면접용 1분 자기소개 같은 지식
“프로세스와 스레드의 차이가 뭔가요?”
취업 준비생 시절, 이 질문은 ‘단골 면접 질문 TOP 10’ 안에 항상 들어있었다. 나는 기계처럼 대답했다.
“프로세스는 실행 중인 프로그램이고, 스레드는 프로세스 안에서 실행되는 흐름의 단위입니다. 프로세스는 자원을 공유하지 않지만, 스레드는 자원을 공유합니다.”
면접관은 고개를 끄덕였고, 나는 내가 이 개념을 완벽하게 이해했다고 착각했다. 하지만 실무에서 ‘동시성 이슈(Concurrency Issue)’를 맞닥뜨리기 전까지, 저 문장이 내포한 진짜 무서움을 전혀 알지 못했다.
“왜 조회수가 100씩 올라가야 하는데 98밖에 안 올라가지?” “왜 엑셀 다운로드를 걸어놓으면 웹사이트가 멈추지?”
내 코드는 혼자 돌릴 땐 완벽했지만, 여러 사용자가 동시에 들어오자 엉망진창이 되었다. 나는 그저 ‘작업자’를 늘리면 해결될 줄 알았지만, 작업자가 늘어날수록 그들을 관리하는 비용(Context Switching)이 기하급수적으로 늘어난다는 사실을 몰랐던 것이다.

디지털 물류 센터의 공장과 작업자
우리의 ‘디지털 물류 센터’ 세계관으로 돌아와 보자. 컴퓨터 안에서 프로그램이 실행된다는 건, 물류 센터 안에 ‘작업장(Factory)’을 하나 차리는 것과 같다.
1. 프로세스(Process): 독립된 작업장
- 정의: 운영체제(공장장)로부터 자원을 할당받은 ‘독립된 작업 단위’.
- 특징: 각자 건물이 따로 있다. 옆 공장이 무너져도(에러) 내 공장은 안전하다.
- 비용: 공장을 하나 지으려면 땅(메모리)도 필요하고, 사업자 등록(PID)도 해야 한다. ‘비싸고 무겁다.’
- 공유: 원칙적으로 옆 공장 물건을 가져올 수 없다. (IPC라는 복잡한 통신을 써야 함)
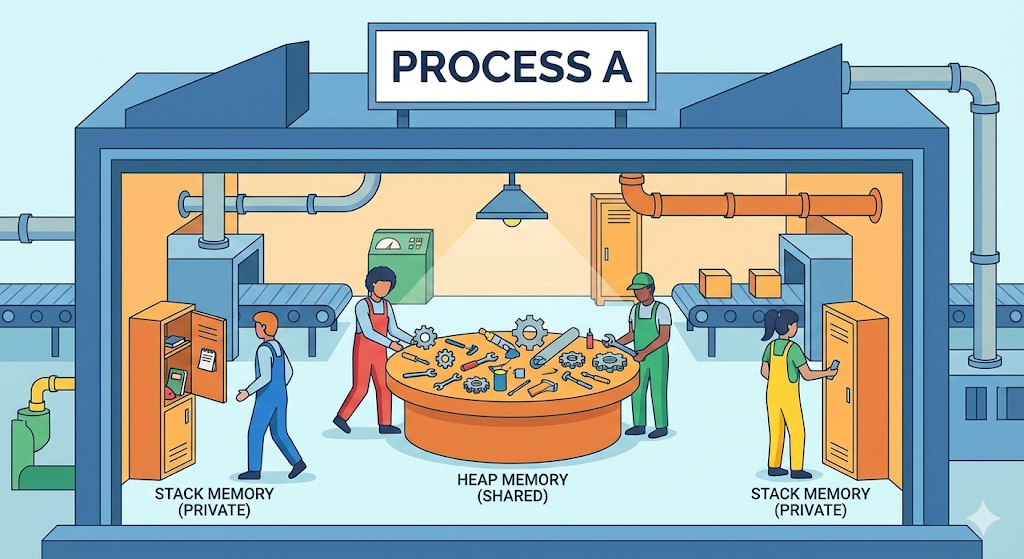
2. 스레드(Thread): 작업장 안의 일꾼들
- 정의: 프로세스(작업장) 안에서 실제로 일을 하는 ‘작업자’.
- 특징: 공장 하나에 일꾼이 여러 명 있을 수 있다(멀티 스레드).
- 비용: 새로운 일꾼을 고용하는 건 공장을 새로 짓는 것보다 훨씬 ‘싸고 가볍다.’
- 공유: 이게 핵심이다. 일꾼들은 ‘식당(Heap)과 휴게실(Data)’을 같이 쓴다.
[Code Verification] 공유의 비극 (동시성 문제)
“스레드는 자원을 공유한다.” 이 말이 면접장에서는 장점처럼 들렸지만, 실무에서는 ‘재앙’의 씨앗이 될 수 있다.
우리가 지난 시간에 배운 ‘힙(Heap)’ 기억나는가? 스레드들은 이 힙 영역을 공유한다. 즉, A 스레드가 작업 중인 데이터를 B 스레드가 와서 덮어쓸 수 있다는 뜻이다.
이걸 ‘경쟁 상태(Race Condition)’라고 한다. 코드로 확인해보자.
public class RaceConditionTest {
static int count = 0; // 힙(Heap)에 저장되는 공유 변수
public static void main(String[] args) throws InterruptedException {
// 작업자(스레드) 두 명 고용
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) count++;
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) count++;
});
t1.start(); // 작업 시작!
t2.start(); // 작업 시작!
t1.join(); // 퇴근할 때까지 대기
t2.join(); // 퇴근할 때까지 대기
System.out.println("최종 결과: " + count);
}
}
예상 결과: 10,000번씩 두 명이 더했으니 20,000이 나와야 한다.
