Des connaissances comme une présentation d’une minute en entretien
« Quelle est la différence entre un processus et un thread ? »
À l’époque où je cherchais un emploi, cette question figurait systématiquement dans le « Top 10 des questions d’entretien classiques ». Je répondais comme une machine.
« Un processus est un programme en cours d’exécution, et un thread est une unité de flux qui s’exécute à l’intérieur d’un processus. Les processus ne partagent pas leurs ressources, mais les threads, eux, les partagent. »
L’intervieweur hochait la tête et j’étais persuadé d’avoir parfaitement compris le concept. Pourtant, tant que je ne m’étais pas heurté à un véritable « problème de concurrence » en production, je n’avais aucune idée de la véritable menace contenue dans cette phrase.
« Pourquoi le nombre de vues est censé augmenter de 100, mais il n’augmente que de 98 ? » « Pourquoi le site web entier se fige dès que quelqu’un lance un téléchargement Excel ? »
Mon code était parfait lorsque je l’exécutais seul, mais il devenait un désastre dès que plusieurs utilisateurs s’y connectaient simultanément. Je pensais qu’il suffisait d’ajouter des « travailleurs » pour résoudre le problème, mais j’ignorais que plus les travailleurs sont nombreux, plus le coût de leur gestion (Context Switching) augmente de façon exponentielle.

L’usine et les ouvriers du centre logistique numérique
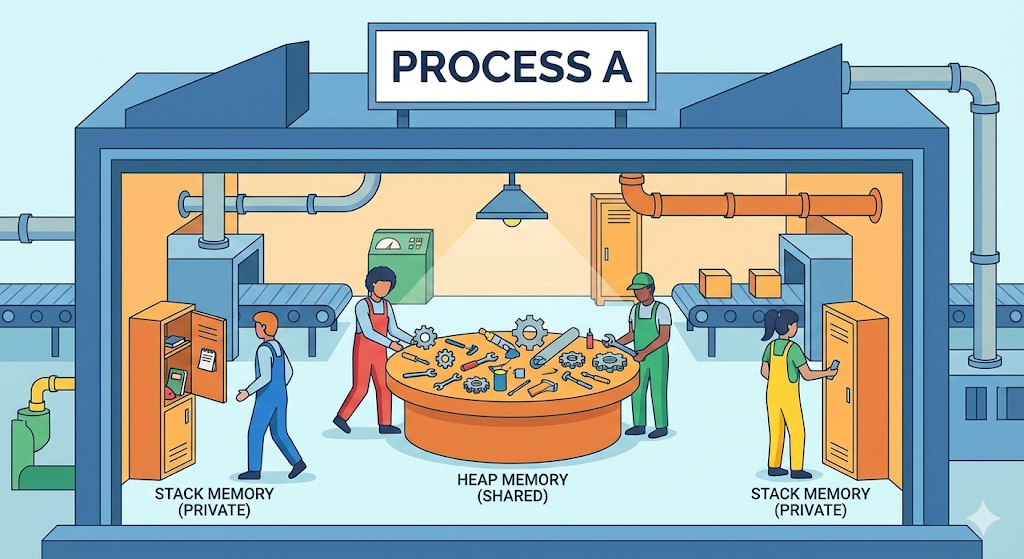
Revenons à notre vision du « centre logistique numérique ». Exécuter un programme dans un ordinateur, c’est comme installer une « usine » à l’intérieur du centre logistique.
1. Processus : un atelier indépendant
2. Thread : les ouvriers à l’intérieur de l’atelier
[Vérification par le code] La tragédie du partage (problème de concurrence)
« Les threads partagent les ressources. » Dans une salle d’entretien, cela sonne comme un avantage, mais en production, cela peut être la graine d’une véritable catastrophe.
Vous vous souvenez du « Heap » que nous avons étudié la dernière fois ? Les threads partagent cette zone du heap. Autrement dit, le thread B peut très bien venir écraser les données sur lesquelles le thread A est en train de travailler.
C’est ce qu’on appelle une « Race Condition ». Vérifions-le avec du code.
public class RaceConditionTest {
static int count = 0; // Variable partagee stockee dans le Heap
public static void main(String[] args) throws InterruptedException {
// Embaucher deux travailleurs (threads)
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) count++;
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) count++;
});
t1.start(); // Demarrer le travail !
t2.start(); // Demarrer le travail !
t1.join(); // Attendre qu ils aient fini leur journee
t2.join(); // Attendre qu ils aient fini leur journee
System.out.println("Resultat final : " + count);
}
}
Résultat attendu : Deux personnes ayant additionné chacune 10 000 fois, le résultat devrait être 20 000.
