”Va? Var builden precis klar redan?”
När jag väl hade känt hur bekvämt Docker var, började jag i smyg, utan att min teamlead visste det, flytta över min utvecklingsmiljö till Docker steg för steg. Jag skrev en ritning som kallades Dockerfile och körde kommandot docker build.
Första gången tog det ganska lång tid. Att ladda ner Ubuntu, installera Java och hämta biblioteken, JAR-filerna, till mitt projekt tog ungefär fem minuter. ”Ja, det är väl naturligt att det tar tid första gången.”
Men när jag rättade ett enda litet skrivfel i koden och körde builden igen trodde jag inte mina ögon. Så fort jag tryckte Enter visade terminalen redan Successfully built. Tidsåtgång: bara 0,1 sekunder.
”Vänta, har det gått sönder? Förut tog det ju fem minuter. Hur kan det plötsligt vara klart direkt?”
Jag startade servern lite nervöst, men koden var korrekt uppdaterad. Så vad var det egentligen som hände inne i Docker? Hemligheten bakom den där vansinniga hastigheten låg i ett särskilt lagringssätt som kallas ‘lager’, Layer.
Image och container
Innan vi går in i själva mekanismen ska vi först reda ut två begrepp som ofta blandas ihop.
Det vi skickar till servern vid deployment är inte en ‘container’, utan en ‘image’. Servern behöver bara ta emot den imagen och köra den.
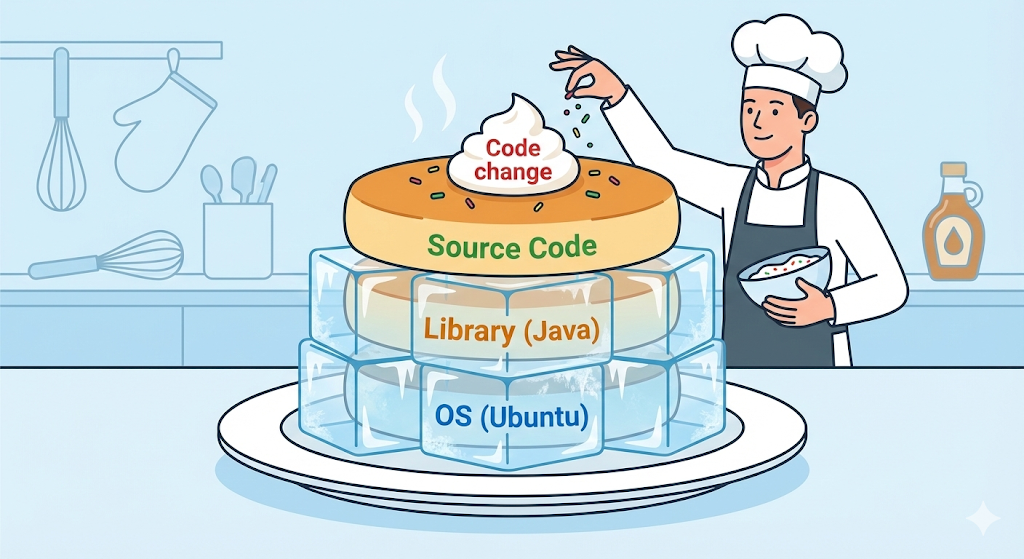
Layer: magin med genomskinlig cellofan
En Docker-image är inte en enda massiv fil. Den liknar snarare flera ark genomskinlig cellofan, layers, som lagts ovanpå varandra. Varje enskild rad instruktion i ett Dockerfile blir ett eget lager.
Ta ett exempel.
# Lager 1: installera Ubuntu (OS)
FROM ubuntu:20.04
# Lager 2: installera Java
RUN apt-get install openjdk-17-jdk
# Lager 3: kopiera min kod
COPY my-app.jar /app/my-app.jar
# Lager 4: kor
CMD ["java", "-jar", "/app/my-app.jar"]
Om man läser igenom innehållet i ett Dockerfile i lugn och ro ser man att strukturen inte är så svår. ”Installera Ubuntu, FROM, installera Java, RUN, ta in min kod, COPY, och kör den, CMD.”
