Si el servidor es lento, ¿aumentar los hilos?
Cuando me uní a la empresa por primera vez, el servidor Spring Boot API del que estaba a cargo se ralentizaba cada vez que había mucho tráfico. Como no sabía la causa, comencé a buscar en Google.
«Respuesta lenta del servidor Spring Boot» «Ajuste del rendimiento de Tomcat»
Como resultado de la búsqueda, el consejo más común encontrado en blogs y comunidades fue simple. ‘Aumentar el tamaño del grupo de subprocesos de Tomcat. Su solicitud está esperando porque no hay suficientes trabajadores.’
Pensé: “¡Ajá, nos faltan trabajadores!” Pensé simplemente. Inmediatamente abrí la configuración de application.yml y aumenté el número de subprocesos del valor predeterminado de 200 a 2000. Según mis cálculos, el número de trabajadores aumentó 10 veces, por lo que la velocidad de procesamiento tenía que ser más rápida.
Pero después de ver la pantalla de monitoreo después de la implementación, me quedé paralizado. En realidad, el servidor se movía más lentamente, el uso de la CPU se disparó, pero la cantidad de solicitudes procesadas en realidad disminuyó. Parecía como si los trabajadores simplemente estuvieran paleando en el aire sin hacer ningún trabajo.
¿Por qué aumentó el número de trabajadores, pero la fábrica se volvió más lenta? Mientras investigaba el motivo, me encontré con el coste más caro del sistema operativo, el ‘Context Switching’.

Reseña: Hilos, ¿recuerdas?
Para aquellos que están leyendo este artículo por primera vez, o para aquellos que no están familiarizados con el contenido del artículo anterior (Parte 4: Procesos e Hilos), retrocedamos un momento.
En nuestra visión del mundo de “centro logístico digital”:
Spring Boot es básicamente multiproceso. Cada vez que llega una solicitud, se asigna un trabajador (hilo) para realizar el trabajo. Así que simplemente pensé: «Si hay más trabajadores, se procesarán más solicitudes simultáneamente, ¿verdad?»
Pero hubo algo que pasé por alto. Es el número de núcleos de CPU, los trabajadores clave de nuestra fábrica.
Trabajo por turnos en un centro de distribución digital
De hecho, el núcleo de la CPU, el núcleo de trabajo de una computadora, solo puede realizar una tarea a la vez. (Basado en un solo núcleo) Sin embargo, escuchamos canciones, codificamos y usamos KakaoTalk al mismo tiempo. ¿Cómo es esto posible?
Esto se debe a que el director de la fábrica (OS) ordena a los trabajadores (CPU) que «cambien de trabajo» a una velocidad increíblemente rápida. «¡Reproduzca la canción durante 0,001 segundos y deténgase! ¡Envíe KakaoTalk durante los próximos 0,001 segundos y deténgase!»
Esto es «Tiempo compartido», y el proceso en el que el trabajador deja la herramienta y toma una nueva herramienta es «Cambio de contexto».
El precio del cambio de tarea: hora de cambiarse de ropa
Esto es lo que sucedió cuando aumenté el número de subprocesos a 2000.
La CPU es un solo cuerpo, con 2000 trabajadores de subprocesos gritando: «¡Deshazte de ella!» La CPU se reúne continuamente con 2000 personas por turnos para procesar el trabajo de manera justa.
El problema es que se necesita ‘tiempo de preparación’ cuando se pasa del trabajo del trabajador A al trabajo del trabajador B.
Este “tiempo para registrar, guardar y leer” se llama “costo de cambio de contexto (gastos generales)”. Cuando hay trabajadores adecuados, este costo es insignificante. ¿Pero qué pasa si hay demasiados trabajadores? La CPU cae en una situación en la que organiza los libros de contabilidad de los trabajadores todo el día, pero no puede realizar ningún «trabajo real (cálculo)». Esta fue la verdadera razón por la que mi servidor estaba lento.
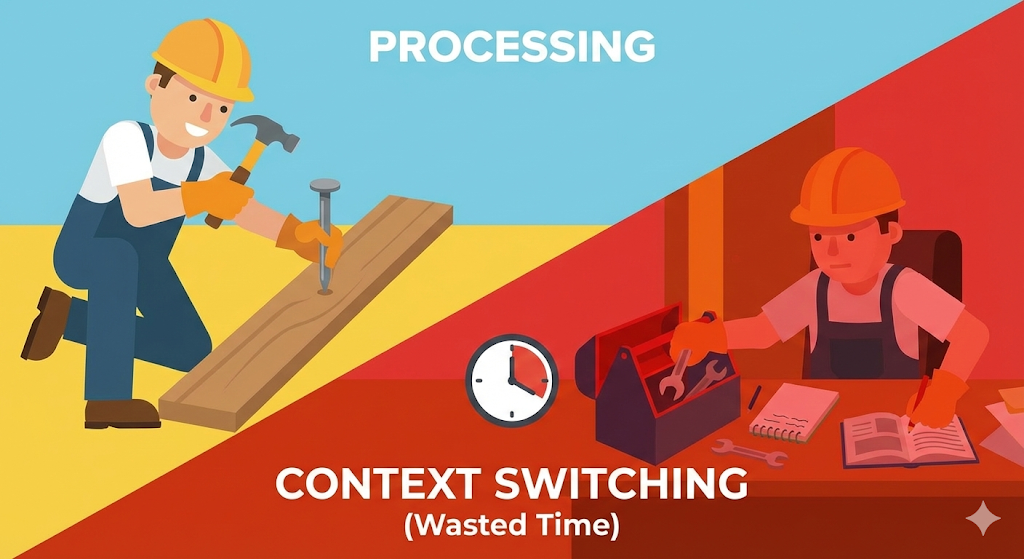
[Verificación de código] ¿Es necesariamente más rápido solo porque hay muchos hilos?
