„Co? Dlaczego widać hasło?”
Na początku pracy w firmie biegałem bez przerwy między frontendem a backendem, próbując ogarnąć wszystko naraz. Pewnego dnia podłączałem do widoku frontendowego „API pobierające listę członków”, które stworzył kolega zatrudniony razem ze mną.
Otworzyłem kartę Network w Chrome DevTools (F12), żeby sprawdzić, czy dane poprawnie przychodzą, i w chwili, gdy zobaczyłem odpowiedź, zwątpiłem we własne oczy.
[
{
"id": 1,
"username": "tester",
"password": "$2a$10$D...", // Zaszyfrowane haslo ujawnione
"ssn": "900101-1...", // PESEL ujawniony
"createdAt": "2024-01-01"
}
]
Zaskoczony zapytałem go: „Ej, dlaczego w odpowiedzi tego API widać hasło i nawet numer identyfikacyjny?”
Odpowiedział zupełnie swobodnie: „A, to? Przecież na ekranie i tak wyświetlamy tylko imię. Nie chciało mi się tego rozdzielać, więc po prostu zwróciłem wynik userRepository.findAll() wprost. Jest w tym jakiś problem?”
Przeszedł mnie dreszcz. On chciał tylko wygody, ale w praktyce zasiał ziarno poważnego incydentu bezpieczeństwa.
„To, że czegoś nie widać na ekranie, nie znaczy jeszcze, że jest bezpieczne!”
Każdy może zajrzeć do zakładki sieciowej w przeglądarce. A co jeśli złośliwy atakujący wywołałby to API?
Wysyłanie encji na zewnątrz bez żadnych zmian było jak zrobienie ze ściany sypialni w domu jednej wielkiej szyby.

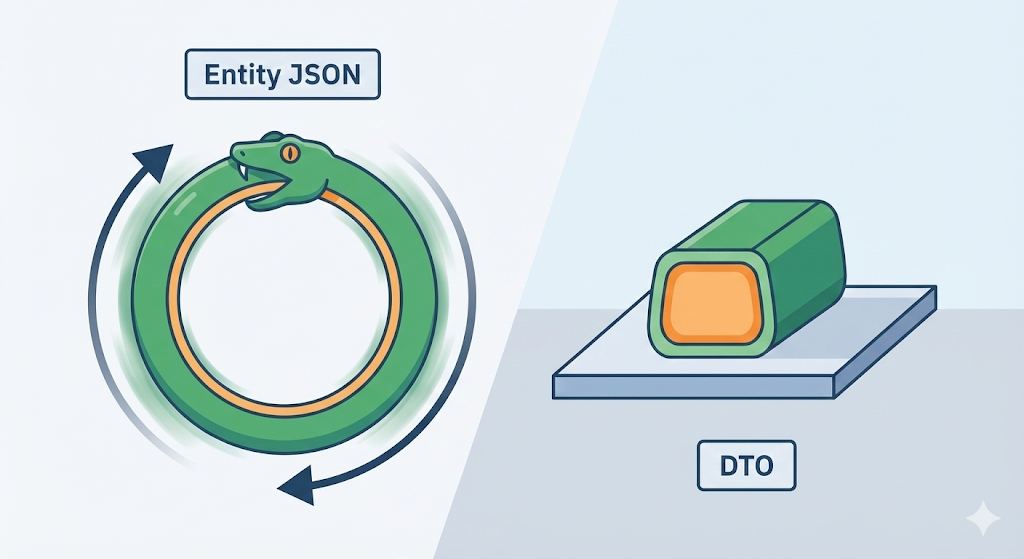
DTO: „opakowanie” dla danych
„Encja(Entity)” to coś w rodzaju „surowca”, z którym pracuje się tylko wewnątrz fabryki. Przylegają do niej rzeczy, których klient nigdy nie powinien zobaczyć, takie jak sekrety (hasła) czy pola do wewnętrznego zarządzania (data utworzenia, data modyfikacji, flaga usunięcia).
Z kolei „DTO(Data Transfer Object)” to „gotowy produkt”, starannie zapakowany do dostarczenia klientowi.
