「え? 今のでビルド終わったんですか?」
Docker の便利さを一度味わってしまったあと、私はチーム長に内緒で、自分の開発環境を少しずつ Docker に移し始めた。Dockerfile という設計図を書き、docker build コマンドを打った。
最初はそれなりに時間がかかった。Ubuntu を落として、Java を入れて、自分のプロジェクトのライブラリ、Jar、をダウンロードするのに 5 分ほどかかった。「まあ最初だから時間がかかるんだろう」
ところがコードのタイプミスを一つ直して、もう一度ビルドを実行したとき、私は自分の目を疑った。Enter を押した瞬間にターミナルへ Successfully built と表示されたのだ。かかった時間はたったの 0.1 秒。
「まさか壊れてないよな? さっきは 5 分かかったのに、どうしてこんな一瞬で終わるんだ?」
不安になってサーバーを立ち上げてみたが、コードはきちんと修正されていた。では Docker の中では一体何が起きていたのだろう? この異常な速さの秘密は「レイヤー(Layer)」という独特な保存方式にあった。
イメージ(Image)とコンテナ(Container)
本格的な仕組みに入る前に、混同しやすい二つの用語だけ整理しておこう。
私たちがデプロイ時にサーバーへ送るのは「コンテナ」ではなく「イメージ」だ。サーバー側はそのイメージを受け取って実行するだけでいい。
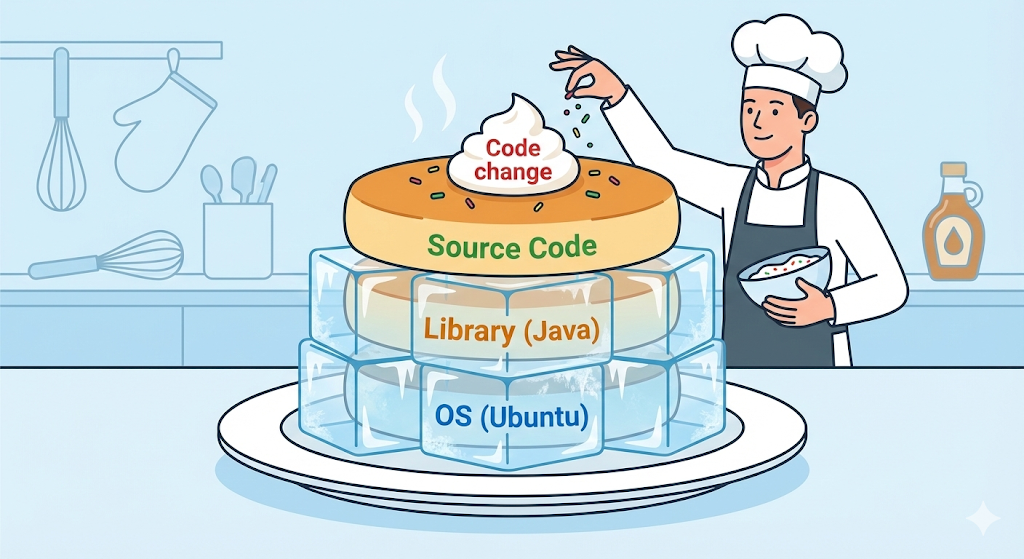
レイヤー(Layer): 透明なセロファンの魔法
Docker イメージは一つの巨大なファイルではない。まるで「透明なセロファン」を何枚も重ねたようなものだ。Dockerfile に書かれた命令は、一行ごとにそれぞれ一つのレイヤーになる。
例えばこうだ。
# 1層目: Ubuntu (OS) をインストール
FROM ubuntu:20.04
# 2層目: Javaをインストール
RUN apt-get install openjdk-17-jdk
# 3層目: 自分のコードをコピー
COPY my-app.jar /app/my-app.jar
# 4層目: 実行
CMD ["java", "-jar", "/app/my-app.jar"]
Dockerfile に書かれた内容をじっくり見ると、構造はそれほど難しくないことが分かる。「Ubuntu を入れて、FROM、Java をインストールして、RUN、自分のコードを持ってきて、COPY、実行しろ、CMD。」という流れだ。
結局のところ、私たちが VM やサーバーのターミナルに入って手で一つずつ打っていた「サーバーのセットアップ手順」を、そのまま文章として書き写しただけなのだ。この一枚の文書さえあれば、誰かが横で指示しなくても、Docker が自動的に必要なインストールを進めてくれる。この考え方は、あとで扱う「CI/CD 自動化」の核心にもつながっている。
では、なぜ Docker はこの手順を一気にまとめず、わざわざ一行ずつ「レイヤー」に分けて積み上げているのだろう?
