
面接用「1分自己紹介」のような知識
「プロセスとスレッドの違いは何ですか?」
就職活動(就活)時代、この質問は「面接頻出質問TOP10」に必ず入っていた。僕は機械のように答えた。
「プロセスは実行中のプログラムであり、スレッドはプロセス内で実行される処理の単位です。プロセスはリソースを共有しませんが、スレッドはリソースを共有します」
面接官は頷き、僕は自分がこの概念を完璧に理解したと勘違いした。しかし実務で**「並行性(Concurrency)の問題」**に直面するまで、あの文章が内包する本当の恐ろしさを全く分かっていなかった。
「なぜ閲覧数が100増えるはずなのに、98しか増えないんだ?」 「なぜExcelダウンロードを実行すると、Webサイト全体が止まるんだ?」
僕のコードは一人で動かす時は完璧だったが、複数のユーザーが同時に入ってくると滅茶苦茶になった。僕はただ「作業員」を増やせば解決すると思っていたが、作業員が増えるほど彼らを管理するコスト(Context Switching)が幾何級数的に増えるという事実を知らなかったのだ。

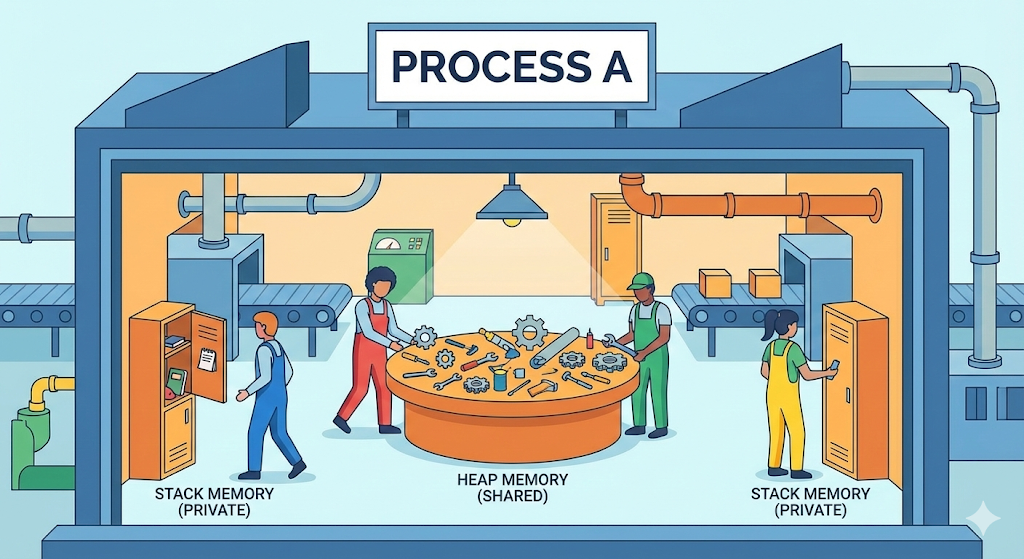
デジタル物流センターの工場と作業員
我々の「デジタル物流センター」の世界観に戻ってみよう。 コンピュータの中でプログラムが実行されるということは、物流センターの中に「作業場(Factory)」を一つ構えることと同じだ。
1. プロセス (Process):独立した作業場
- 定義:OS(工場長)からリソースを割り当てられた「独立した作業単位」。
- 特徴:それぞれ独自の建物を持っている。隣の工場が崩壊しても(エラー)、自分の工場は安全だ。
- コスト:工場を一つ建てるには土地(メモリ)も必要だし、事業者登録(PID)もしなければならない。「高くて重い」。
- 共有:原則として隣の工場の物は持ってこれない。(IPCという複雑な通信を使わなければならない)
2. スレッド (Thread):作業場の中の作業員たち
- 定義:プロセス(作業場)の中で実際に仕事をする「作業員」。
- 特徴:一つの工場に作業員が何人もいることができる(マルチスレッド)。
- コスト:新しい作業員を雇うのは、工場を新築するよりはるかに「安くて軽い」。
- 共有:これが核心だ。作業員たちは「食堂(Heap)と休憩室(Data)」を一緒に使う。
[Code Verification] 共有の悲劇(並行性問題)
「スレッドはリソースを共有する」 この言葉が面接会場ではメリットのように聞こえたが、実務では「災い」の種になり得る。
前回学んだ「ヒープ(Heap)」を覚えているだろうか? スレッドたちはこのヒープ領域を共有する。つまり、Aスレッドが作業中のデータを、Bスレッドが来て上書きできるという意味だ。
これを「競合状態(Race Condition)」という。コードで確認してみよう。
public class RaceConditionTest {
static int count = 0; // ヒープ(Heap)に保存される共有変数
public static void main(String[] args) throws InterruptedException {
// 作業員(スレッド)二人を雇用
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) count++;
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) count++;
});
t1.start(); // 作業開始!
t2.start(); // 作業開始!
