Wissen wie eine einminütige Selbstvorstellung im Vorstellungsgespräch
„Was ist der Unterschied zwischen einem Prozess und einem Thread?“
Als ich noch auf Jobsuche war, stand diese Frage stets in den „Top 10 der klassischen Interviewfragen“. Ich antwortete wie eine Maschine.
„Ein Prozess ist ein laufendes Programm, und ein Thread ist eine Ausführungseinheit, die innerhalb eines Prozesses abläuft. Prozesse teilen sich keine Ressourcen, Threads hingegen schon.“
Der Interviewer nickte, und ich bildete mir ein, dieses Konzept perfekt verstanden zu haben. Doch bevor ich in der Praxis auf echte „Concurrency Issues“ stieß, hatte ich keine Ahnung, welcher wahre Schrecken in diesem Satz steckt.
„Warum steigen die Aufrufzahlen nur um 98, wenn sie eigentlich um 100 steigen sollten?“ „Warum bleibt die gesamte Website stehen, sobald jemand einen Excel-Download startet?“
Mein Code war einwandfrei, solange ich ihn allein ausführte. Doch sobald mehrere Nutzer gleichzeitig zugriffen, wurde er zum Chaos. Ich dachte, das Problem löse sich einfach dadurch, mehr „Arbeiter“ einzusetzen – aber mir war nicht bewusst, dass mit jeder zusätzlichen Arbeitskraft die Kosten für deren Verwaltung (Context Switching) exponentiell steigen.

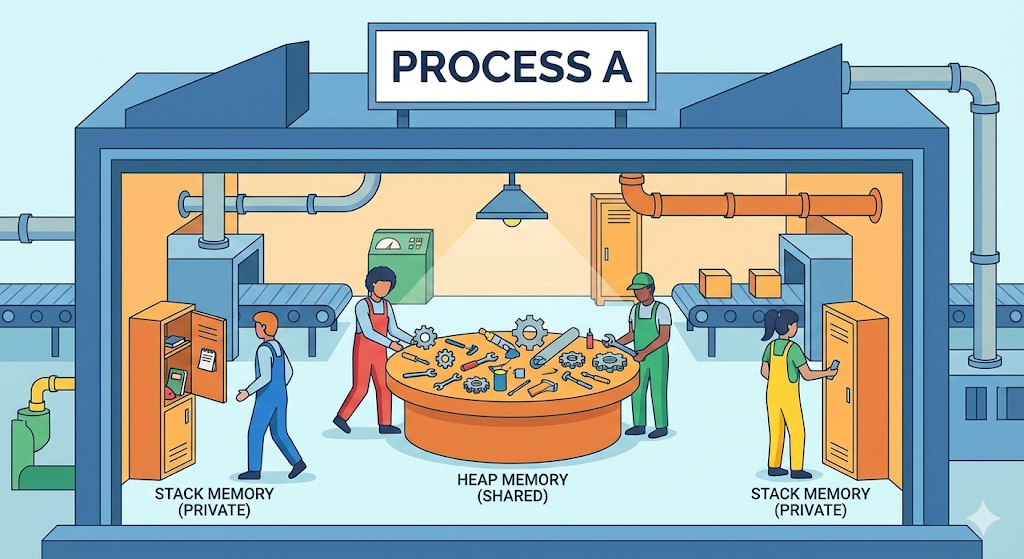
Fabrik und Arbeiter im digitalen Logistikzentrum
Kehren wir zu unserem gedanklichen Modell des „digitalen Logistikzentrums“ zurück. Ein Programm auf einem Computer auszuführen, entspricht dem Aufbau einer „Fabrik“ innerhalb dieses Logistikzentrums.
1. Prozess: Eine unabhängige Fabrik
2. Thread: Die Arbeiter in der Fabrik
[Code-Verifikation] Die Tragödie des Teilens (Nebenläufigkeitsproblem)
„Threads teilen sich Ressourcen.“ Im Vorstellungsgespräch klingt das wie ein Vorteil, doch in der Praxis kann es der Keim einer Katastrophe sein.
Erinnern Sie sich an den „Heap“, den wir beim letzten Mal kennengelernt haben? Threads teilen sich diesen Heap-Bereich. Das bedeutet: Thread B kann einfach vorbeikommen und die Daten überschreiben, an denen Thread A gerade arbeitet.
Genau das nennt man eine „Race Condition“. Überprüfen wir es mit Code.
public class RaceConditionTest {
static int count = 0; // Gemeinsame Variable, die im Heap gespeichert wird
public static void main(String[] args) throws InterruptedException {
// Zwei Arbeiter (Threads) einstellen
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) count++;
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) count++;
});
t1.start(); // Arbeit starten!
t2.start(); // Arbeit starten!
t1.join(); // Warten, bis sie Feierabend machen
t2.join(); // Warten, bis sie Feierabend machen
System.out.println("Endergebnis: " + count);
}
}
Erwartetes Ergebnis: Zwei Personen haben jeweils 10.000 Mal addiert, also sollte das Ergebnis 20.000 betragen.
