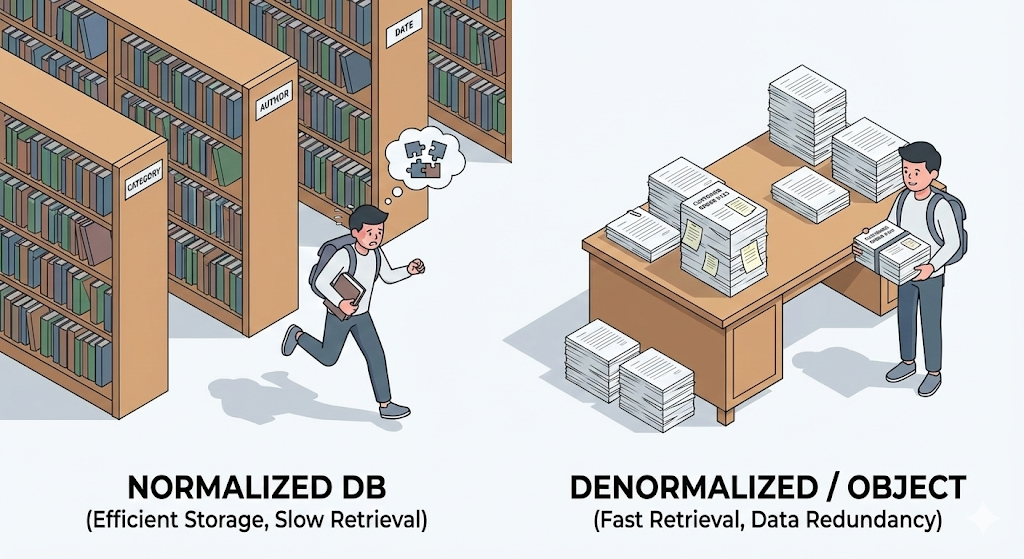
“Dubbele data is absoluut kwaad”
Tijdens de databasecolleges op de universiteit benadrukte de professor het zo fel dat het speeksel ervan afspatte. “Eerste normaalvorm, tweede normaalvorm, derde normaalvorm… dubbele data verspilt opslagruimte en tast de integriteit aan. Splits het op, en splits het daarna nog verder!”
Ik volgde die leer heel trouw. Voor mijn afstudeerproject splitste ik tabellen op in 10, daarna 20 stukjes. ‘User’, ‘Address’, ‘City’, ‘Zipcode’… Mijn databaseschema was zo perfect “volgens het boekje” dat je voor het opslaan van één enkel adres al drie tabellen nodig had.
Maar in de praktijk veranderde dat perfecte ontwerp in een ramp. Ik wilde gewoon één klantenlijst ophalen, en toch moest ik vijf JOINs schrijven. De query werd ingewikkeld, de snelheid zakte in, en nog erger: het overzetten van die data naar Java-objecten was ontzettend pijnlijk.
“Waarom is de code zo ingewikkeld terwijl ik gewoon één regel data wil ophalen om op het scherm te tonen?”
Pas toen besefte ik het echt. Op school leerden ze ons hoe je opslag efficiënt maakt. In de praktijk is efficiënt lezen veel belangrijker. En tussen een objectgeoriënteerde taal als Java en een relationele database stroomt een rivier die veel lastiger over te steken is dan je denkt.
Paradigmamismatch: vierkanten en cirkels
De fundamentele oorzaak van die pijn is wat we een paradigmamismatch noemen, ofwel Impedance Mismatch.
Tijdens mijn studie dwong ik deze twee werelden met geweld bij elkaar door SQL direct zelf te schrijven. Ik brak Java-objecten op om ze met INSERTs in de database te stoppen, haalde ze weer op met SELECT, las de rijen één voor één uit een ResultSet en stopte ze handmatig in Java-collecties zoals Set of List. Ik voelde me geen ontwikkelaar, maar een datavertaler.
De technologie die opdook om dat saaie, repetitieve werk op te lossen was precies JPA (Java Persistence API), oftewel de wereld van ORM (Object-Relational Mapping).
