Maschinen können kein Englisch
Als ich an der Uni zum ersten Mal C lernte, gab es etwas, das ich absolut nicht verstand. ‚Warum wird mein Code nicht sofort ausgeführt, sondern muss diesen lästigen Prozess von Build und Kompilierung durchlaufen?‘
Bei Python tippte ich Code, drückte Enter, und er lief. Aber bei Java oder C war immer dieser zeitraubende Zwischenschritt nötig. Während des Studiums tat ich das einfach ab mit: ‚Jede Sprache hat halt ihre eigene Grammatik.‘ Wenn es in der Klausur vorkam, schrieb ich einfach die Musterantwort: ‚C ist eine kompilierte Sprache, Python eine interpretierte Sprache.‘
Aber als ich in der Praxis Backend-Server mit hohem Traffic verwaltete, wurde mir klar, dass dieser simple Unterschied eine gewaltige Barriere ist, die über Systemleistung und Deployment-Geschwindigkeit entscheidet. Der elegante Code, den ich schrieb, war für den CPU – diesen dummen, aber fleißigen Arbeiter – eigentlich nur unverständliches Alien-Kauderwelsch.

Was ist eigentlich ein ‚Build‘?
Was genau ist also ein ‚Build‘? Wie unterscheidet es sich vom bloßen „Speichern“? Der Quellcode (.java, .c), den wir schreiben, ist eigentlich nur eine ‚Textdatei‘. Ein Stück ‚Schrift‘, das man auch mit dem Notepad lesen kann. Aber der Computer (CPU) kann nicht lesen. Er versteht nur: Strom an (1) oder Strom aus (0).
Der ‚Build‘ ist ein ‚umfassender Verpackungsprozess‘, der unsere ‚Textdatei‘ in eine ‚ausführbare Datei‘ (.exe, .class, .jar) umwandelt, die der Computer versteht.
- Präprozessor (Preprocessing): Kommentare werden entfernt, notwendige Bibliotheks-Codes werden importiert und angefügt.
- Kompilierung (Compilation): Der englische Code wird in Maschinensprache (oder Bytecode) übersetzt.
- Linking: Mehrere übersetzte Dateien werden zu einer finalen ausführbaren Datei gebündelt.
Kurz gesagt: ‚Wenn der Quellcode das Rezept (Papier) ist, dann ist der Build der Prozess, bei dem die Zutaten nach diesem Rezept geschnitten, gekocht und als fertiges Gericht serviert werden.‘ Egal wie oft man das Rezept (Code) korrigiert, solange man nicht neu kocht (Build), steht auf dem Esstisch (Server) immer noch das kalte Essen von gestern.
Das Arbeitsblatt im digitalen Logistikzentrum
Um diesen komplexen Prozess zu verstehen, vergleichen wir das Innere des Computers mit einem riesigen ‚digitalen Logistikzentrum‘. Hier ist der ‚CPU‘ ein unglaublich flinker, aber völlig unflexibler ‚Arbeiter‘. Dieser Arbeiter kann nur Arbeitsanweisungen lesen, die in ‚Maschinensprache (0 und 1)‘ verfasst sind.
Wenn wir Code in Java oder Python schreiben, erstellen wir ein ‚Arbeitshandbuch‘ für diesen Arbeiter. Das Problem ist nur: Wir schreiben dieses Handbuch auf Englisch (Programmiersprache). Der Arbeiter kann aber kein Englisch. Deshalb brauchen wir einen ‚Übersetzer‘. Je nach Übersetzungsmethode ändert sich das Schicksal der Sprache.
