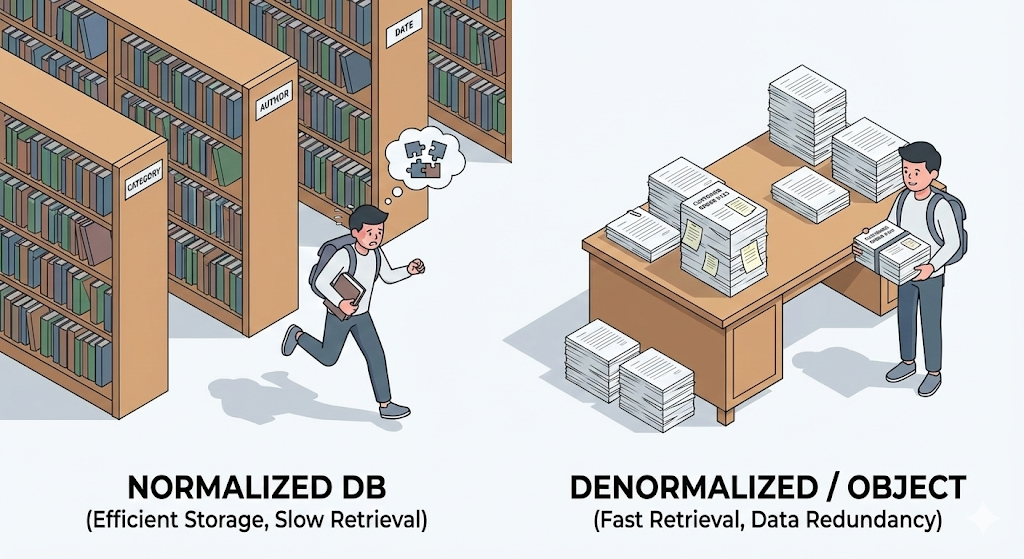
„Datenredundanz ist absolutes Böse“
Im Datenbankunterricht an der Universität betonte unser Professor das so leidenschaftlich, dass ihm fast der Speichel flog. „Erste Normalform, zweite Normalform, dritte Normalform … doppelte Daten verschwenden Speicherplatz und gefährden die Integrität. Zerlegt alles, und dann zerlegt es noch weiter!“
Ich folgte dieser Lehre gewissenhaft. Bei meinem Abschlussprojekt teilte ich die Tabellen in 10, dann 20 kleine Teile auf. „User“, „Address“, „City“, „Zipcode“ … Mein Datenbankdesign war so perfekt „nach Lehrbuch“, dass man für eine einzige Adresse drei Tabellen brauchte.
Doch in der Praxis wurde dieses perfekte Design zur Katastrophe. Ich wollte nur eine Kundenliste abrufen, musste aber fünf JOINs schreiben. Die Abfrage wurde kompliziert, langsam, und schlimmer noch: Der Prozess, diese Daten in Java-Objekte zu übertragen, war unerträglich schmerzhaft.
„Warum ist der Code so kompliziert, obwohl ich doch nur eine einzige Datenzeile für die Anzeige holen will?“
Erst da wurde mir klar: In der Uni hatte man uns beigebracht, wie man das Speichern optimiert. In der Praxis ist aber das Lesen viel wichtiger. Und zwischen einer objektorientierten Sprache wie Java und einer relationalen Datenbank fließt ein Fluss, der viel schwerer zu überqueren ist, als ich gedacht hatte.
Paradigmenkonflikt: Quadrat und Kreis
Die eigentliche Ursache unseres Schmerzes ist ein sogenannter Impedance Mismatch, also ein Paradigmenkonflikt.
Damals im Studium habe ich versucht, diese beiden Welten gewaltsam zusammenzuzwingen, indem ich SQL direkt geschrieben habe. Ich zerlegte Java-Objekte, speicherte sie per INSERT in der Datenbank, holte sie mit SELECT wieder heraus, las sie Zeile für Zeile aus dem ResultSet und übertrug sie mühsam in Java-Collections wie Set oder List. Ich fühlte mich nicht wie ein Entwickler, sondern wie ein Datenübersetzer.
Genau zur Lösung dieser ermüdenden Wiederholungsarbeit erschien JPA (Java Persistence API), also die Welt von ORM (Object-Relational Mapping).
