「データの重複は絶対悪だ」
大学のデータベースの授業で、教授は唾を飛ばしながら力説していた。「第1正規形、第2正規形、第3正規形……重複データは記憶領域を無駄にし、整合性を壊す。分けろ、そしてもっと分けろ!」
私はその教えに忠実だった。卒業制作ではテーブルを10個、20個と細かく分割した。’User’、’Address’、’City’、’Zipcode’……住所1つ保存するのに3つのテーブルが必要になるほど、私のDB設計は「教科書どおり」に完璧だった。
だが実務では、その完璧な設計が「災害」になった。顧客一覧を1つ表示したいだけなのに、JOINを5回も書かなければならなかった。クエリは複雑になり、速度は落ち、何よりJavaオブジェクトへデータを詰め替える作業があまりにも苦しかった。
「ただ画面に1行分のデータを出したいだけなのに、なんでこんなにコードが複雑なんだ?」
そのとき初めてわかった。学校では「保存」の効率を教えてくれたが、実務では「読み取り」の効率のほうがはるかに重要だということ。そして、オブジェクト指向言語であるJavaと、リレーショナルデータベースの間には、思っていた以上に深い川が流れているということを。
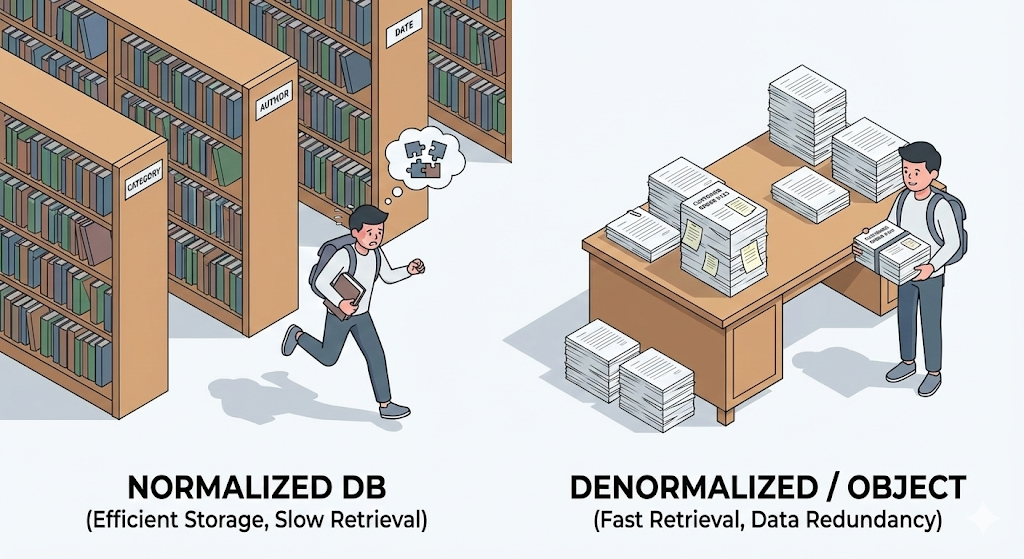
パラダイムの不一致: 四角と丸
私たちが味わう痛みの根本原因は、いわゆるパラダイムの不一致、Impedance Mismatch にある。
学部時代の私は、この2つの世界を無理やりつなぎ合わせるために、自分でSQLを書いていた。Javaオブジェクトを分解してDBにINSERTし、DBから SELECT で取り出したデータを ResultSet から1行ずつ読み出して、Set や List のようなJavaコレクションに地道に詰め替える。まるで開発者ではなく、「データ翻訳家」になった気分だった。
そんな退屈な繰り返し作業を解決するために登場したのが、JPA(Java Persistence API)、つまりORM(Object-Relational Mapping)の技術だ。
JPAとORM: オブジェクトでDBを扱う技術
ORMとは文字どおり、「オブジェクトとリレーショナルDBを結びつける技術」だ。言葉どおり、DBテーブルをJavaオブジェクトのように定義し、扱うことが本質になる。
私たちはもう手で CREATE TABLE クエリを書く必要がない。代わりにJavaクラスを作り、@Entity というシールを貼る。するとJPA、つまりJavaにおけるORMの標準がそのクラスを見て、「ああ、こういう形のテーブルが必要なんだな」と判断し、DBに自動でテーブルを作ってくれる。
データを保存するときもSQLを書くのではなく、Javaコレクションに入れるような感覚で repository.save(member) と書けば終わる。開発者はあくまで「オブジェクト指向の視点」でコードを書き、泥臭いSQL翻訳作業はJPAに押しつけるわけだ。
だが、Re: Booting シリーズで学んだように、便利さにはいつも代償がある。私はJPAという自動翻訳機を信じすぎた結果、「N+1問題」という時限爆弾を自分のコードに埋め込んでしまった。
[Code Verification] N+1問題、クエリ爆弾
JPAを初めて使うジュニア開発者がほぼ確実にぶつかる問題だ。状況は単純だ。「すべての会員と、その会員が所属するチーム名を表示せよ。」
// 1. すべてのメンバーを取得する(クエリ1回発生)
List<Member> members = memberRepository.findAll();
for (Member member : members) {
// 2. 各メンバーのチーム名を出力する
// メンバーが100人なら、チーム情報を取得するためのクエリが100回追加で発行される!
System.out.println(member.getTeam().getName());
}
期待していたクエリ: SELECT * FROM Member JOIN Team ...(1回だけ)
実際に発生したクエリ:
会員が100人なら、クエリは101回、つまり1 + N回飛ぶ。会員が1万人なら? 1万1個のクエリがDBを直撃する。これがサーバーを落としかねないN+1問題だ。JPAは開発者を楽にしようとして、関連データをその都度、Lazy に取りに行こうとした。その親切さが、逆に惨事を生んだのである。
実務アドバイス: 実用主義のDB設計
では、実務ではどうすればいいのか。教科書的な正規化と、JPAの便利さのあいだでバランスを取らなければならない。
締めくくり: 楽をしたいなら、もっと知らなければならない
JPAは間違いなく革命だ。退屈なSQLの繰り返し作業から私たちを解放してくれたのだから。だが、「JPAを使うからもうSQLは知らなくていい」という考えは危険だ。
JPAは魔法使いではない。私の代わりにSQLを書く「秘書」にすぎない。私がその秘書に間違った指示を出せば、たとえば不適切なマッピングやEAGERローディングなどによって、秘書は黙って100本のクエリを発行し、DBを壊しにかかる。JPAが生成するSQLが本当に効率的なのかを監視し、チューニングするには、逆説的だがSQLをもっと深く理解していなければならない。楽さには責任が伴うのだ。
これで私たちは、データをオブジェクトに詰める方法を知った。だが、そのオブジェクト、つまりEntityをそのままフロントエンド、Vue.js に送ってしまってもいいのだろうか。もしUserエンティティにパスワードが入っていたら? フロントが必要としていない情報まで全部渡してしまったら、セキュリティはどうなるのか。
次回は、データを安全に梱包して届ける技術、DTO(Data Transfer Object)とREST API設計について話してみよう。