JPA en ORM: databases behandelen via objecten
ORM is letterlijk een techniek die objecten en relationele databases met elkaar verbindt. Zoals de naam al zegt, is het kernidee dat je databasetabellen definieert en gebruikt alsof het Java-objecten zijn.
We hoeven geen CREATE TABLE-query’s meer met de hand te schrijven. In plaats daarvan maken we een Java-klasse en plakken we daar een sticker op met de naam @Entity. Dan kijkt JPA, de ORM-standaard in Java, naar die klasse en denkt: “Aha, dus dit is de vorm van de tabel die je nodig hebt”, en maakt die automatisch aan in de database.
Ook bij het opslaan van data hoeven we geen SQL meer te schrijven. Een simpele repository.save(member) is genoeg, bijna alsof je iets toevoegt aan een Java-collectie. De ontwikkelaar blijft volledig in een objectgeoriënteerde denkwijze, terwijl het vieze werk van SQL-vertaling bij JPA wordt neergelegd.
Maar zoals we in de Re: Booting-serie hebben geleerd, heeft gemak altijd een prijs. En juist omdat ik die automatische vertaler genaamd JPA te veel vertrouwde, plantte ik een tijdbom in mijn code: het N+1-probleem.
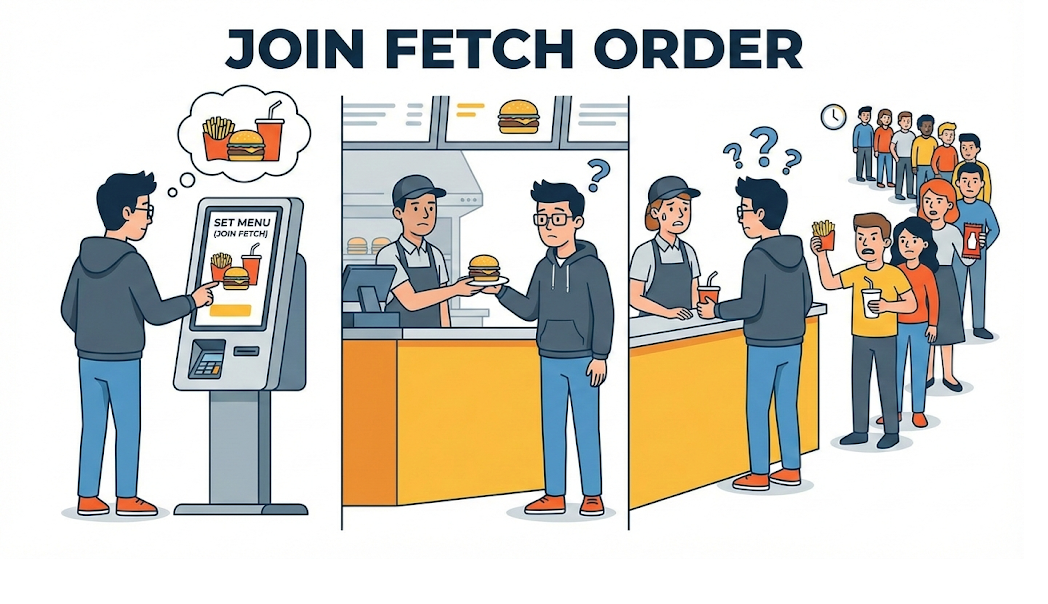
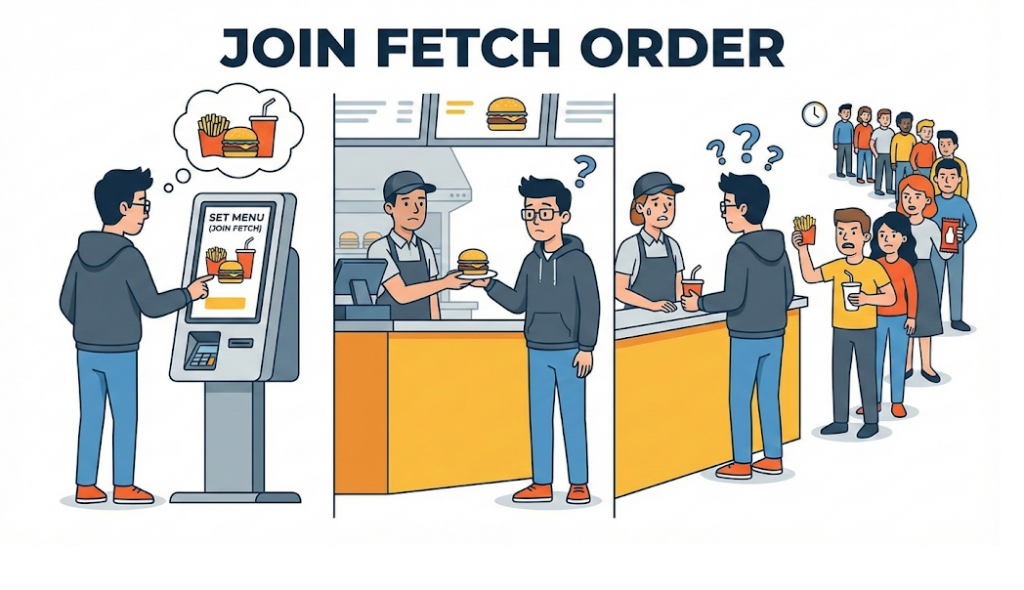
[Code Verification] Het N+1-probleem, een querybom
Dit is een probleem waar praktisch elke junior developer tegenaan loopt wanneer hij voor het eerst met JPA werkt. De situatie is eenvoudig: “Toon alle leden samen met de naam van het team waartoe ze behoren.”
// 1. Haal alle members op (1 query uitgevoerd)
List<Member> members = memberRepository.findAll();
for (Member member : members) {
// 2. Print de teamnaam van elk member
// Bij 100 members worden er 100 extra queries uitgevoerd voor teaminfo!
System.out.println(member.getTeam().getName());
}
De query die we verwachtten: SELECT * FROM Member JOIN Team ... (precies één keer)