JPA und ORM: Datenbanken über Objekte steuern
ORM ist ganz wörtlich eine Technik, die Objekte und relationale Datenbanken miteinander verknüpft. Wie der Name schon sagt, besteht die zentrale Idee darin, Datenbanktabellen so zu definieren und zu behandeln, als wären sie Java-Objekte.
Wir müssen keine CREATE TABLE-Abfragen mehr selbst schreiben. Stattdessen erstellen wir eine Java-Klasse und kleben ihr einen Aufkleber namens @Entity auf. Dann schaut JPA, der Java-Standard für ORM, auf diese Klasse und denkt sich: „Aha, so soll also die Tabelle aussehen“, und erzeugt sie automatisch in der Datenbank.
Auch beim Speichern hören wir auf, SQL von Hand zu schreiben. Stattdessen genügt so etwas wie repository.save(member), fast so, als würde man etwas in eine Java-Collection legen. Der Entwickler bleibt vollständig in der objektorientierten Denkwelt, und die schmutzige SQL-Übersetzungsarbeit wird an JPA delegiert.
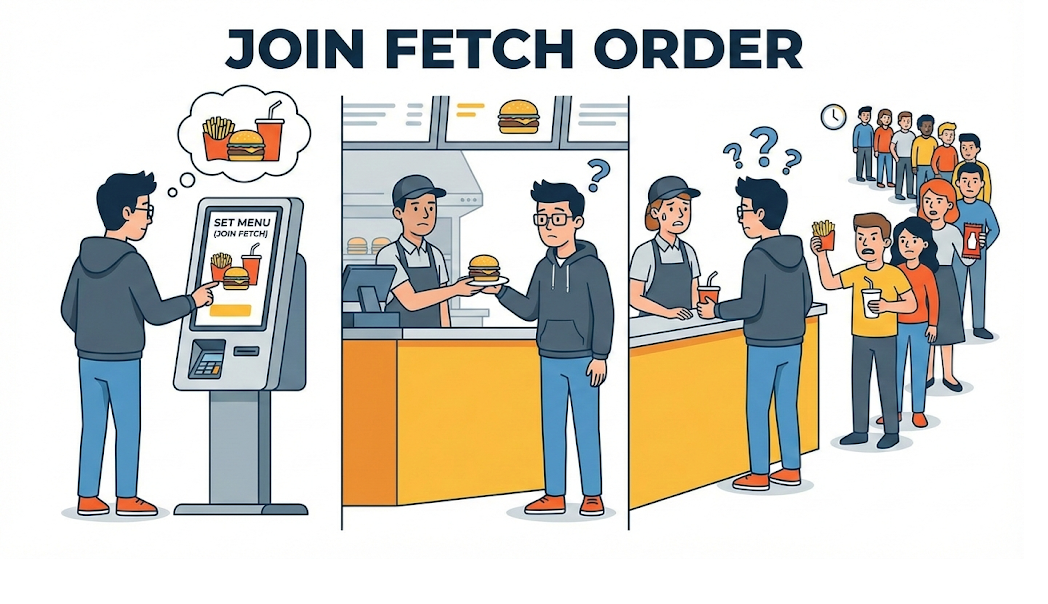
Aber wie wir schon in der Re: Booting-Serie gelernt haben, hat Bequemlichkeit immer ihren Preis. Weil ich diesem automatischen Übersetzer namens JPA zu sehr vertraute, baute ich mir eine tickende Zeitbombe in den Code ein: das N+1-Problem.
[Code Verification] Das N+1-Problem, eine Abfragebombe
Das ist ein Problem, das praktisch jeder Junior-Entwickler erlebt, wenn er zum ersten Mal mit JPA arbeitet. Die Situation ist einfach: „Gib alle Mitglieder zusammen mit dem Namen des Teams aus, zu dem sie gehören.“
// 1. Alle Mitglieder abrufen (1 Abfrage abgesetzt)
List<Member> members = memberRepository.findAll();
for (Member member : members) {
// 2. Teamnamen jedes Mitglieds ausgeben
// Bei 100 Mitgliedern werden 100 zusaetzliche Abfragen fuer die Teaminfos ausgefuehrt!