실제 결과: 15,482, 18,931… 실행할 때마다 값이 다르고, 20,000이 안 나온다.
이유:
- 스레드 A가 힙에서
count(100)을 읽어서 스택으로 가져온다. - 그 사이에 스레드 B도 힙에서
count(100)을 읽어간다. - A가 101로 만들어서 힙에 저장한다.
- B도 (자기가 읽은 게 100이었으니) 101로 만들어서 힙에 저장한다.
- 두 번 더했는데 결과는 한 번만 더한 꼴이 된다.
이것이 실무에서 “가끔 데이터가 씹히는” 버그의 정체다. 작업자들이 서로 대화 없이 같은 장부를 건드려서 생긴 비극이다.
이 상황을 데이터베이스(DB)로 비유하자면, ‘트랜잭션(Transaction) 없이 여러 쿼리가 동시에 날아가는 상황’과 똑같다. 보호 장치(Lock) 없이 통장 잔고를 동시에 수정하니, 돈이 증발해버리는 끔찍한 사고가 터지는 것이다. 우리가 DB에서 ROLLBACK이나 COMMIT으로 데이터를 보호하듯, 코드 레벨에서도 Synchronized 같은 잠금 장치가 반드시 필요하다.
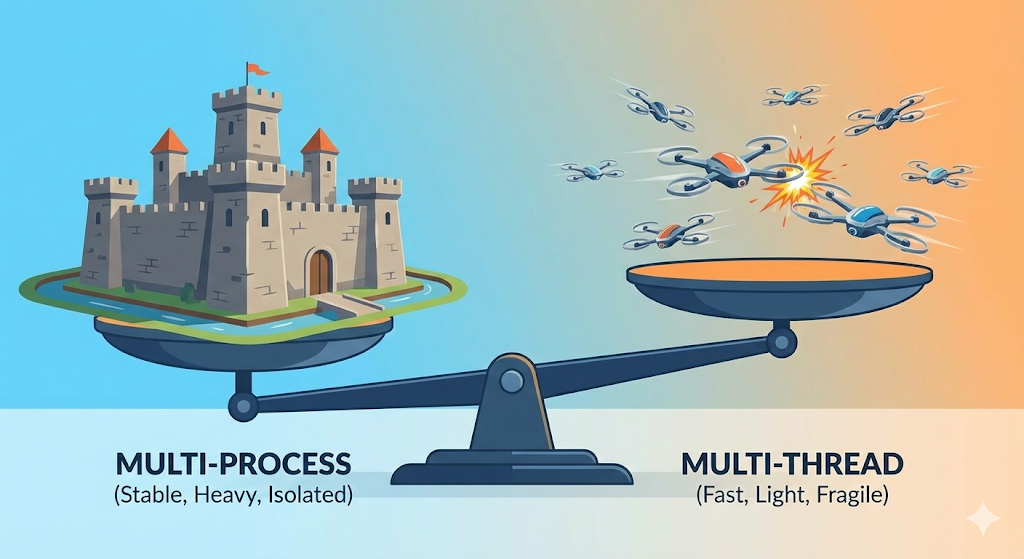
실무에서의 Trade-off: 멀티 프로세스 vs 멀티 스레드
그렇다면 실무에서는 언제 무엇을 써야 할까?
1. 크롬(Chrome) 브라우저의 선택: 멀티 프로세스
옛날 인터넷 익스플로러는 탭 하나가 멈추면 브라우저 전체가 꺼졌다(멀티 스레드 방식). 하지만 크롬은 탭 하나하나를 ‘별도의 프로세스(공장)’로 띄운다.
- 장점: 탭 하나가 먹통이 되어도(공장이 폭파돼도), 다른 탭(옆 공장)은 멀쩡하다. (안정성)
- 단점: 메모리를 엄청나게 잡아먹는다. 크롬이 ‘램 먹는 하마’가 된 이유다. (비용)
2. 웹 서버(Spring, Node.js 등)의 선택: 멀티 스레드
서버는 수천 명의 요청을 처리해야 한다. 요청마다 프로세스(공장)를 지으면 서버가 터진다. 그래서 하나의 프로세스 안에 수많은 스레드(일꾼)를 둬서 처리한다.
- 장점: 자원을 적게 쓰고 빠르다. (효율성)
- 단점: 스레드 하나가 에러를 내서 프로세스를 죽이면 서버 전체가 죽는다. 그리고 아까 본 동시성 이슈를 개발자가 직접 막아야 한다(Synchronized).
마치며: 분신술에는 책임이 따른다
오늘 우리는 작업자들의 작업 방식인 ‘프로세스와 스레드’를 살펴봤다.
- 프로세스: 안전하지만 비싼 독립 작업장.
- 스레드: 가볍고 빠르지만 충돌 위험이 있는 공동 작업자.
이제 ‘동시성 이슈’라는 단어가 단순히 면접용 용어가 아니라는 것을 알았을 것이다. 힙(Heap)이라는 공유 창고를 수많은 스레드 일꾼들이 쉴 새 없이 드나들고 있다. 이 혼란 속에서 질서를 잡는 것이 백엔드 개발자의 실력이다.
그런데 잠깐, 일꾼들이 많아지면 누가 누구 일을 먼저 해야 할지 어떻게 정할까? 공장장(OS)은 수백 명의 일꾼을 어떻게 관리할까? 다음 시간에는 공장장의 가장 골치 아픈 업무, ‘스케줄링과 컨텍스트 스위칭(Context Switching)’에 대해 이야기해 보겠다.