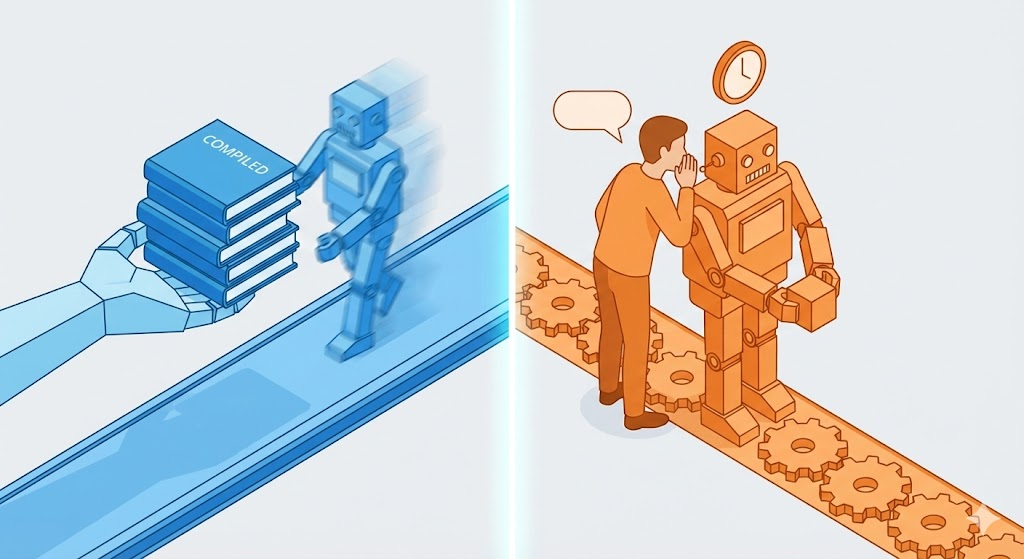
1. Compiler: Der professionelle Vorab-Übersetzer
- Repräsentative Sprachen: C, C++, Java (Hybrid), Go, Rust
- Methode: Es ist, als würde man ein ganzes Buch komplett übersetzen und dann veröffentlichen. Bevor die Arbeit beginnt, wird der gesamte Code in Maschinensprache umgewandelt und eine ausführbare Datei (.exe, .class) erstellt.
- Vorteil: Da alles vorab übersetzt wurde, liest der Arbeiter (CPU) extrem schnell. Grammatikfehler werden schon vor der Ausführung gefangen.
- Nachteil: Selbst wenn man nur eine Zeile im Handbuch ändert, muss das ganze Buch neu gedruckt (Re-build) werden.
2. Interpreter: Der Echtzeit-Simultandolmetscher
- Repräsentative Sprachen: Python, JavaScript, Ruby
- Methode: Er steht direkt neben dem Arbeiter, liest Satz für Satz und übersetzt sofort.
- Vorteil: Änderungen im Handbuch werden sofort reflektiert. Es ist keine separate Übersetzungsdatei nötig.
- Nachteil: Da das Dolmetschen Zeit kostet, ist das Arbeitstempo langsamer. Man merkt erst, dass auf der letzten Seite ein Tippfehler ist, wenn man dort ankommt.
[Code Verification] Das wahre Gesicht der Maschinensprache
Nur darüber zu hören, macht es noch nicht greifbar. Prüfen wir mit eigenen Augen, ob Python wirklich Zeile für Zeile übersetzt und wie der Code aussieht, den die Maschine sieht. In Python gibt es ein Modul namens dis (Disassembler). Damit können wir sehen, in welche Befehle der Python-Code intern zerlegt wird, wenn er ausgeführt wird.