Tatsächliches Ergebnis: 15.482, 18.931… Der Wert ist bei jedem Durchlauf anders, und 20.000 wird nie erreicht.
Grund:
Genau das steckt hinter jenen Produktionsfehlern, bei denen „manchmal einfach Daten verschluckt werden“. Eine Tragödie, die entsteht, wenn Arbeiter ohne jede Absprache dasselbe Buchungsbuch bearbeiten.
Übertragen auf eine Datenbank (DB) entspricht diese Situation exakt einer Lage, in der „mehrere Queries gleichzeitig ohne Transaktion abgesetzt werden“. Werden Kontostände ohne Schutzvorrichtung (Lock) gleichzeitig geändert, kommt es zum Horrorszenario, in dem Geld einfach verschwindet. So wie wir in der Datenbank mit ROLLBACK oder COMMIT Daten schützen, brauchen wir auch auf Code-Ebene zwingend ein Sperrmechanismus wie Synchronized.
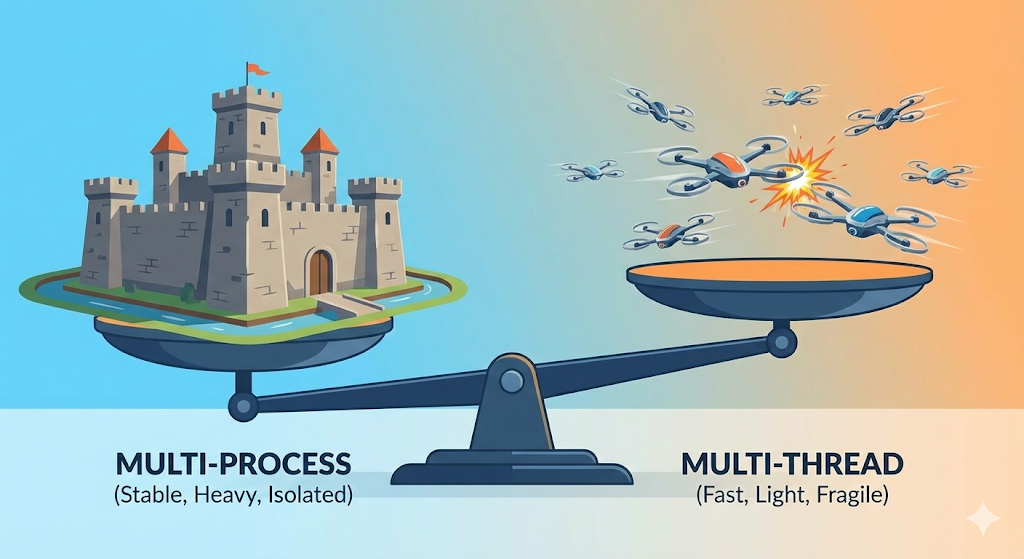
Trade-off in der Praxis: Multi-Prozess vs. Multi-Thread
Wann sollte man in der Praxis also was verwenden?
1. Die Wahl des Chrome-Browsers: Multi-Prozess
Beim alten Internet Explorer stürzte der gesamte Browser ab, sobald ein einziger Tab hängen blieb (Multi-Thread-Ansatz). Chrome hingegen startet jeden Tab als eigenen „separaten Prozess (Fabrik)“.
2. Die Wahl von Webservern (Spring, Node.js usw.): Multi-Thread
Ein Server muss tausende Anfragen gleichzeitig verarbeiten. Würde man für jede Anfrage einen eigenen Prozess (Fabrik) starten, käme der Server an seine Grenzen. Deshalb werden innerhalb eines einzigen Prozesses zahlreiche Threads (Arbeiter) verwendet, um die Last abzuarbeiten.
Zum Abschluss: Schattendoppelgänger bringen Verantwortung mit sich
Heute haben wir uns die Arbeitsweise unserer Arbeiter angesehen – die Welt der „Prozesse und Threads“.
Jetzt wissen Sie, dass der Begriff „Concurrency Issue“ keineswegs nur Interview-Jargon ist. Im gemeinsamen Lager namens Heap strömen zahllose Thread-Arbeiter pausenlos ein und aus. In diesem Chaos Ordnung zu schaffen – genau das ist die eigentliche Stärke eines Backend-Entwicklers.
Aber Moment: Wie wird eigentlich entschieden, wessen Arbeit zuerst erledigt wird, wenn es so viele Arbeiter gibt? Wie verwaltet der Fabrikleiter (das Betriebssystem) hunderte von Arbeitskräften? Beim nächsten Mal sprechen wir über die wohl kopfzerbrechendste Aufgabe des Fabrikleiters: „Scheduling und Context Switching“.