Als de server traag is, het aantal threads verhogen?
Toen ik voor het eerst bij het bedrijf kwam, werd de Spring Boot API-server waar ik de leiding over had langzamer als er veel verkeer was. Omdat ik de oorzaak niet kende, begon ik te Googlen.
“Trage reactie van de Spring Boot-server” “Tomcat-prestaties afstemmen”
Als resultaat van de zoekopdracht was het meest voorkomende advies op blogs en communities eenvoudig. ‘Vergroot de Thread Pool-grootte van Tomcat. Uw verzoek wacht omdat er niet genoeg werknemers zijn.’
Ik dacht: “Aha, we hebben een tekort aan werknemers!” Ik dacht eenvoudig. Ik heb onmiddellijk de application.yml-instellingen geopend en het aantal threads verhoogd van de standaardwaarde van 200 naar 2.000. Volgens mijn berekeningen is het aantal werknemers vertienvoudigd, dus de verwerkingssnelheid moest hoger.
Maar toen ik na de implementatie het monitoringscherm zag, verstijfde ik. De server bewoog eigenlijk langzamer, het CPU-gebruik steeg enorm, maar het aantal verwerkte verzoeken nam zelfs af. Het leek alsof de arbeiders gewoon in de lucht aan het scheppen waren, zonder enig werk te doen.
Waarom is in vredesnaam het aantal arbeiders toegenomen, maar is de fabriek langzamer geworden? Terwijl ik de reden onderzocht, kwam ik de duurste kostenpost van het besturingssysteem tegen: ‘Context Switching’.

Review: Discussies, weet je nog?
Voor degenen die dit artikel voor de eerste keer lezen, of voor degenen die niet bekend zijn met de inhoud van het vorige artikel (Deel 4: Processen en discussies), laten we even terugspoelen.
In ons wereldbeeld van het ‘digitale logistieke centrum’:
Spring Boot is feitelijk multi-threaded. Elke keer dat er een verzoek binnenkomt, wordt één werker (thread) toegewezen om het werk te doen. Dus ik dacht gewoon: “Als er meer werknemers zijn, worden er toch meer aanvragen tegelijkertijd verwerkt?”
Maar er was iets dat ik over het hoofd zag. Het is het aantal CPU-kernen, de belangrijkste werknemers in onze fabriek.
Ploegendienst in een digitaal distributiecentrum
In feite kan de CPU-kern, de kernwerker van een computer, slechts één taak tegelijk uitvoeren. (Gebaseerd op single core) We luisteren echter tegelijkertijd naar liedjes, coderen en gebruiken KakaoTalk. Hoe is dit mogelijk?
Dit komt omdat de fabrieksmanager (OS) de arbeiders (CPU’s) opdracht geeft om met een ongelooflijk hoge snelheid in ploegendienst te werken. “Speel het nummer 0,001 seconden af en stop! Stuur KakaoTalk voor de volgende 0,001 seconden en stop!”
Dit is ‘Time Sharing’, en het proces waarbij de medewerker de tool neerlegt en een nieuwe tool oppakt is ‘Context Switching’.
De prijs van het wisselen van taak: tijd om van kleding te wisselen
Dit is wat er gebeurde toen ik het aantal threads verhoogde naar 2000.
De CPU bestaat uit één geheel, met 2000 threadwerkers die roepen: “Weg ermee!” De CPU heeft voortdurend beurtelings contact met 2.000 mensen om het werk eerlijk te verwerken.
Het probleem is dat er ‘voorbereidingstijd’ nodig is bij de overgang van het werk van werknemer A naar het werk van werknemer B.
Deze ‘tijd om op te nemen, op te bergen en te lezen’ wordt ‘context-switchingkosten (overhead)’ genoemd. Als er voldoende werknemers zijn, zijn deze kosten verwaarloosbaar. Maar wat als er te veel werknemers zijn? De CPU komt in een situatie terecht waarin hij de hele dag de personeelsboeken bijhoudt, maar niet in staat is om ‘eigenlijk werk (berekeningen)’ te doen. Dit was de echte reden dat mijn server traag was.
[Codeverificatie] Is het noodzakelijkerwijs sneller, alleen maar omdat er veel threads zijn?
