“Ué? O build já terminou?”
Depois de sentir na prática como o Docker era conveniente, comecei a migrar meu ambiente de desenvolvimento para Docker aos poucos, em segredo, sem contar ao meu líder. Escrevi um projeto chamado Dockerfile e rodei o comando docker build.
Na primeira vez demorou bastante. Entre baixar o Ubuntu, instalar Java e puxar as bibliotecas, os JARs, do meu projeto, levou cerca de cinco minutos. “Bom, como é a primeira vez, faz sentido demorar.”
Mas quando corrigi um simples erro de digitação no código e apertei build de novo, duvidei dos meus próprios olhos. No exato momento em que pressionei Enter, a mensagem Successfully built já apareceu no terminal. Tempo total: apenas 0,1 segundo.
“Espera aí, isso quebrou? Agora há pouco levava cinco minutos. Como pode terminar de repente em um instante?”
Liguei o servidor meio inseguro, mas o código estava corrigido perfeitamente. Então o que exatamente estava acontecendo dentro do Docker? O segredo dessa velocidade absurda estava em um modo de armazenamento muito peculiar chamado ‘layer’.
Image e container
Antes de entrar no mecanismo em si, vamos esclarecer dois termos que costumam se confundir.
O que enviamos ao servidor durante o deploy não é um ‘container’, mas uma ‘image’. O servidor só precisa receber essa image e executá-la.
Layer: a magia do celofane transparente
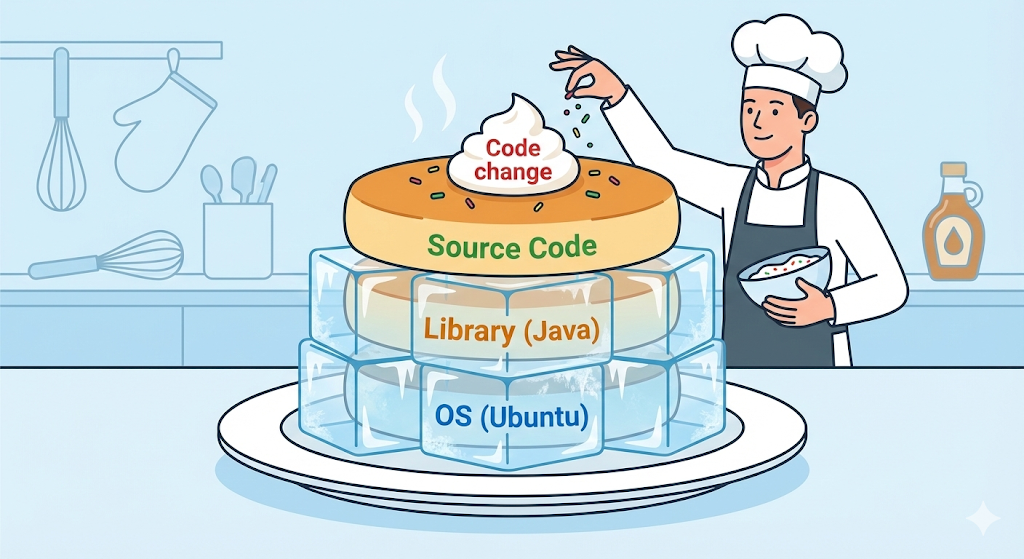
Uma imagem Docker não é um único arquivo monolítico. Ela se parece mais com várias folhas de celofane transparente, layers, empilhadas umas sobre as outras. Cada linha de instrução escrita em um Dockerfile vira sua própria camada.
Vamos pegar um exemplo.
# Camada 1: instalar Ubuntu (SO)
FROM ubuntu:20.04
# Camada 2: instalar Java
RUN apt-get install openjdk-17-jdk
# Camada 3: copiar meu codigo
COPY my-app.jar /app/my-app.jar
# Camada 4: executar
CMD ["java", "-jar", "/app/my-app.jar"]
Se você ler com calma o conteúdo de um Dockerfile, vai perceber que a estrutura não é tão complicada assim. “Instale Ubuntu, FROM, instale Java, RUN, traga o meu código, COPY, e execute-o, CMD.”