Zwracanie encji bezpośrednio jest jak rzucenie klientowi na talerz zakrwawionego surowego mięsa zamiast podania usmażonego steka. Koniecznie potrzebujemy etapu „mapowania”.
[Code Verification] Bagno nieskończonej pętli (referencja cykliczna)
Jeszcze bardziej niż problemy bezpieczeństwa programistów doprowadza do szału problem „referencji cyklicznych”. Pamiętasz dwukierunkowe mapowanie JPA z poprzedniego odcinka, User <-> Team?
Co się stanie, jeśli zwrócisz encję User bezpośrednio po zamianie jej na JSON?
@Entity
public class User {
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne // Uzytkownik nalezy do zespolu
private Team team;
}
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team") // Zespol ma wielu uzytkownikow
private List<User> users = new ArrayList<>();
}
Jeśli zwrócisz User w takim stanie, serializer JSON (Jackson) zadziała mniej więcej tak.
Wynik: serwer ginie bohaterską śmiercią z StackOverflowError. Relacje między encjami gonią się bez końca, więc jeśli nie przerwiesz tego łańcucha i wystawisz wszystko wprost, wpadasz w nieskończoną pętlę. Właśnie dlatego trzeba użyć DTO i zostawić w nim tylko potrzebne pola, takie jak teamName.
Warunek dobrego API: podejście RESTful
Jeśli dane są już dobrze zapakowane przy pomocy DTO, trzeba jeszcze wybrać odpowiedni „adres”, pod który wyślemy tę paczkę. Właśnie tym jest projektowanie REST API.
Na studiach nadawałem adresom URL nazwy całkowicie po swojemu.
Umieszczanie w URL czasowników takich jak join czy update nie jest dobrym pomysłem. W podejściu RESTful „zasób” (rzeczownik) trafia do URL, a „czynność” (czasownik) zostaje powierzona metodzie HTTP.
Jeśli zrobisz to w ten sposób, już po samym URL widać: „Aha, tu chodzi o zasób użytkownika.” Komunikacja z frontend developerami też staje się wtedy o wiele prostsza. To wspólna umowa, którą rozumieją developerzy na całym świecie.
Praktyczna rada: nazwa robi połowę roboty (strategia nazewnictwa DTO)
Kiedy otwieram kod obecnego projektu firmowego, czasem od razu wzdycham. UserDto, MemberVo, InfoParam, ResultData… poprzednicy nazywali wszystko jak chcieli, więc dopóki nie zajrzysz do środka, nie wiesz, czy obiekt służy do przyjmowania requestu, czy do zwracania response.
DTO to „naczynie” na dane. Jeśli przeznaczenie tego naczynia nie wynika z nazwy, zaczyna się chaos podobny do wkładania ryżu do miski na zupę i wody do miski na ryż. Zasada nazewnictwa, którą najbardziej polecam w praktyce, jest następująca.
public class UserDto {
// Zadanie rejestracji
public static class SignUpRequest {
private String email;
private String password;
}
// Odpowiedz z danymi uzytkownika
public static class Response {
private String name;
private String email;
}
}
Na koniec serii 2: dom jest już zbudowany
Tym samym kończy się seria [Monolith Builder]. Zbudowaliśmy fundament na Spring Boot (DI), rozdzieliliśmy frontend i backend (CORS), nauczyliśmy się obsługi bazy danych przez JPA, a także komunikacji za pomocą DTO i REST API.
Teraz mamy już umiejętność samodzielnego zbudowania porządnej usługi webowej. Ale podróż developera na tym się nie kończy. Jaki jest pożytek z tego, że usługa działa tylko na moim komputerze, czyli na localhost? Żeby pokazać ją prawdziwym użytkownikom, trzeba wdrożyć ją na serwer.
Tyle że ten serwer to nie Windows, tylko Linux: czarny ekran i nic więcej. Jak bez myszki zainstalować tam programy i je uruchomić?
W następnej serii, [Works on My Machine], wejdźmy do świata Linuksa i Dockera, żeby rozwiązać wieczny problem developerów: „Na mojej maszynie działa, ale na serwerze już nie.”