„Co? Ten build właśnie się skończył?”
Kiedy już poczułem wygodę Dockera, zacząłem po kryjomu, bez wiedzy team leadera, przenosić swoje środowisko developerskie kawałek po kawałku do Dockera. Napisałem plan zwany Dockerfile i uruchomiłem polecenie docker build.
Za pierwszym razem trwało to całkiem długo. Samo pobranie Ubuntu, instalacja Javy i pobieranie bibliotek, JAR-ów, dla mojego projektu zajęły około pięciu minut. „No tak, za pierwszym razem musi to chwilę potrwać.”
Ale kiedy poprawiłem jedną literówkę w kodzie i odpaliłem build ponownie, nie wierzyłem własnym oczom. Gdy tylko nacisnąłem Enter, terminal już pokazał Successfully built. Łączny czas: zaledwie 0,1 sekundy.
„Chwila, to się zepsuło? Przed chwilą trwało pięć minut. Jak to możliwe, że teraz kończy się natychmiast?”
Z niepokojem uruchomiłem serwer, ale kod był poprawiony idealnie. Co więc tak naprawdę działo się w Dockerze? Sekret tej szalonej szybkości tkwił w bardzo szczególnym sposobie przechowywania zwanym „warstwą”, Layer.
Obraz i kontener
Zanim wejdziemy w sam mechanizm, uporządkujmy najpierw dwa pojęcia, które często się mylą.
To, co wysyłamy na serwer podczas deploymentu, nie jest „kontenerem”, tylko „obrazem”. Serwer musi jedynie ten obraz odebrać i uruchomić.
Warstwa: magia przezroczystego celofanu
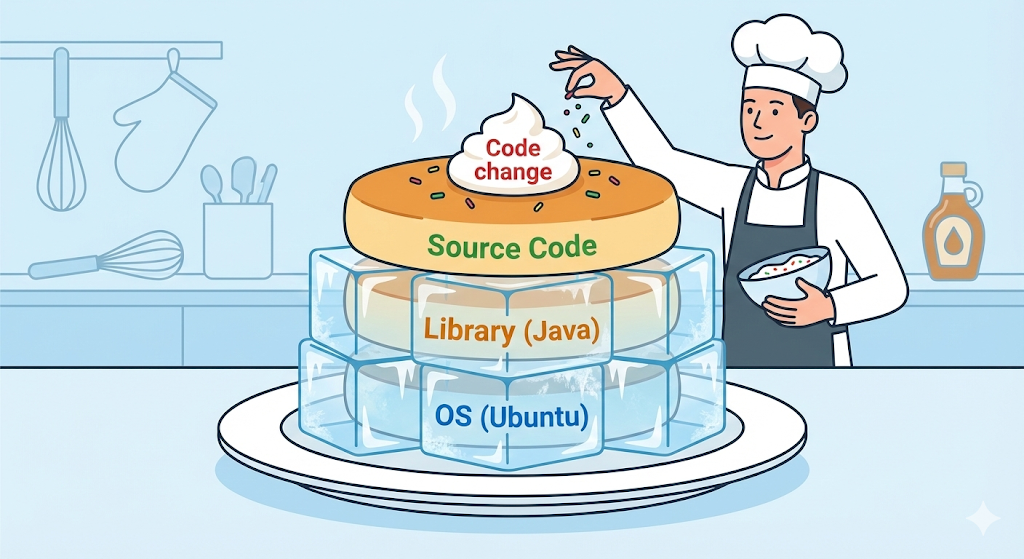
Obraz Dockera nie jest jednym monolitycznym plikiem. Bardziej przypomina kilka arkuszy przezroczystego celofanu, layers, nałożonych na siebie. Każda pojedyncza linijka instrukcji zapisana w Dockerfile staje się osobną warstwą.
Weźmy przykład.
# Warstwa 1: instalacja Ubuntu (OS)
FROM ubuntu:20.04
# Warstwa 2: instalacja Javy
RUN apt-get install openjdk-17-jdk
# Warstwa 3: kopiuj moj kod
COPY my-app.jar /app/my-app.jar
# Warstwa 4: uruchom
CMD ["java", "-jar", "/app/my-app.jar"]
Jeśli spokojnie przyjrzeć się zawartości Dockerfile, okazuje się, że struktura wcale nie jest taka trudna. „Zainstaluj Ubuntu, FROM, zainstaluj Javę, RUN, skopiuj mój kod, COPY, i uruchom go, CMD.”
Tak naprawdę zrobiliśmy tylko tyle, że spisaliśmy w dokumencie proces konfiguracji serwera, który kiedyś wpisywaliśmy ręcznie w VM albo w terminalu serwera. Mając tylko ten dokument, Docker wykonuje wszystkie kroki instalacji sam. Ta koncepcja łączy się później bezpośrednio z podstawową zasadą automatyzacji CI/CD.
