« La duplication de données est un mal absolu »
En cours de base de données à l’université, le professeur insistait avec tant d’énergie qu’il en postillonnait presque. « Première forme normale, deuxième forme normale, troisième forme normale… les données dupliquées gaspillent de l’espace de stockage et nuisent à l’intégrité. Découpez, puis découpez encore ! »
J’ai suivi cet enseignement avec sérieux. Lors de mon projet de fin d’études, j’ai morcelé les tables en 10, puis 20 morceaux. ‘User’, ‘Address’, ‘City’, ‘Zipcode’… Mon schéma de base de données était si parfaitement « scolaire » qu’il fallait trois tables rien que pour enregistrer une seule adresse.
Mais dans la pratique, ce design parfait est devenu une catastrophe. Je voulais simplement récupérer une liste de clients, et je devais déjà enchaîner cinq JOIN. La requête devenait compliquée, les performances chutaient, et surtout, transférer ces données dans des objets Java était extrêmement douloureux.
« Je veux juste récupérer une ligne de données à afficher à l’écran. Pourquoi le code devient-il aussi complexe ? »
C’est à ce moment-là que j’ai compris. À l’université, on nous enseignait l’efficacité du stockage. Dans le travail réel, l’efficacité de la lecture est bien plus importante. Et entre un langage orienté objet comme Java et une base de données relationnelle coule une rivière bien plus difficile à traverser que je ne l’imaginais.
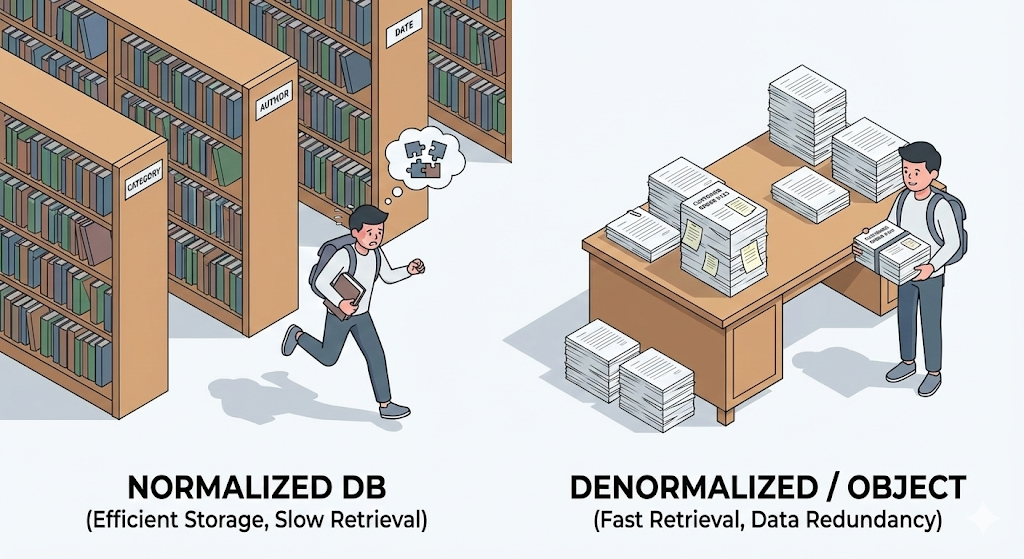
Inadéquation de paradigmes : des carrés et des cercles
La cause fondamentale de cette souffrance est ce qu’on appelle un décalage de paradigme, ou Impedance Mismatch.
À l’université, je forçais ces deux mondes à cohabiter en écrivant moi-même le SQL. Je démontais les objets Java pour les stocker dans la base avec des INSERT, puis je les récupérais avec des SELECT, lisais chaque ligne d’un ResultSet et les recasais une par une dans des collections Java comme Set ou List. Je ne me sentais pas comme un développeur, mais comme un traducteur de données.