Vale la pena escuchar y ver. Probémoslo con código. Comparemos la velocidad de realizar la misma cantidad de operaciones de suma usando un subproceso y dividiéndolo en 1 millón de subprocesos. El sentido común sugiere que 1 millón de unidades debería ser más rápido, pero la realidad es diferente.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class ContextSwitchingTest {
private static final int TASK_COUNT = 1_000_000;
public static void main(String[] args) throws InterruptedException {
// 1. Procesar con un solo hilo (sin turnos)
long start = System.currentTimeMillis();
for (int i = 0; i < TASK_COUNT; i++) {
simpleTask();
}
System.out.println("Tiempo hilo unico: " + (System.currentTimeMillis() - start) + "ms");
// 2. Procesar con muchisimos hilos (provoca cambio de contexto)
// Crear un pool de hilos sin limite (aviso: el ordenador puede congelarse)
ExecutorService executor = Executors.newCachedThreadPool();
start = System.currentTimeMillis();
for (int i = 0; i < TASK_COUNT; i++) {
executor.submit(() -> simpleTask());
}
executor.shutdown();
executor.awaitTermination(1, TimeUnit.HOURS);
System.out.println("Tiempo multi-hilo: " + (System.currentTimeMillis() - start) + "ms");
}
private static void simpleTask() {
int a = 1 + 1; // Tarea muy ligera
}
}
Resultados de ejemplo (varían según el entorno):
Análisis: La tarea en sí (1+1) es tan simple que se puede completar en un abrir y cerrar de ojos. Sin embargo, en el método de subprocesos múltiples, el costo de crear un millón de subprocesos y hacer que el sistema operativo cambie entre ellos es miles de veces más costoso que el tiempo de operación. El ombligo es más grande que el estómago
Lecciones de la práctica: encontrar el punto óptimo
Entonces, ¿cuántos subprocesos son apropiados para un servidor Spring Boot? La respuesta depende de “lo que hace el servidor”.
Sin embargo, al igual que la situación que experimenté, aumentar ciegamente el número a 2000 es demasiado. Esto se debe a que a medida que aumenta el número de subprocesos, se consume más memoria (pila) y la CPU se sobrecarga debido a los costos de cambio de contexto.
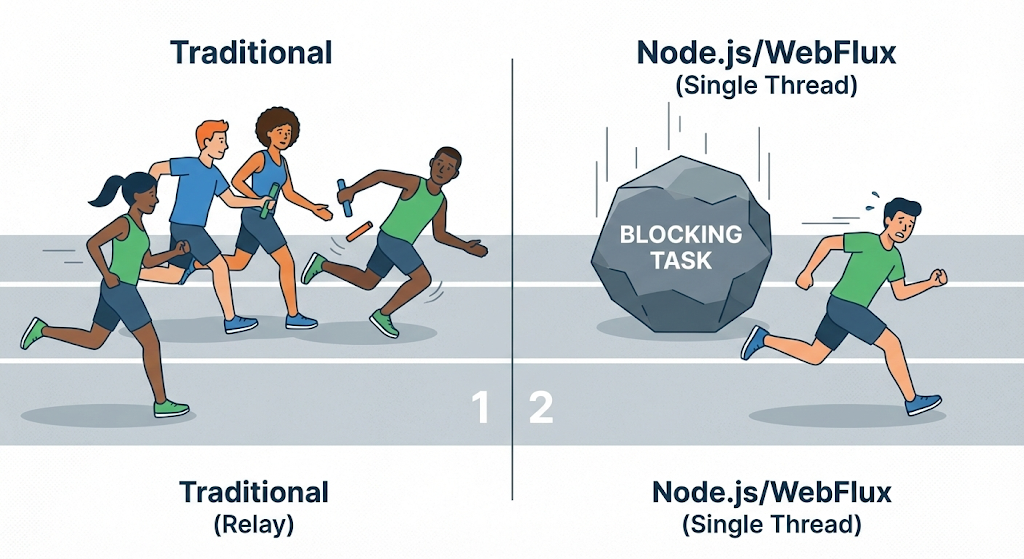
Recientemente, las tecnologías sin bloqueo como Node.js y WebFlux de Spring están atrayendo la atención para resolver este problema. Utilizan la estrategia de «no aumentar el número de subprocesos, dejar que una persona procese rápidamente sin detenerse».
Cierre: No hay almuerzo gratis
A menudo creemos erróneamente que «procesar cosas al mismo tiempo es más rápido». Sin embargo, en el mundo de las computadoras, «simultáneo» es en realidad sólo trabajo por turnos de alta velocidad, lo cual es casi un truco.
Una vez que comprenda el cambio de contexto, verá por qué el ajuste del servidor no se trata solo de «aumentar los números». Los hilos aumentados indiscriminadamente pueden convertirse en un veneno que ahoga el servidor.
Ahora, las fábricas internas de la computadora (CPU, RAM, Proceso) parecen estar funcionando bastante bien. Ahora, abramos la puerta de la fábrica y salgamos. ¿Cómo enviamos los datos creados en nuestra fábrica a otra fábrica (cliente) lejana?
La próxima vez hablaremos de redes, HTTP y esa red de carreteras invisible.