I slutändan har vi alltså bara tagit den serverkonfigurationsprocess som vi tidigare skrev in för hand i en VM eller en serverterminal och skrivit ner den som ett dokument. Med bara det dokumentet utför Docker installationsstegen på egen hand. Det här konceptet hänger senare också ihop med kärnprincipen i CI/CD-automatisering.
Men varför plattar Docker inte bara ut hela processen till ett enda steg? Varför delar den medvetet upp allt rad för rad i lager och staplar dem noggrant?
Svaret är återanvändning, alltså caching. Om jag ändrar koden och bygger igen tänker Docker smart: ”Första våningen, operativsystemet, och andra våningen, Java, är exakt samma som tidigare. Då finns det ingen anledning att bygga om dem. Jag använder bara de tidigare skapade lagren i cache.”
Därefter bygger den bara om från den tredje våning som har ändrats, alltså kopieringen av koden. Det är därför den andra builden var klar på bara 0,1 sekunder.
[Code Verification] Se lagercachen med egna ögon
Låt oss inte nöja oss med att säga det, utan faktiskt verifiera det med kod. Allt du behöver göra är att skapa ett enkelt Dockerfile och bygga två gånger.
FROM alpine:latest
RUN echo "1. Installerar grundverktyg..." && sleep 2 # Tar 2 sekunder
COPY test.txt /app/test.txt
CMD ["cat", "/app/test.txt"]
$ docker build -t my-test:v1 .
# Resultat:
# [2/3] RUN echo "1. Installerar grundverktyg..." ... 2.1s (tog 2s)
$ docker build -t my-test:v2 .
# Resultat:
# [2/3] RUN echo "1. Installerar grundverktyg..." ... CACHED (0s!)
Ser du ordet CACHED tydligt i loggen? Det är beviset för att Docker hoppade över ett arbete som normalt skulle ta två sekunder.
Praktiskt råd: ordningen är allt
När man förstår principen bakom lagercachning blir svaret på hur man ska skriva ett Dockerfile ganska självklart. Kärnan är enkel: ”Lägg det som sällan ändras längre ner, alltså tidigare, och det som ändras ofta högre upp, alltså senare.”
Dåligt exempel:
# 1. Kopiera kallkoden forst (andras ofta)
COPY . .
# 2. Installera bibliotek (andras sallan)
RUN npm install
Källkod ändras dussintals gånger per dag. Om steg 1 ändras ogiltigförklarar Docker även cachen för steg 2, biblioteksinstallationen, och kör om allt. Du rättar en enda rad kod och måste vänta på npm install igen.
Bra exempel:
# 1. Kopiera forst bara package.json
COPY package.json .
# 2. Installera bibliotek (cachas)
RUN npm install
# 3. Kopiera kallkoden
COPY . .
Bara genom att ändra ordningen så här kan buildhastigheten bli tio gånger snabbare. Det är just den skillnaden som skiljer en Docker-nybörjare från någon som verkligen behärskar verktyget.
Praktiskt råd 2: taggar är din livlina
I exemplet ovan skrev jag docker build -t my-test:v1 .. Här är v1 efter kolon, :, taggen.
Många nybörjare hoppar över taggar eftersom de känns jobbiga. Då sätter Docker automatiskt taggen latest.
Denna enda vana att använda taggar kommer att rädda många av dina kvällar längre fram.
Avslutning: att hålla 0,1-sekundersmagin i handen
En Docker-image är inte bara en bunt filer, utan ett tekniskt koncentrat uppbyggt lager för lager för att leverera en miljö så effektivt som möjligt. Om du förstår lagercachning och ordnar ditt Dockerfile rätt kan du skapa en lätt och snabb deploymiljö som bygger klart på 0,1 sekunder.
Nu är allt klart för att perfekt frysa in miljön på min dator som en image och skicka den till servern.
Men när jag faktiskt försökte starta den imagen på servern dök ett nytt problem upp. En webbtjänst körs inte bara med en enda servercontainer. Den behöver också en databas, Redis och en frontendserver.
Går det verkligen att hantera alla dessa containrar genom att starta och stoppa dem en och en med separata kommandon? Hur kommunicerar de med varandra? Hur bygger man en hel applikation bortom en enskild image? Nästa gång ska vi bredda Docker-världsbilden med begreppen containrar, tjänster och stackar.