Ale dlaczego Docker nie spłaszcza całego tego procesu do jednego kroku? Dlaczego świadomie rozbija go linijka po linijce na warstwy i układa je jedna na drugiej?
Odpowiedź to ponowne wykorzystanie, czyli caching. Jeśli zmienię kod i zbuduję wszystko jeszcze raz, Docker myśli sprytnie: „Pierwsze piętro, system operacyjny, i drugie piętro, Java, są dokładnie takie same jak poprzednio. Nie ma więc sensu budować ich od nowa. Wystarczy użyć wcześniej utworzonych warstw z cache.”
Następnie przebudowuje tylko od zmienionego trzeciego piętra, czyli kroku kopiowania kodu. Dlatego drugi build zakończył się w zaledwie 0,1 sekundy.
[Code Verification] Zobacz cache warstw na własne oczy
Nie poprzestawajmy na słowach. Sprawdźmy to kodem. Wystarczy stworzyć prosty Dockerfile i zbudować go dwa razy.
FROM alpine:latest
RUN echo "1. Instalacja podstawowych narzedzi..." && sleep 2 # Zajmuje 2 sekundy
COPY test.txt /app/test.txt
CMD ["cat", "/app/test.txt"]
$ docker build -t my-test:v1 .
# Wynik:
# [2/3] RUN echo "1. Instalacja podstawowych narzedzi..." ... 2.1s (zajelo 2s)
$ docker build -t my-test:v2 .
# Wynik:
# [2/3] RUN echo "1. Instalacja podstawowych narzedzi..." ... CACHED (0s!)
Widzisz wyraźnie wydrukowane w logu słowo CACHED? To dowód, że Docker pominął operację, która normalnie trwałaby dwie sekundy.
Praktyczna rada: kolejność to wszystko
Kiedy zrozumiesz zasadę cache warstw, odpowiedź na pytanie, jak pisać Dockerfile, staje się oczywista. Sedno jest proste: „To, co rzadko się zmienia, umieszczaj niżej, czyli wcześniej, a to, co zmienia się często, wyżej, czyli później.”
Zły przykład:
# 1. Najpierw kopiuj kod zrodlowy (czesto sie zmienia)
COPY . .
# 2. Instalacja bibliotek (niemal bez zmian)
RUN npm install
Kod źródłowy zmienia się dziesiątki razy dziennie. Jeśli zmieni się krok 1, Docker unieważnia także cache kroku 2, instalacji bibliotek, i wykonuje wszystko od nowa. Poprawiasz jedną linijkę kodu i znów czekasz na npm install.
Dobry przykład:
# 1. Najpierw kopiuj tylko package.json
COPY package.json .
# 2. Instalacja bibliotek (zostaje w cache)
RUN npm install
# 3. Kopiuj kod zrodlowy
COPY . .
Sama zmiana kolejności potrafi przyspieszyć build dziesięciokrotnie. To właśnie jest różnica między początkującym użytkownikiem Dockera a kimś, kto naprawdę wie, co robi.
Praktyczna rada 2: tagi to lina ratunkowa
W przykładzie powyżej napisałem docker build -t my-test:v1 .. Tutaj v1, które pojawia się po dwukropku, :, to właśnie tag.
Wielu początkujących pomija tagi, bo wydają się kłopotliwe. Gdy tak się dzieje, Docker automatycznie nadaje tag latest.
Ten jeden nawyk związany z tagami uratuje ci w przyszłości niejeden wieczór.
Na koniec: mieć w rękach magię 0,1 sekundy
Obraz Dockera nie jest po prostu zbiorem plików, lecz kondensatem technologii ułożonym warstwa po warstwie tak, by dostarczać środowisko możliwie najefektywniej. Jeśli zrozumiesz caching warstw i właściwie ułożysz Dockerfile, możesz stworzyć lekkie i szybkie środowisko deploymentowe, które buduje się w 0,1 sekundy.
Teraz wszystko jest gotowe, by idealnie zamrozić środowisko z mojego komputera jako image i wysłać je na serwer.
Ale kiedy naprawdę chciałem uruchomić ten image na serwerze, pojawił się nowy problem. Web service nie działa przecież tylko na jednym kontenerze serwera. Potrzebna jest jeszcze baza danych, Redis i serwer frontendowy.
Czy da się naprawdę zarządzać wszystkimi tymi kontenerami, uruchamiając i zatrzymując je pojedynczo osobnymi poleceniami? Jak mają się ze sobą komunikować? Jak zbudować całą aplikację, wychodząc poza pojedynczy image? Następnym razem rozszerzmy świat Dockera o pojęcia kontenerów, usług i stosów.