t1.join(); // 退勤するまで待機
t2.join(); // 退勤するまで待機
System.out.println("最終結果: " + count);
}
}
- 予想結果:10,000回ずつ二人が足したのだから、20,000が出るはずだ。
- 実際結果:15,482、18,931… 実行するたびに値が変わり、20,000が出ない。
理由:
- スレッドAがヒープから
count(100)を読んでスタックに持ってくる。 - その間にスレッドBもヒープから
count(100)を読んでいく。 - Aが
101にしてヒープに保存する。 - Bも(自分が読んだのが100だったので)
101にしてヒープに保存する。 - 二回足したのに、結果は一回しか足していないことになる。
これが実務で「たまにデータが飛ぶ(整合性が合わない)」バグの正体だ。作業員同士が会話なしに同じ帳簿をいじったせいで起きた悲劇だ。
この状況をデータベース(DB)に例えるなら、「トランザクション(Transaction)なしで複数のクエリが同時に飛んでくる状況」と同じだ。保護装置(Lock)なしに通帳残高を同時に修正するから、お金が蒸発してしまう恐ろしい事故が起きるのだ。我々がDBで ROLLBACK や COMMIT でデータを守るように、コードレベルでも Synchronized のようなロック装置が必ず必要になる。
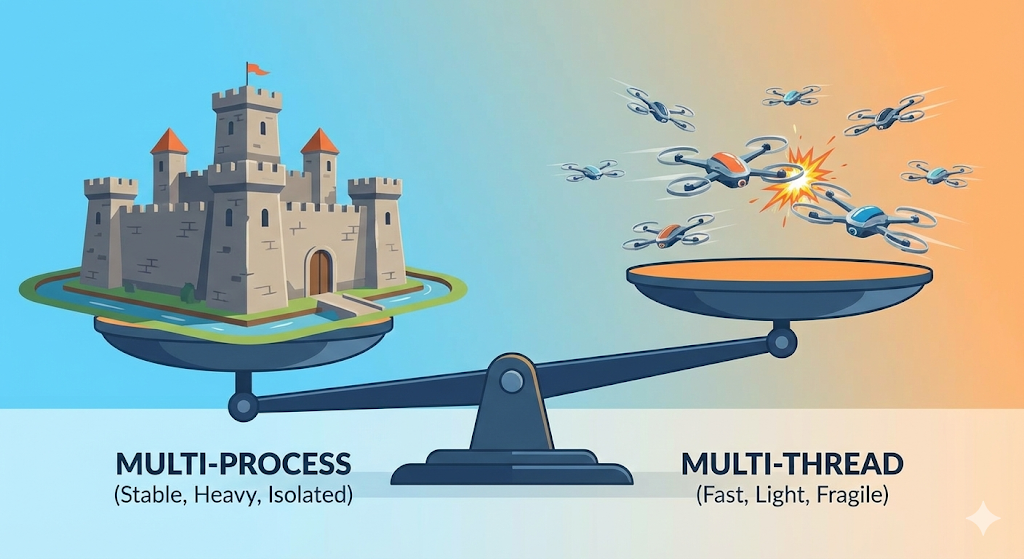
実務でのTrade-off:マルチプロセス vs マルチスレッド
では、実務ではいつ何を使うべきか?
1. Chromeブラウザの選択:マルチプロセス
昔のInternet Explorerは、タブ一つが止まるとブラウザ全体が落ちた(マルチスレッド方式)。しかしChromeはタブ一つ一つを「別のプロセス(工場)」として立ち上げる。
- メリット:タブ一つがフリーズしても(工場が爆発しても)、他のタブ(隣の工場)は無事だ。(安定性)
- デメリット:メモリを食い散らかす。Chromeが「メモリ食い虫」になった理由だ。(コスト)
2. Webサーバー(Spring, Node.jsなど)の選択:マルチスレッド
サーバーは数千人のリクエストを処理しなければならない。リクエストごとにプロセス(工場)を建てていたらサーバーがパンクする。だから一つのプロセスの中に無数のスレッド(作業員)を置いて処理する。
- メリット:リソース消費が少なく速い。(効率性)
- デメリット:スレッド一つがエラーを出してプロセスを殺すと、サーバー全体が死ぬ。そしてさっき見た並行性問題を開発者が自ら防がなければならない(Synchronizedなど)。
終わりに:分身の術には責任が伴う
今日我々は、作業員たちの働き方である「プロセスとスレッド」を見てきた。
- プロセス:安全だが高い独立作業場。
- スレッド:軽くて速いが衝突の危険がある共同作業員。
これで「並行性の問題」という単語が、単なる面接用語ではないことが分かっただろう。ヒープ(Heap)という共有倉庫を、無数のスレッド作業員たちが休みなく出入りしている。この混乱の中で秩序を守るのがバックエンドエンジニアの実力だ。
ところで、作業員が増えたら誰の仕事を先にやるべきか、どうやって決めるのだろうか? 工場長(OS)は数百人の作業員をどうやって管理しているのか?
次回は、工場長の最も頭の痛い業務、**「スケジューリングとコンテキストスイッチ (Context Switching)」**について話そう。