A Máquina Não Fala Inglês (Nem Português)
Quando aprendi a linguagem C na faculdade, havia algo que simplesmente não entrava na minha cabeça: “Por que meu código não roda imediatamente? Por que tenho que passar por esse processo chato de ‘Build’ e ‘Compilação’?”
No Python, era só digitar o código, dar Enter e voilà, funcionava. Já no Java ou C, sempre existia aquela etapa que consumia tempo. Na época da graduação, eu apenas aceitava: “Ah, cada linguagem tem sua sintaxe”. Se caísse na prova, eu respondia mecanicamente: “C é compilado, Python é interpretado” e garantia a nota.
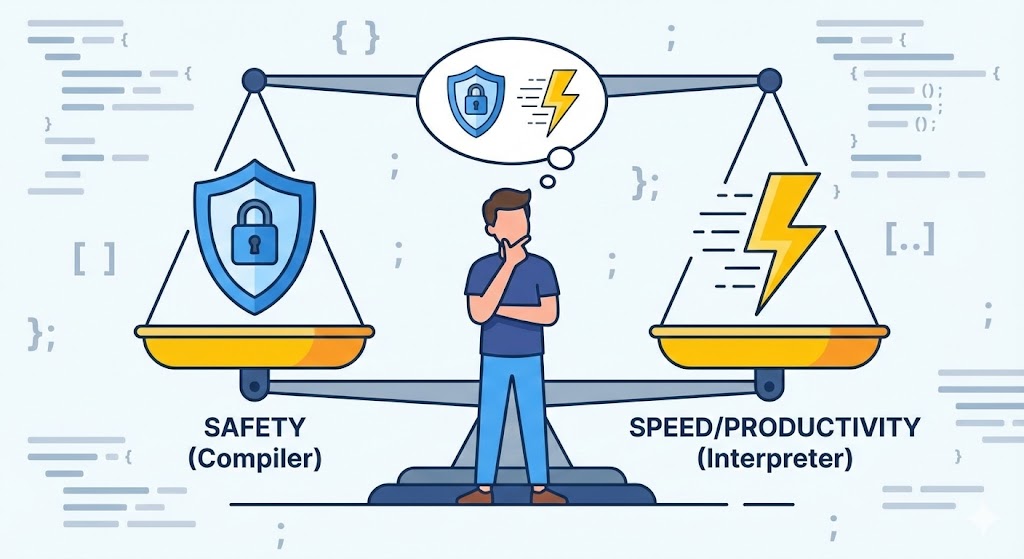
Mas, ao lidar com servidores Backend processando tráfego massivo no mundo real, percebi que essa “simples diferença” é uma barreira gigante que define a performance do sistema e a velocidade de deploy. O código elegante que escrevi, na verdade, não passa de um dialeto alienígena para a CPU, que é um operário extremamente rápido, mas totalmente sem flexibilidade.

Afinal, o que é esse tal de ‘Build’?
Então, o que é exatamente o ‘Build’? Qual a diferença entre isso e simplesmente “Salvar” (Ctrl+S)?
O código-fonte que escrevemos (.java, .c) nada mais é do que um arquivo de texto. É legível para nós se abrirmos no Bloco de Notas. Mas o computador (CPU) é analfabeto. Ele só entende sinais elétricos: passa corrente (1) ou não passa (0).
O ‘Build’ é um processo de empacotamento que transforma nosso ‘arquivo de texto’ em um ‘arquivo executável’ (.exe, .class, .jar) que o computador consegue rodar.
- Pré-processamento (Preprocessing): Remove comentários e cola os códigos das bibliotecas necessárias.
- Compilação (Compilation): Traduz o código de inglês/humano para linguagem de máquina (ou bytecode).
- Linkagem (Linking): Junta vários arquivos traduzidos em um único arquivo final.
