“Duplicação de dados é o mal absoluto”
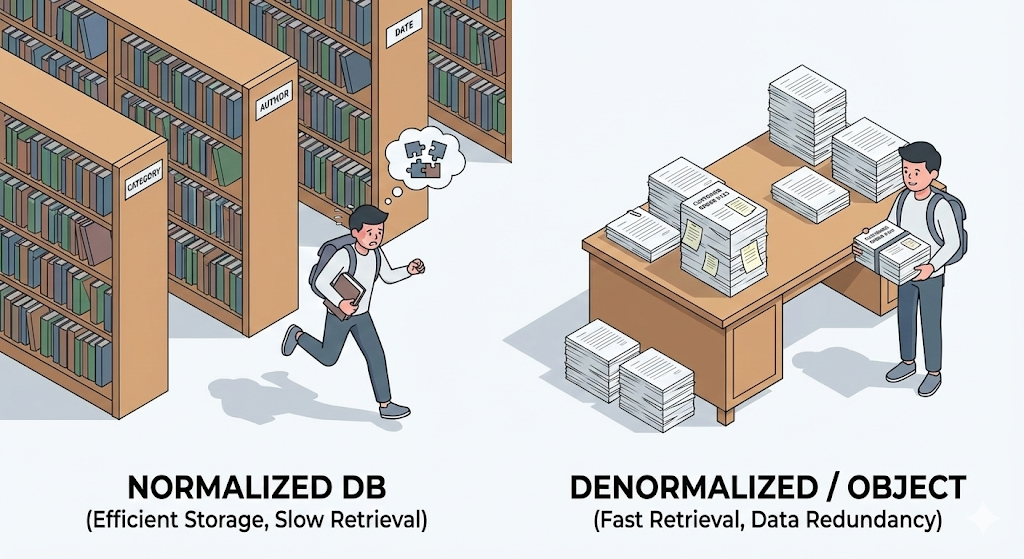
Nas aulas de banco de dados da universidade, o professor enfatizava isso com tanta força que quase cuspia enquanto falava. “Primeira forma normal, segunda forma normal, terceira forma normal… dados duplicados desperdiçam espaço de armazenamento e destroem a integridade. Separem tudo, e depois separem mais ainda!”
Eu segui esse ensinamento com disciplina. No meu projeto de conclusão, dividi tabelas em 10, depois 20 pedaços. ‘User’, ‘Address’, ‘City’, ‘Zipcode’… Meu desenho de banco de dados era tão perfeitamente “de manual” que, para armazenar um único endereço, eram necessárias três tabelas.
Mas, no trabalho real, esse projeto perfeito virou um desastre. Eu só queria buscar uma lista de clientes e já precisava escrever cinco JOINs. A consulta ficou complicada, a velocidade caiu e, pior ainda, transportar aqueles dados para objetos Java era doloroso demais.
“Como é possível que, para buscar uma única linha de dados para mostrar na tela, o código fique tão complicado assim?”
Foi aí que eu percebi. Na faculdade, nos ensinaram a otimizar o armazenamento. Na prática, a eficiência da leitura importa muito mais. E entre uma linguagem orientada a objetos como Java e um banco de dados relacional corre um rio bem mais difícil de atravessar do que parece.
Incompatibilidade de paradigma: quadrados e círculos
A causa fundamental dessa dor é o chamado desalinhamento de paradigma, ou Impedance Mismatch.
Na faculdade, eu forçava esses dois mundos a se encaixarem escrevendo SQL diretamente. Eu desmontava objetos Java para gravá-los no banco com INSERT, depois os recuperava com SELECT, lia linha por linha de um ResultSet e os transferia manualmente para coleções Java como Set ou List. Eu não me sentia um desenvolvedor, mas um tradutor de dados.
A tecnologia que surgiu para resolver esse trabalho repetitivo e cansativo foi justamente o JPA (Java Persistence API), ou seja, o mundo do ORM (Object-Relational Mapping).
JPA e ORM: lidar com o banco através de objetos
ORM, literalmente, é uma tecnologia que conecta objetos e bancos de dados relacionais. Como o próprio nome diz, a ideia central é definir e tratar as tabelas do banco como se fossem objetos Java.
Não precisamos mais escrever queries CREATE TABLE na mão. Em vez disso, criamos uma classe Java e colamos nela uma etiqueta chamada @Entity. Então o JPA, o padrão ORM do ecossistema Java, olha para essa classe e pensa: “Ah, então esta é a forma da tabela de que você precisa”, e cria a tabela automaticamente no banco.
Salvar dados também deixa de ser uma questão de escrever SQL manualmente. Basta algo como repository.save(member), quase como adicionar um elemento a uma coleção Java. O desenvolvedor continua totalmente dentro do pensamento orientado a objetos, enquanto o trabalho sujo de traduzir para SQL é empurrado para o JPA.
Mas, como aprendemos na série Re: Booting, toda conveniência tem um preço. E justamente porque confiei demais nesse tradutor automático chamado JPA, acabei plantando uma bomba-relógio no meu código: o problema N+1.
[Code Verification] O problema N+1, uma bomba de consultas
Esse é um problema que praticamente todo desenvolvedor júnior encontra quando começa a usar JPA. A situação é simples: “Exiba todos os membros e o nome do time ao qual eles pertencem.”
// 1. Buscar todos os membros (1 query disparada)
List<Member> members = memberRepository.findAll();
for (Member member : members) {
// 2. Imprimir o nome do time de cada membro
// Se forem 100 membros, saem mais 100 queries para buscar informacoes do time!
System.out.println(member.getTeam().getName());
}
A query que esperávamos: SELECT * FROM Member JOIN Team ... (apenas uma vez)
A query que realmente aconteceu:
Se houver 100 membros, serão feitas 101 consultas: 1 + N. E se houver 10 mil membros? Aí 10.001 consultas atingem o banco de dados. Esse é justamente o famoso problema N+1, o tipo de erro que pode derrubar um servidor. O JPA tentou ser conveniente carregando os dados relacionados de forma lazy, isto é, só quando necessário, e essa mesma conveniência acabou virando o desastre.
Conselho prático: design de banco de dados pragmático
Então o que fazer na prática? É preciso encontrar um equilíbrio entre a normalização de manual e a conveniência do JPA.
Fechando: para ter mais conforto, é preciso saber mais
O JPA é, sem dúvida, uma revolução. Ele nos libertou da repetição cansativa de escrever SQL de novo e de novo. Mas pensar “agora que uso JPA, já não preciso conhecer SQL” é perigoso.
JPA não é um mágico. É apenas uma secretária que escreve SQL no seu lugar. Se você der instruções erradas a essa secretária, por meio de mapeamentos ruins, carregamento EAGER e afins, ela vai disparar silenciosamente cem consultas e derrubar o banco. Para vigiar e ajustar se o SQL que o JPA gera é realmente eficiente, paradoxalmente você precisa conhecer SQL ainda mais a fundo. Conforto sempre traz responsabilidade.
Agora nós sabemos como colocar dados dentro de objetos. Mas será que podemos mandar esses objetos, essas entities, diretamente para o frontend, para o Vue.js? E se a entity User contiver uma senha? E o que acontece com a segurança se acabarmos enviando ao frontend informações que ele jamais deveria ver?
Na próxima vez, vamos falar sobre DTOs, Data Transfer Objects, e sobre o design de APIs REST, ou seja, as técnicas usadas para empacotar e entregar dados com segurança.