandi libri polverosi e delle ricerche su Google. E poi l’ho scoperto. Il fatto che “Memory (RAM)”, la casa in cui vive il mio codice, non è in realtà un’unica stanza, ma uno “spazio separato” completamente diviso e gestito in base allo scopo.
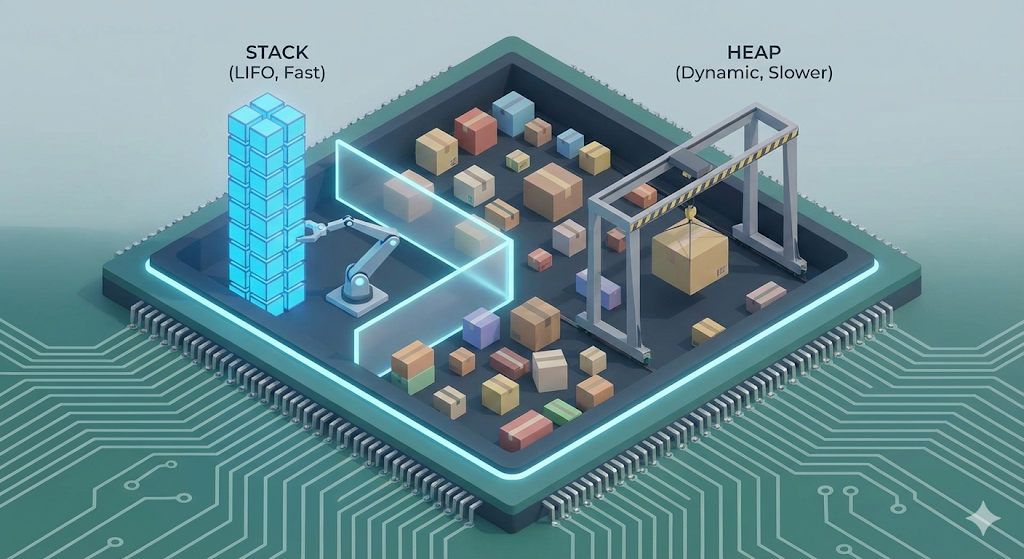
Banco di lavoro e magazzino nel centro di distribuzione digitale
Torniamo alla nostra visione del mondo del “centro logistico digitale”. Qui, la “RAM (memoria)” è lo spazio in cui il lavoratore (CPU) distribuisce gli elementi per svolgere il lavoro. Tuttavia, questo spazio è gestito in due aree separate per ragioni di efficienza.
1. Stack: il banco di lavoro personale del lavoratore
2. Heap: magazzino pubblico

[Verifica del codice] Due mondi provati da errori
La memoria è davvero divisa in questo modo? L’esistenza di questi due spazi può essere chiaramente dimostrata provocando intenzionalmente un errore nel codice.
1. Errore di overflow dello stack
Lo stack è chiamato “banco di lavoro”. Il banco di lavoro è stretto. Se la funzione non termina e continua a chiamarsi (ricorsione), i documenti si accumulano fino al soffitto sul banco di lavoro e alla fine crollano.
public class StackTest {
public static void recursiveCall(int depth) {
// Chiamata ricorsiva infinita: la funzione non termina e continua ad accumularsi nello Stack
System.out.println("Stack Depth: " + depth);
recursiveCall(depth + 1);
}
public static void main(String[] args) {
recursiveCall(1);
}
}
Risultato: dopo diverse migliaia di cicli, viene visualizzato StackOverflowError. Non importa quanto sia vuoto lo spazio heap, se lo stack (workbench) è pieno, il programma muore.
2. Esplosione dell’heap (OutOfMemoryError)
Questa volta ricreiamo l’incubo che ho avuto. Similmente alla situazione in cui decine di migliaia di oggetti vengono caricati contemporaneamente a causa di un uso errato di ORM, continueremo a creare elenchi enormi e a stiparli nell’heap.
import java.util.ArrayList;
import java.util.List;
public class HeapTest {
public static void main(String[] args) {
List<byte[]> warehouse = new ArrayList<>();
while (true) {
// Continua a creare dati da 1MB accumulandoli nel magazzino (Heap)
// Esempio pratico: si verifica quando si caricano decine di migliaia di record dal DB senza paginazione
warehouse.add(new byte[1024 * 1024]);
}
}
}
Risultato: java.lang.OutOfMemoryError: spazio heap Java. Questo non è un problema di stack. Questo errore si verifica perché non c’è più spazio per caricare gli articoli nel magazzino. Questo è il momento in cui vedo con i miei occhi come il codice che ho scritto stia dando fastidio al mucchio.
Garbage Collector (GC)
Qui c’è una differenza importante. Lo stack viene svuotato ‘automaticamente’ al termine della funzione. Non c’è bisogno di preoccuparsi. Tuttavia, se qualcuno non pulisce il mucchio, la spazzatura continua ad accumularsi.
Nei vecchi linguaggi come il linguaggio C, gli sviluppatori dovevano pulirli direttamente con il comando free(). Se dimentichi, il magazzino si riempirà di spazzatura ed esploderà (perdita di memoria). D’altra parte, linguaggi moderni come Java, Python e JavaScript (JS) utilizzano strumenti di pulizia professionali chiamati “GC (Garbage Collector)”.
“Nessuno usa più questo oggetto?” GC esamina periodicamente l’heap, trova oggetti senza proprietario e li scarta. Grazie a questo, non dobbiamo scrivere il codice di rilascio della memoria.
Ma niente è gratis. Nel momento in cui il GC effettua la pulizia profonda, tutto il lavoro nel centro logistico si ferma per un momento (Stop-the-world). Questo tempo di pulizia è il motivo per cui il gioco rallenta improvvisamente o il server si blocca per circa un secondo.
Conclusione: occhi che vedono l’invisibile
Dopo aver compreso lo stack e l’heap, il codice sul mio monitor ha iniziato ad apparire diverso. In passato, quando guardavo il codice new Student(), pensavo semplicemente: “Ho creato un oggetto”. Ma ora posso vederlo.
“Una scatola è ora entrata nel magazzino chiamato Heap. Se non la elimino (o se GC non arriva), continuerà a divorare memoria.”
Dopo aver acquisito “occhi per vedere l’invisibile”, sono riuscito a liberarmi da vaghe paure. Anche se il server sputa OutOfMemory, non mi faccio prendere dal panico e premo il pulsante di riavvio come facevo prima. Invece, attiva lo strumento di analisi e chiedi con calma: “Quale oggetto occupa l’heap?” Questo perché se conosci la causa, puoi risolverla.
Abbiamo ora conquistato lo spazio (memoria) in cui è memorizzato il codice. Il magazzino è completamente preparato. Allora chi sono i “lavoratori” che effettivamente trasportano e assemblano gli articoli in questo magazzino? Qual è la differenza tra lavorare da soli e lavorare con più persone contemporaneamente (multitasking)?
La prossima volta andiamo nel mondo di “Process & Thread”, il fiore all’occhiello del sistema operativo e l’eterno compito degli sviluppatori back-end.