Em resumo: Se o código-fonte é a receita (papel), o Build é o ato de cortar os ingredientes, cozinhar e servir o prato pronto (comida). Não importa o quanto você risque e corrija a receita (código); se você não cozinhar tudo de novo (Build), na mesa do cliente (servidor) continuará a comida fria de ontem.
O “Centro de Logística Digital” e a Ordem de Serviço
Para entender esse processo complexo, vamos usar a metáfora do nosso Centro de Logística Digital.
Aqui, a CPU é um Operário (Worker) com mãos incrivelmente rápidas, mas com zero criatividade. Esse operário só sabe ler uma coisa: “Ordens de Serviço em Código de Máquina (0 e 1)”.
Quando programamos em Java ou Python, estamos escrevendo o “Manual de Instruções” para esse operário. O problema é que escrevemos em inglês (linguagem de programação). O operário não fala inglês. Por isso, precisamos de um Tradutor. O destino da linguagem depende de como esse tradutor trabalha.
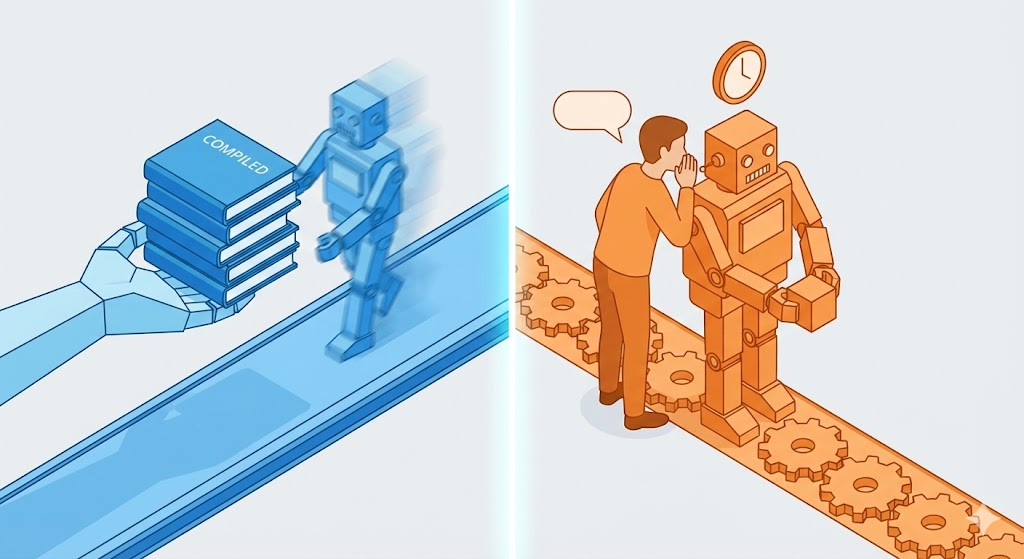
1. Compilador (Compiler): O Tradutor de Livros Profissional
- Linguagens: C, C++, Java (Híbrido), Go, Rust.
- Método: É como traduzir um livro inteiro e publicá-lo. Antes de começar o trabalho, ele traduz todo o código para linguagem de máquina e cria um arquivo executável (
.exe,.class). - Vantagem: Como já está tudo traduzido, o Operário (CPU) lê e executa muito rápido. Erros de sintaxe são pegos antes mesmo de tentar rodar.
- Desvantagem: Se você corrigir uma única vírgula no manual, precisa reimprimir (Re-build) o livro inteiro.
2. Interpretador (Interpreter): O Intérprete Simultâneo
- Linguagens: Python, JavaScript, Ruby.
- Método: Ele fica ao lado do Operário, lendo o manual linha por linha e traduzindo em tempo real.
- Vantagem: Mudou o manual, a mudança é imediata. Não precisa criar arquivos de tradução.
- Desvantagem: O tempo gasto traduzindo na hora deixa o trabalho mais lento. E você só descobre se tem um erro de digitação no final da página quando o intérprete chega lá.