import dis
def my_function():
a = 10
b = 20
print(a + b)
# Wir prüfen, in welchen Maschinencode (Bytecode) der Python-Code umgewandelt wird
print("--- Python Bytecode Verification ---")
dis.dis(my_function)
Wenn man diesen Code ausführt, wird folgende Alien-Sprache ausgegeben:
5 0 LOAD_CONST 1 (10)
2 STORE_FAST 0 (a)
6 4 LOAD_CONST 2 (20)
6 STORE_FAST 1 (b)
7 8 LOAD_GLOBAL 0 (print)
10 LOAD_FAST 0 (a)
12 LOAD_FAST 1 (b)
14 BINARY_ADD
16 CALL_FUNCTION 1
18 POP_TOP
20 LOAD_CONST 0 (None)
22 RETURN_VALUE
Analyse:
- Unser
a = 10wurde in zwei Befehle zerlegt:LOAD_CONST(Hole Konstante 10) undSTORE_FAST(Lege sie in den schnellen Speicher a). - Um
print(a + b)auszuführen, werdenBINARY_ADD(Binäre Addition) undCALL_FUNCTION(Funktionsaufruf) durchgeführt.
Der Python-Interpreter liest diese Befehle zur Laufzeit (Runtime) einen nach dem anderen und führt die interne Logik aus, die in C geschrieben ist. Das heißt: ‚Wir befehlen nicht direkt dem CPU, sondern wir befehlen einer virtuellen Maschine (VM), die sich mit dem CPU unterhält.‘ Das ist der Grund, warum Python langsamer ist als C.
Im Gegensatz dazu wird C direkt in echte CPU-Assembly-Befehle wie MOV EAX, 10 (Schiebe 10 in das EAX-Register) übersetzt. Da es keinen Mittelsmann gibt, ist es zwangsläufig schnell.
Trade-off in der Praxis: Was soll ich wählen?
Im Studium war Bequemlichkeit das Wichtigste. Ich mochte Python oder JavaScript, die auch liefen, wenn man sie schlampig schrieb, lieber als C, das ständig Compiler-Fehler warf. Aber in der Praxis muss man einen harten Kompromiss (Trade-off) zwischen ‚Stabilität‘ und ‚Produktivität‘ finden.
1. Der Horror des Runtime Errors (Schwäche des Interpreters)
Das Erschreckendste an einem Python-Server ist, dass er nachts um 3 Uhr wegen eines einzigen Tippfehlers stehen bleiben kann. Der Interpreter kennt den Fehler nicht, bevor er nicht versucht, ihn auszuführen (also genau zu dem Zeitpunkt, wenn der Code läuft). Java (kompilierte Sprache) hingegen sagt schon beim Build: „Hey, hier ist ein Tippfehler!“ Diese ‚Strenge‘, die Fehler vor dem Deployment abfängt, ist bei Großprojekten ein Retter.
2. Die Langeweile der Build-Zeit (Schwäche des Compilers)
Andererseits kann es bei großen Java-Projekten Minuten dauern, nur um eine geänderte Zeile zu überprüfen (Gradle Build…). Das ist der Grund, warum Python in der frühen Phase von Startups, wo schnelle Anpassungen und Deployments überlebenswichtig sind, oder in der Datenanalyse, wo man Ergebnisse sofort sehen muss, überwältigend oft genutzt wird.
Fazit: Theorie wird zur Waffe
Wir haben nun den Prozess von ‚Build und Kompilierung‘ verstanden und wissen, dass Sprachen Code unterschiedlich übersetzen. Theoretisch wäre es die richtige Antwort, die beste Sprache passend zur Natur des Projekts zu wählen.
‚Aber die Realität war nicht so freundlich.‘
Das Unternehmen, dem ich beitrat, hatte bereits einen festen Tech-Stack. Ich kam als Java-Entwickler, musste aber Python, JavaScript und sogar Android XML anfassen. In diesem chaotischen Feld der ‚Omnivoren-Entwicklung‘ war es paradoxerweise diese ‚Basistheorie‘, die mich rettete. Denn auch wenn die Hülle der Sprache anders ist, sind die Prinzipien, die im Inneren ablaufen, dieselben.
Im nächsten Teil werde ich meine Praxiserfahrung teilen, wie ich ‚eine Sprache (Java) tief gegraben habe, um andere Sprachen zu erobern‘, und warum die Grundlagen so wichtig sind, um nicht zum Sklaven von Frameworks zu werden.