System.out.println(member.getTeam().getName());
}
Die erwartete Abfrage: SELECT * FROM Member JOIN Team ... (genau einmal)
Die tatsächlich ausgeführten Abfragen:
Wenn es 100 Mitglieder gibt, schickt die Anwendung 101 Abfragen an die Datenbank: 1 + N. Bei 10.000 Mitgliedern? Dann prasseln 10.001 Abfragen auf die Datenbank ein. Genau das ist das berüchtigte N+1-Problem, also die Art von Problem, die einen Server in die Knie zwingen kann. JPA wollte es bequem machen und Daten „bei Bedarf“ lazy laden, und gerade diese Bequemlichkeit wurde zur Katastrophe.
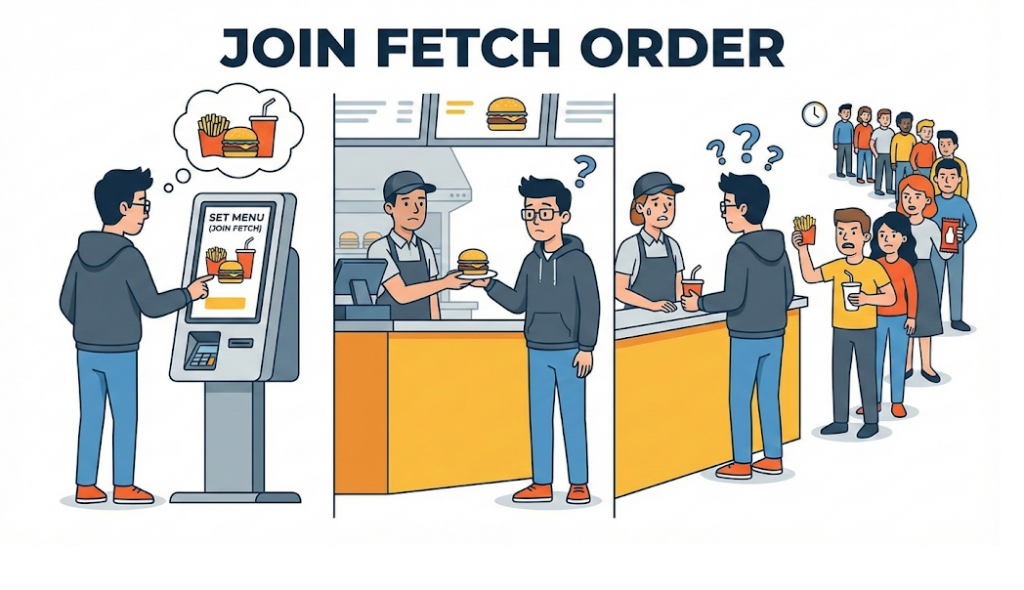
Praxisrat: pragmatisches Datenbankdesign
Wie sollte man also in der Praxis vorgehen? Man muss ein Gleichgewicht finden zwischen lehrbuchhafter Normalisierung und der Bequemlichkeit von JPA.
Zum Schluss: Mehr Bequemlichkeit verlangt mehr Wissen
JPA ist ohne Zweifel eine Revolution. Es hat uns von der zermürbenden Wiederholung befreit, ständig wieder SQL schreiben zu müssen. Aber zu denken „Ich benutze jetzt JPA, also brauche ich SQL nicht mehr zu verstehen“ ist gefährlich.
JPA ist kein Zauberer. Es ist nur ein Sekretär, der für mich SQL schreibt. Wenn ich diesem Sekretär schlechte Anweisungen gebe, durch falsches Mapping, EAGER Loading und so weiter, dann feuert er stillschweigend hundert Abfragen ab und legt die Datenbank lahm. Um zu überwachen und zu optimieren, ob die von JPA erzeugten SQL-Abfragen wirklich effizient sind, muss man paradoxerweise SQL noch besser verstehen. Bequemlichkeit bringt immer Verantwortung mit sich.
Jetzt wissen wir, wie man Daten in Objekte packt. Aber können wir diese Objekte, also die Entities, einfach direkt an das Frontend, an Vue.js, senden? Was ist, wenn die User-Entity ein Passwort enthält? Und was passiert mit der Sicherheit, wenn wir dem Frontend Informationen geben, die es nie sehen sollte?
Nächstes Mal sprechen wir über DTOs, Data Transfer Objects, und über REST-API-Design, also über Techniken, mit denen Daten sicher verpackt und ausgeliefert werden.