La technologie apparue pour résoudre ce travail répétitif et épuisant, c’est justement JPA (Java Persistence API), autrement dit l’univers de l’ORM (Object-Relational Mapping).
JPA et ORM : manipuler la base via les objets
ORM, au sens littéral, est une technologie qui relie les objets et les bases relationnelles. Comme son nom l’indique, l’idée centrale est de définir et de manipuler les tables de la base de données comme s’il s’agissait d’objets Java.
Nous n’avons plus besoin d’écrire à la main des requêtes CREATE TABLE. À la place, nous créons une classe Java et lui collons une étiquette appelée @Entity. JPA, le standard ORM de Java, observe alors cette classe et se dit : « Ah, c’est cette forme de table qu’il te faut », puis la crée automatiquement dans la base de données.
Enregistrer des données ne consiste plus non plus à écrire du SQL à la main. Il suffit d’un repository.save(member), presque comme si l’on ajoutait un élément dans une collection Java. Le développeur reste entièrement dans une logique orientée objet, tandis que le sale travail de traduction en SQL est délégué à JPA.
Mais, comme nous l’avons appris dans la série Re: Booting, la commodité a toujours un prix. Et parce que j’ai trop fait confiance à ce traducteur automatique nommé JPA, j’ai fini par installer une bombe à retardement dans mon propre code : le problème N+1.
[Code Verification] Le problème N+1, une bombe de requêtes
C’est un problème auquel se heurte pratiquement tout développeur junior lors de ses premiers pas avec JPA. La situation est simple : « Affiche tous les membres ainsi que le nom de l’équipe à laquelle ils appartiennent. »
// 1. Recuperer tous les membres (1 requete emise)
List<Member> members = memberRepository.findAll();
for (Member member : members) {
// 2. Afficher le nom d equipe de chaque membre
// Avec 100 membres, 100 requetes supplementaires sont emises pour recuperer les equipes !
System.out.println(member.getTeam().getName());
}
La requête attendue : SELECT * FROM Member JOIN Team ... (une seule fois)
Les requêtes réellement exécutées :
S’il y a 100 membres, l’application envoie 101 requêtes : 1 + N. Et s’il y en a 10 000 ? Alors 10 001 requêtes s’abattent sur la base de données. Voilà ce qu’est le célèbre problème N+1, le genre de problème capable de faire tomber un serveur. JPA voulait être pratique en chargeant les données liées « au moment où on en a besoin », en mode lazy. Et c’est précisément cette commodité qui a tourné à la catastrophe.
Conseil pratique : un design de base de données pragmatique
Alors, comment faut-il faire en pratique ? Il faut trouver un équilibre entre la normalisation de manuel et le confort apporté par JPA.
Pour conclure : plus de confort exige plus de connaissances
JPA est clairement une révolution. Elle nous a libérés de la répétition épuisante du SQL écrit à la main. Mais penser « puisque j’utilise JPA, je n’ai plus besoin de connaître SQL » est dangereux.
JPA n’est pas un magicien. C’est simplement un secrétaire qui écrit du SQL à votre place. Si vous donnez de mauvaises instructions à ce secrétaire, via un mauvais mapping, du chargement EAGER et autres, ce secrétaire enverra silencieusement cent requêtes et finira par tuer la base de données. Pour surveiller et optimiser l’efficacité réelle du SQL généré par JPA, il faut, de façon paradoxale, connaître encore mieux SQL. Le confort s’accompagne toujours de responsabilité.
Nous savons maintenant comment placer des données dans des objets. Mais peut-on envoyer ces objets, ces entities, tels quels au frontend, par exemple à Vue.js ? Et si l’entity User contenait un mot de passe ? Et que devient la sécurité si l’on finit par envoyer au frontend des informations qu’il n’aurait jamais dû voir ?
La prochaine fois, parlons des DTO, Data Transfer Objects, et de la conception des API REST, autrement dit des techniques qui permettent d’emballer les données avant de les livrer proprement et en sécurité.