[Code Verification] Vendo a “Cara” da Linguagem de Máquina
Falar é fácil, mostre o código. Vamos ver com os próprios olhos se o Python realmente traduz linha por linha e como é esse código que a máquina vê.
O Python tem um módulo chamado dis (Disassembler). Com ele, podemos ver como o código Python é fatiado em instruções internas.
import dis
def minha_funcao():
a = 10
b = 20
print(a + b)
# Verificando em qual bytecode o Python se transforma
print("--- Python Bytecode Verification ---")
dis.dis(minha_funcao)
Ao rodar isso, vemos uma saída que parece grego:
5 0 LOAD_CONST 1 (10)
2 STORE_FAST 0 (a)
6 4 LOAD_CONST 2 (20)
6 STORE_FAST 1 (b)
7 8 LOAD_GLOBAL 0 (print)
10 LOAD_FAST 0 (a)
12 LOAD_FAST 1 (b)
14 BINARY_ADD
16 CALL_FUNCTION 1
18 POP_TOP
20 LOAD_CONST 0 (None)
22 RETURN_VALUE
Análise:
- Onde escrevemos
a = 10, foi quebrado emLOAD_CONST(Carregue a constante 10) eSTORE_FAST(Armazene na memória rápida ‘a’). - Para fazer
print(a + b), ele chamaBINARY_ADD(Soma binária) eCALL_FUNCTION.
O Interpretador Python lê essas instruções uma a uma em tempo real e roda a lógica interna escrita em C. Ou seja, não estamos dando ordens diretas à CPU, mas sim a uma “Máquina Virtual” (VM) que conversa com a CPU. É por isso que Python é mais lento que C. Já em C, após compilar, isso viraria algo como MOV EAX, 10 (Assembly direto), falando cara a cara com o processador sem intermediários.
O Trade-off na Prática: Qual Escolher?
Na faculdade, o melhor era o que fosse mais cômodo. Eu preferia Python ou JavaScript, que rodavam mesmo escritos de qualquer jeito, do que o C e seus erros de compilação chatos. Mas no trabalho, enfrentamos um dilema (Trade-off) cruel entre Estabilidade e Produtividade.
1. O Terror do Runtime Error (A fraqueza do Interpretador)
O maior pesadelo ao usar Python no servidor é aquele erro de digitação bobo que faz o sistema cair às 3 da manhã. O interpretador não sabe do erro até chegar o momento exato de executar aquela linha. Já o Java (Compilado/Híbrido) é aquele professor rigoroso que grita: “Ei, tem um erro aqui!” durante o Build. Essa rigidez que impede o deploy de código quebrado é a salvação em grandes projetos.
2. O Tédio do Tempo de Build (A fraqueza do Compilador)
Por outro lado, em projetos Java gigantes, corrigir uma linha de código pode significar esperar minutos pelo Build (o famoso “hora do café” do Gradle…). É por isso que em Startups em fase inicial (que precisam de velocidade) ou em Ciência de Dados (que precisa ver resultados na hora), o Python domina.
Conclusão: Teoria é Arma
Agora sabemos que ‘Build e Compilação’ não são apenas botões mágicos, mas processos distintos de tradução. Teoricamente, a resposta certa seria escolher a melhor linguagem para o perfil do projeto.
“Mas a realidade não é tão gentil.”
A empresa onde entrei já tinha sua Stack definida. Entrei como dev Java, mas tive que mexer em Python, JavaScript e até XML de Android. Nesse caos de “Desenvolvimento Onívoro”, o que me salvou foi, ironicamente, essa teoria básica de hoje. A “casca” da linguagem muda, mas o princípio de como elas conversam com a máquina é o mesmo.
No próximo post, vou contar como mergulhar fundo em uma única linguagem (Java) me ajudou a dominar as outras, e por que a base é a única coisa que impede você de se tornar um escravo de Frameworks.