La machine ne parle pas anglais
Lorsque j’ai commencé à apprendre le C à l’école, il y avait une chose que je ne comprenais pas du tout. ‘Pourquoi mon code ne s’exécute-t-il pas immédiatement ? Pourquoi dois-je passer par ces étapes ennuyeuses de Build et de Compilation ?’
Avec Python, il suffisait d’écrire le code, d’appuyer sur Entrée, et ça marchait. Mais avec Java ou C, il fallait toujours ce temps d’attente. À l’époque, je me disais simplement : ‘C’est juste que la syntaxe est différente’, et je passais à autre chose. Pour les examens, il suffisait de cocher la case : ‘C est un langage compilé, Python est un langage interprété’, et j’avais la note.
Cependant, en gérant des serveurs backend traitant un trafic massif, j’ai réalisé que cette simple différence est en réalité un mur gigantesque qui détermine la performance du système et la vitesse de déploiement. Le code élégant que j’écris n’est, pour le CPU (cet ouvrier musclé mais très terre-à-terre), qu’un charabia extraterrestre incompréhensible.

C’est quoi un ‘Build’, à la fin ?
Alors, qu’est-ce que le ‘Build’ exactement ? En quoi est-ce différent d’une simple ‘Sauvegarde’ (Save) ?
Le code source que nous écrivons (.java, .c) n’est rien d’autre qu’un ‘fichier texte’. C’est de l’écrit, lisible avec un simple bloc-notes. Mais l’ordinateur (le CPU) ne sait pas lire. Il ne comprend que deux états : le courant passe (1) ou ne passe pas (0).
Le ‘Build’ est un ‘processus d’emballage complet’ qui transforme notre ‘fichier texte’ en un ‘fichier exécutable’ (.exe, .class, .jar) que l’ordinateur peut comprendre.
- Préprocessing (Preprocessing) : On supprime les commentaires et on importe les codes des bibliothèques nécessaires.
- Compilation : On traduit le code anglais en langage machine (ou bytecode).
- Linking (Édition de liens) : On rassemble plusieurs fichiers traduits pour en faire un seul fichier exécutable final.
En résumé : ‘Si le code source est la recette de cuisine (papier), le Build est le processus de préparation et de cuisson des ingrédients pour servir le plat final (nourriture).’ Peu importe combien vous modifiez la recette (le code), si vous ne cuisinez pas à nouveau (Build), c’est le plat froid d’hier qui reste sur la table (le serveur).
L’ordre de travail dans le Centre Logistique Numérique
Pour comprendre ce processus complexe, reprenons notre métaphore du ‘Centre Logistique Numérique’.
Ici, le ‘CPU’ est un ‘Ouvrier’ incroyablement rapide de ses mains, mais avec une flexibilité de zéro. Cet ouvrier ne sait lire que des ordres de travail en ‘Langage Machine (0 et 1)’.
Écrire du code en Java ou Python revient à rédiger le ‘Manuel de procédure’ pour cet ouvrier. Le problème, c’est que nous écrivons ce manuel en anglais (langage de programmation). L’ouvrier ne parle pas anglais. Nous avons donc besoin d’un ‘Traducteur’. Le destin du langage dépend de la méthode de traduction choisie.