Résultat réel : 15 482, 18 931… La valeur change à chaque exécution, et 20 000 ne s’affiche jamais.
Raison :
Voilà la véritable identité de ces bugs où, en production, « les données se perdent de temps en temps ». C’est la tragédie de plusieurs ouvriers qui touchent au même registre sans jamais se parler.
Pour faire une analogie avec une base de données (BDD), cette situation est exactement équivalente à « plusieurs requêtes envoyées simultanément sans transaction ». Si l’on modifie le solde d’un compte bancaire en parallèle, sans dispositif de protection (Lock), on obtient le scénario catastrophe où l’argent s’évapore. Tout comme nous protégeons les données dans la BDD avec ROLLBACK ou COMMIT, un mécanisme de verrouillage tel que Synchronized est absolument indispensable au niveau du code.
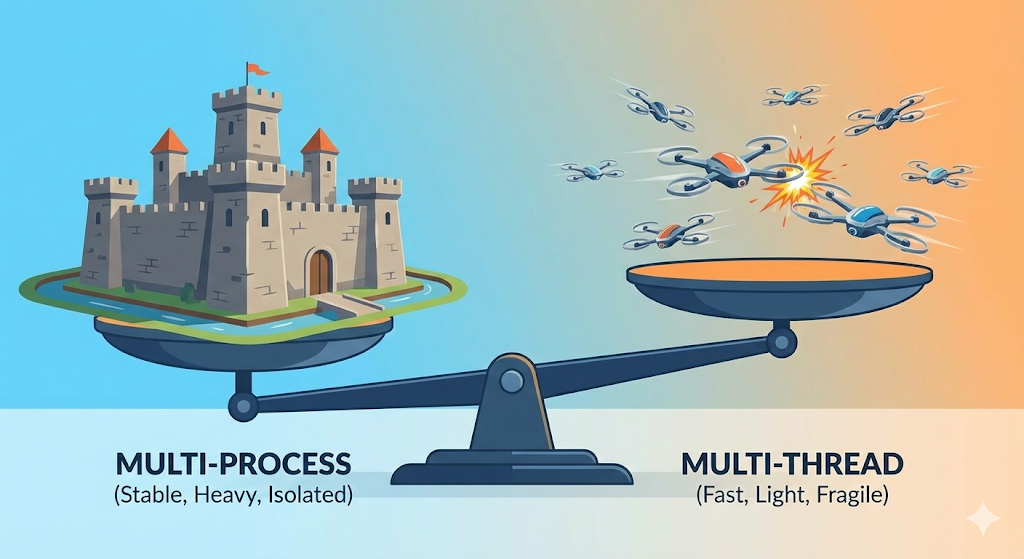
Compromis en pratique : multi-processus vs multi-thread
Alors, en pratique, quand faut-il utiliser quoi ?
1. Le choix du navigateur Chrome : multi-processus
Autrefois, avec Internet Explorer, lorsqu’un onglet se bloquait, c’était tout le navigateur qui se fermait (approche multi-thread). Chrome, en revanche, lance chaque onglet comme un « processus distinct (usine) ».
2. Le choix des serveurs web (Spring, Node.js, etc.) : multi-thread
Un serveur doit traiter des milliers de requêtes. Créer un processus (usine) pour chaque requête ferait exploser le serveur. C’est pourquoi on conserve un seul processus dans lequel on place de très nombreux threads (ouvriers) pour absorber la charge.
Pour conclure : le clonage implique une responsabilité
Aujourd’hui, nous avons examiné la manière dont travaillent nos ouvriers : les « processus et threads ».
Vous comprenez désormais que l’expression « problème de concurrence » n’est pas qu’un jargon d’entretien. Dans l’entrepôt partagé qu’est le Heap, d’innombrables threads-ouvriers entrent et sortent sans relâche. Mettre de l’ordre dans ce chaos, c’est précisément là que se révèle le savoir-faire d’un développeur back-end.
Mais attendez : lorsque les ouvriers sont nombreux, comment décide-t-on de qui doit effectuer quel travail en premier ? Comment le chef d’usine (l’OS) gère-t-il des centaines d’ouvriers ? La prochaine fois, nous aborderons la tâche la plus épineuse du chef d’usine : « l’ordonnancement et le changement de contexte (Context Switching) ».