答えは 再利用、Caching のためだ。もし私がコードを修正してもう一度ビルドすると、Docker は賢く考える。「1 層目、OS と 2 層目、Java は前回と同じだな。なら新しく作り直す必要はない。前に作ったキャッシュをそのまま使おう」
そして変更が入った 3 層目、コードのコピー、から先だけを新しく作り直す。だから二回目のビルドは 0.1 秒で終わったのだ。
[Code Verification] レイヤーキャッシュを自分の目で確認する
本当にそうなのか、コードで確認してみよう。簡単な Dockerfile を作って二回ビルドすればいい。
FROM alpine:latest
RUN echo "1. 基本ユーティリティをインストール中..." && sleep 2 # 2秒かかる処理
COPY test.txt /app/test.txt
CMD ["cat", "/app/test.txt"]
$ docker build -t my-test:v1 .
# 結果:
# [2/3] RUN echo "1. 基本ユーティリティをインストール中..." ... 2.1s (2秒かかる)
$ docker build -t my-test:v2 .
# 結果:
# [2/3] RUN echo "1. 基本ユーティリティをインストール中..." ... CACHED (0秒!)
ログにくっきり表示された CACHED という単語が見えるだろうか。Docker が 2 秒かかる処理をスキップした証拠だ。
実務アドバイス: 順番が命
このレイヤーキャッシュの原理を理解すれば、Dockerfile をどう書くべきか答えが見えてくる。核心は単純で、「あまり変わらないものを下、つまり先に置き、よく変わるものを上、つまり後に置く」ことだ。
悪い例:
# 1. ソースコードを先にコピー(頻繁に変わる!)
COPY . .
# 2. ライブラリをインストール(ほとんど変わらない)
RUN npm install
ソースコードは一日に何十回も変わる。もし 1 番が変われば、Docker はその後ろにある 2 番、ライブラリインストール、のキャッシュまで無効にして再実行してしまう。コードを一行直しただけなのに、また npm install を待つことになる。
良い例:
# 1. package.json だけを先にコピー
COPY package.json .
# 2. ライブラリをインストール(ソースが変わってもキャッシュされる)
RUN npm install
# 3. ソースコードをコピー
COPY . .
順番を変えるだけで、ビルド速度は 10 倍になることもある。これが Docker 初心者と、Docker を使いこなす人との差だ。
実務アドバイス 2: タグ(Tag)は命綱
上のコードでは docker build -t my-test:v1 . と書いたが、ここでコロン : の後ろについている v1 がタグ、Tag、だ。
多くの初心者は面倒だからとタグを付けないが、そうすると Docker は自動的に latest というタグを付ける。
このタグを付ける習慣一つが、将来あなたの退勤時間を守ってくれる。
おわりに: 0.1 秒の魔法を手に入れる
Docker イメージは単なるファイルの塊ではなく、環境をもっとも効率よく届けるために幾重にも積み上げられた 技術の結晶 だ。レイヤーキャッシュを理解し、Dockerfile の順番さえきちんと整えれば、0.1 秒でビルドが終わる軽くて速いデプロイ環境を作ることができる。
これで、自分のコンピュータ環境を完璧に凍らせて、イメージとしてサーバーへ送る準備は整った。
ところが実際にこのイメージをサーバーで立ち上げようとすると、新しい悩みが出てくる。Web サービスはサーバー用コンテナ一つだけでは動かない。データベースも必要だし、Redis も必要だし、フロントエンドサーバーも必要だ。
これだけ多くのコンテナを、一つひとつ別々のコマンドで起動・停止して管理できるのだろうか。互いの通信はどうするのか。単体の「イメージ」を超えて、巨大な「アプリケーション」をどう組み立てるのか。次回は、Docker の世界観を広げる コンテナ、サービス、そしてスタック という概念について見ていこう。