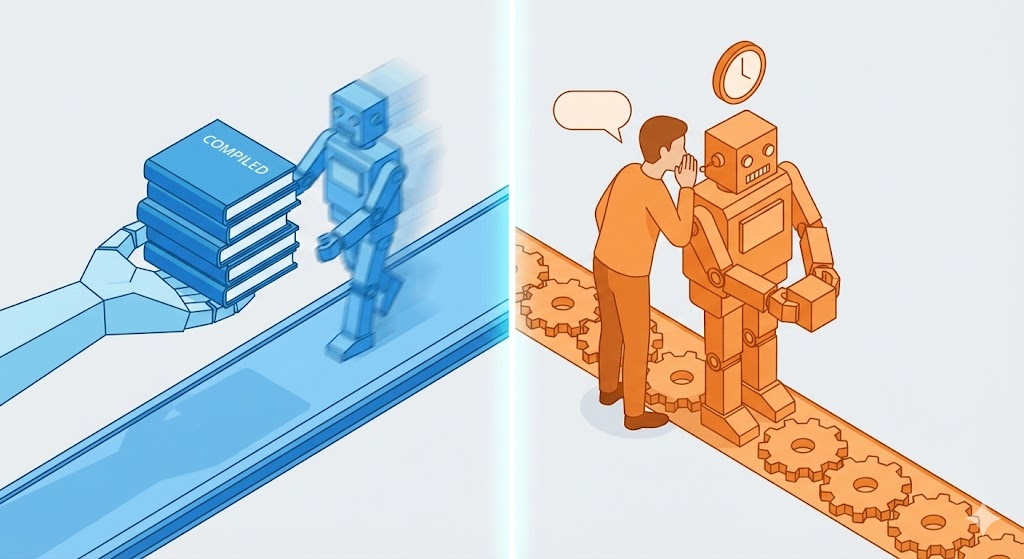
1. Le Compilateur : Le traducteur professionnel qui prépare tout à l’avance
- Langages représentatifs : C, C++, Java (Hybride), Go, Rust
- Méthode : C’est comme traduire un livre entier avant de le publier. Avant de commencer le travail, tout le code est transformé en langage machine pour créer un fichier exécutable (.exe, .class).
- Avantage : Comme c’est déjà traduit, la lecture par l’ouvrier (CPU) est extrêmement rapide. Les erreurs de grammaire sont détectées avant l’exécution.
- Inconvénient : Si vous corrigez une seule ligne du manuel, il faut réimprimer tout le livre (Re-build).
2. L’Interpréteur : L’interprète simultané
- Langages représentatifs : Python, JavaScript, Ruby
- Méthode : Il se tient à côté de l’ouvrier, lit une phrase à la fois et la traduit immédiatement.
- Avantage : Les corrections du manuel sont prises en compte immédiatement. Pas besoin de fichier de traduction séparé.
- Inconvénient : Le temps de traduction ralentit le travail. On ne découvre les fautes de frappe à la fin du manuel qu’au moment où l’on arrive à cette page.
[Code Verification] Voir le visage nu du langage machine
Les mots ne suffisent pas. Vérifions de nos propres yeux si Python traduit vraiment ligne par ligne et à quoi ressemble le code vu par la machine.
Python possède un module appelé dis (Disassembler). Il permet de voir en quelles commandes internes le code Python est découpé lors de l’exécution.
import dis
def my_function():
a = 10
b = 20
print(a + b)
# Vérification du Bytecode généré par Python
print("--- Python Bytecode Verification ---")
dis.dis(my_function)
Si vous exécutez ce code, vous verrez apparaître un langage extraterrestre comme celui-ci :
5 0 LOAD_CONST 1 (10)
2 STORE_FAST 0 (a)
6 4 LOAD_CONST 2 (20)
6 STORE_FAST 1 (b)
7 8 LOAD_GLOBAL 0 (print)
10 LOAD_FAST 0 (a)
12 LOAD_FAST 1 (b)
14 BINARY_ADD
16 CALL_FUNCTION 1
18 POP_TOP
20 LOAD_CONST 0 (None)
22 RETURN_VALUE
Analyse :
- Notre
a = 10a été découpé en deux commandes :LOAD_CONST(Apporte la constante 10) etSTORE_FAST(Mets-la dans le stockage rapide a). - Pour faire
print(a + b), il exécuteBINARY_ADD(Addition binaire) etCALL_FUNCTION.
L’interpréteur Python lit ces commandes une par une au moment de l’exécution (Runtime) et fait tourner sa logique interne écrite en C. En d’autres termes, ‘on ne donne pas d’ordres directs au CPU, on donne des ordres à une Machine Virtuelle (VM) qui discute avec le CPU’. C’est pour cela que Python est plus lent que C.
À l’inverse, le C une fois compilé est traduit directement en assembleur CPU réel comme MOV EAX, 10 (Mets 10 dans le registre EAX). Sans intermédiaire, c’est forcément plus rapide.