No fim das contas, tudo o que fizemos foi pegar aquele processo de configuração de servidor que antes digitávamos manualmente em uma VM ou em um terminal de servidor e escrevê-lo em um documento. Com apenas esse documento, o Docker executa todos os passos de instalação sozinho. Esse conceito também se conecta, mais adiante, ao princípio central da automação de CI/CD.
Mas então por que o Docker não simplifica todo esse processo em um único passo? Por que ele faz questão de separar tudo linha por linha em layers e empilhá-las cuidadosamente?
A resposta é reutilização, ou seja, caching. Se eu modificar o código e fizer o build de novo, o Docker pensa de forma inteligente: “O primeiro andar, o sistema operacional, e o segundo andar, Java, estão exatamente iguais aos de antes. Então não há motivo para reconstruí-los. Basta reutilizar os layers já criados em cache.”
Depois disso ele reconstrói apenas a partir do terceiro andar que mudou, ou seja, a etapa de copiar o código. Foi por isso que o segundo build terminou em apenas 0,1 segundo.
[Code Verification] Ver o cache de layers com os próprios olhos
Não vamos ficar só no discurso. Vamos verificar isso com código. Basta criar um Dockerfile simples e rodar o build duas vezes.
FROM alpine:latest
RUN echo "1. Instalando utilitarios basicos..." && sleep 2 # Leva 2 segundos
COPY test.txt /app/test.txt
CMD ["cat", "/app/test.txt"]
$ docker build -t my-test:v1 .
# Resultado:
# [2/3] RUN echo "1. Instalando utilitarios basicos..." ... 2.1s (levou 2s)
$ docker build -t my-test:v2 .
# Resultado:
# [2/3] RUN echo "1. Instalando utilitarios basicos..." ... CACHED (0s!)
Está vendo a palavra CACHED aparecer com clareza no log? Essa é a prova de que o Docker pulou a operação que normalmente levaria dois segundos.
Conselho prático: a ordem é tudo
Quando você entende esse princípio de cache em layers, a resposta para como escrever um Dockerfile fica óbvia. A ideia central é simples: “Coloque embaixo, ou seja, antes, o que quase não muda; e em cima, ou seja, depois, o que muda com frequência.”
Exemplo ruim:
# 1. Copiar primeiro o codigo fonte (muda com frequencia)
COPY . .
# 2. Instalar bibliotecas (quase nao muda)
RUN npm install
O código-fonte muda dezenas de vezes por dia. Se a etapa 1 muda, o Docker invalida também o cache da etapa 2, a instalação das bibliotecas, e executa tudo de novo. Você corrige uma linha de código e precisa esperar por npm install outra vez.
Bom exemplo:
# 1. Copiar primeiro so o package.json
COPY package.json .
# 2. Instalar bibliotecas (permanece em cache)
RUN npm install
# 3. Copiar o codigo fonte
COPY . .
Só de mudar a ordem assim, a velocidade do build pode ficar dez vezes maior. Essa é justamente a diferença entre um iniciante em Docker e alguém que realmente domina a ferramenta.
Conselho prático 2: tags são sua linha de vida
No exemplo acima eu escrevi docker build -t my-test:v1 .. Aqui, o v1 que aparece depois dos dois-pontos, :, é a tag.
Muitos iniciantes não usam tags porque acham trabalhoso. Quando isso acontece, o Docker atribui automaticamente a tag latest.
Esse simples hábito de usar tags vai proteger muitos dos seus horários de saída no futuro.
Encerrando: ter em mãos a magia dos 0,1 segundo
Uma imagem Docker não é apenas um monte de arquivos, mas um condensado de tecnologia empilhado layer por layer para entregar um ambiente da forma mais eficiente possível. Se você entender o cache de layers e organizar corretamente o seu Dockerfile, pode construir um ambiente de deploy leve e rápido que termina em 0,1 segundo.
Agora está tudo pronto para congelar perfeitamente o ambiente do meu computador em uma image e enviá-la para o servidor.
Mas quando tentei realmente subir essa image no servidor, surgiu um novo problema. Um serviço web não roda com apenas um container de servidor. Ele também precisa de banco de dados, Redis e um servidor de frontend.
Dá mesmo para gerenciar todos esses containers ligando e desligando um por um com comandos separados? Como eles se comunicam entre si? Como se estrutura uma aplicação inteira, indo além de uma única image? Na próxima, vamos ampliar o universo do Docker com os conceitos de containers, services e stacks.