Zien is het horen waard. Laten we het bewijzen met code. Laten we de snelheid vergelijken van het uitvoeren van hetzelfde aantal optelbewerkingen met één thread en deze opdelen in 1 miljoen threads. Gezond verstand suggereert dat 1 miljoen eenheden sneller zouden moeten zijn, maar de realiteit is anders.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class ContextSwitchingTest {
private static final int TASK_COUNT = 1_000_000;
public static void main(String[] args) throws InterruptedException {
// 1. Verwerking met single thread (geen ploegendienst)
long start = System.currentTimeMillis();
for (int i = 0; i < TASK_COUNT; i++) {
simpleTask();
}
System.out.println("Single thread tijd: " + (System.currentTimeMillis() - start) + "ms");
// 2. Verwerking met enorm veel threads (veroorzaakt context switching)
// Onbegrensde thread pool maken (let op: computer kan vastlopen)
ExecutorService executor = Executors.newCachedThreadPool();
start = System.currentTimeMillis();
for (int i = 0; i < TASK_COUNT; i++) {
executor.submit(() -> simpleTask());
}
executor.shutdown();
executor.awaitTermination(1, TimeUnit.HOURS);
System.out.println("Multi-thread tijd: " + (System.currentTimeMillis() - start) + "ms");
}
private static void simpleTask() {
int a = 1 + 1; // Heel licht werk
}
}
Voorbeeldresultaten (varieert per omgeving):
Analyse: De taak zelf (1+1) is zo eenvoudig dat deze in een oogwenk kan worden voltooid. Bij de multi-threaded methode zijn de kosten voor het maken van een miljoen threads en het heen en weer schakelen van het besturingssysteem tussen deze threads echter duizenden keren duurder dan de bewerkingstijd. De navel is groter dan de maag
Lessen uit de praktijk: de goede plek vinden
Hoeveel threads zijn er dan geschikt voor een Spring Boot-server? Het antwoord hangt af van “wat de server doet.”
Echter, net als in de situatie die ik heb meegemaakt, is het blindelings verhogen van het aantal naar 2.000 te veel. Dit komt omdat naarmate het aantal threads toeneemt, er meer geheugen (stack) wordt verbruikt en de CPU overbelast raakt vanwege de kosten voor contextwisseling.
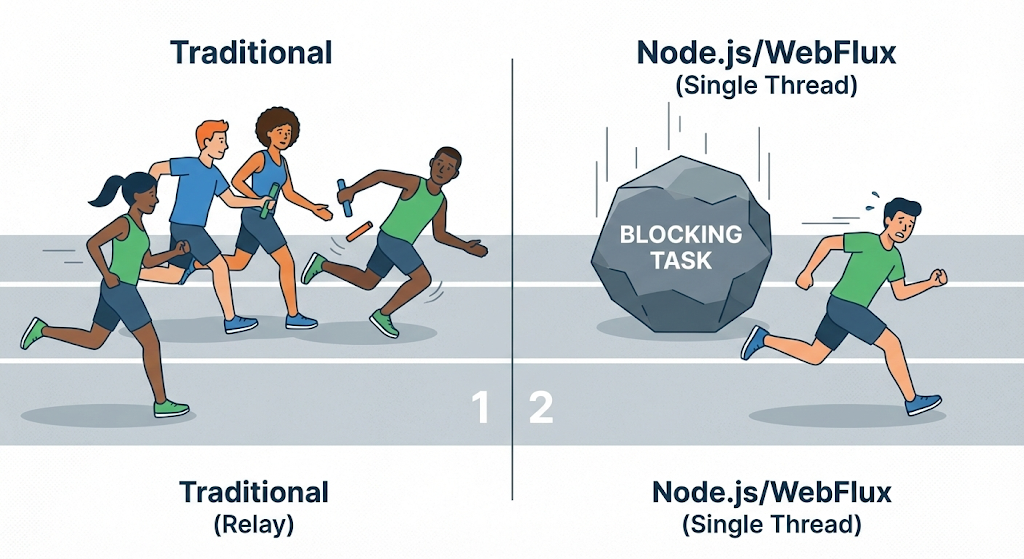
De laatste tijd trekken niet-blokkerende technologieën zoals Node.js en Spring’s WebFlux de aandacht om dit probleem op te lossen. Ze gebruiken de strategie van “verhoog het aantal threads niet, laat één persoon het snel verwerken zonder te stoppen.”
Sluiting: er is geen gratis lunch
We denken vaak ten onrechte dat “het tegelijkertijd verwerken van dingen sneller is.” In de computerwereld is ‘gelijktijdig’ echter eigenlijk gewoon ploegendienst op hoge snelheid, wat bijna een truc is.
Als je eenmaal begrijpt contextwisseling, zul je zien waarom servertuning niet alleen maar gaat over het ‘oppompen van de cijfers’. Het willekeurig verhogen van het aantal threads kan feitelijk een vergif worden dat de server verstikt.
Nu lijken de interne fabrieken van de computer (CPU, RAM, Process) redelijk goed te draaien. Laten we nu de fabrieksdeur openen en naar buiten gaan. Hoe sturen we gegevens die in onze fabriek zijn gemaakt naar een andere fabriek (klant) ver weg?
De volgende keer zullen we het hebben over netwerken, HTTP en dat onzichtbare wegennetwerk.