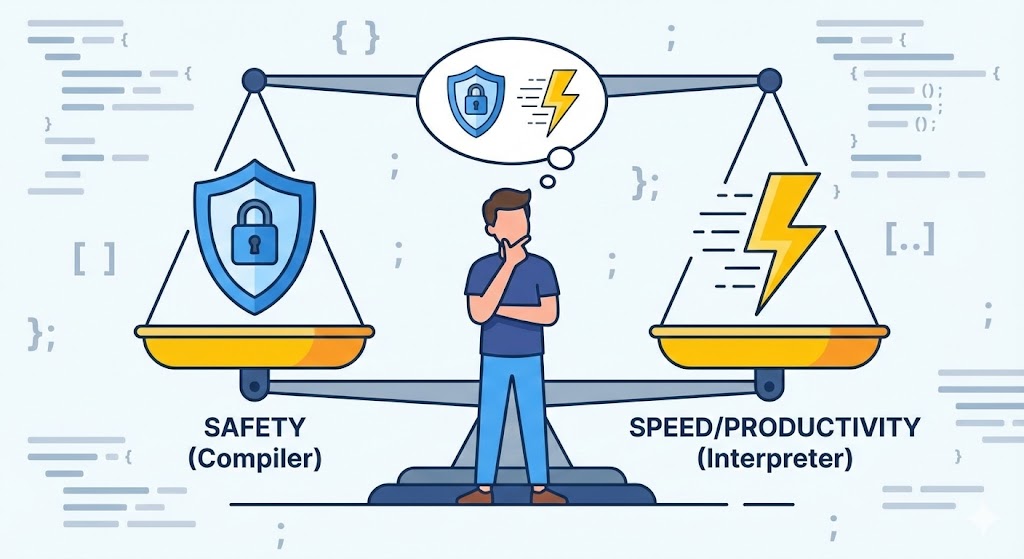
Le Trade-off en entreprise : Que choisir ?
À l’école, le confort était roi. Je préférais Python ou JavaScript qui fonctionnaient même codés à la va-vite, plutôt que le C et ses erreurs de compilation. Mais en entreprise, il faut faire un choix difficile (Trade-off) entre ‘Stabilité’ et ‘Productivité’.
1. La peur de l’erreur Runtime (Faiblesse de l’Interpréteur)
Le plus effrayant avec un serveur en Python, c’est que le serveur peut s’arrêter à 3h du matin à cause d’une simple faute de frappe. L’interpréteur ne connaît l’erreur qu’au moment où il essaie d’exécuter la ligne. À l’inverse, Java (langage compilé) vous avertit : « Hé, il y a une coquille ici ! » dès le Build. Cette ‘rigueur’ qui attrape les erreurs avant le déploiement est un sauveur pour les gros projets.
2. L’ennui du temps de Build (Faiblesse du Compilateur)
D’un autre côté, quand un projet Java grossit, corriger une seule ligne et vérifier le résultat peut prendre plusieurs minutes (Gradle Build…). C’est pourquoi Python est massivement utilisé dans les startups en phase initiale où la vitesse de modification et de déploiement est vitale, ou dans l’analyse de données où l’on doit voir les résultats immédiatement.
Conclusion : La théorie est une arme
Nous connaissons maintenant le processus de ‘Build et Compilation’, et comment chaque langage traduit le code différemment. En théorie, la bonne réponse serait de choisir le meilleur langage adapté à la nature de mon projet.
‘Mais la réalité n’a pas été aussi clémente.’
L’entreprise où je suis entré avait déjà sa stack technique, et bien qu’embauché comme développeur Java, j’ai dû toucher à Python, JavaScript, et même au XML d’Android.
Dans ce chaos du ‘développement omnivore’, ce qui m’a sauvé, c’est paradoxalement cette ‘théorie de base’ apprise aujourd’hui. L’enveloppe du langage change, mais les principes qui tournent à l’intérieur restent les mêmes.
La prochaine fois, je vous raconterai comment j’ai ‘creusé un seul langage (Java) pour mieux conquérir les autres’, et pourquoi les bases sont essentielles pour ne pas devenir esclave des frameworks.