De query die daadwerkelijk plaatsvond:
Als er 100 leden zijn, gaan er 101 queries uit: 1 + N. En als er 10.000 leden zijn? Dan krijgen we 10.001 queries die de database bestoken. Dat is precies het beruchte N+1-probleem, het soort fout dat een server onderuit kan halen. JPA probeerde handig te zijn door gekoppelde data “pas op het moment dat het nodig is” lazy op te halen, en juist die handigheid veranderde in een ramp.
Praktisch advies: pragmatisch databaseontwerp
Wat moet je in de praktijk dan doen? Je moet een balans vinden tussen schoolboek-normalisatie en het gemak van JPA.
Tot slot: meer gemak vraagt om meer kennis
JPA is zonder twijfel een revolutie. Het heeft ons bevrijd van de eindeloze herhaling van steeds opnieuw SQL schrijven. Maar denken: “Ik gebruik nu JPA, dus ik hoef SQL niet meer te kennen” is gevaarlijk.
JPA is geen tovenaar. Het is slechts een secretaresse die in jouw plaats SQL schrijft. Als jij die secretaresse verkeerde instructies geeft, door slechte mappings, EAGER loading en dergelijke, dan zal ze stilletjes honderd queries afvuren en de database om zeep helpen. Om te bewaken en te tunen of de SQL die JPA genereert wel echt efficiënt is, moet je paradoxaal genoeg juist méér van SQL begrijpen. Comfort brengt altijd verantwoordelijkheid met zich mee.
Nu weten we hoe we data in objecten stoppen. Maar kunnen we die objecten, die entities, dan zomaar rechtstreeks naar de frontend, naar Vue.js, sturen? Wat als de User-entity een wachtwoord bevat? En wat gebeurt er met de beveiliging als we de frontend informatie geven die die eigenlijk nooit had mogen zien?
De volgende keer praten we over DTO’s, Data Transfer Objects, en over REST API-ontwerp, dus over de technieken waarmee data veilig verpakt en afgeleverd wordt.