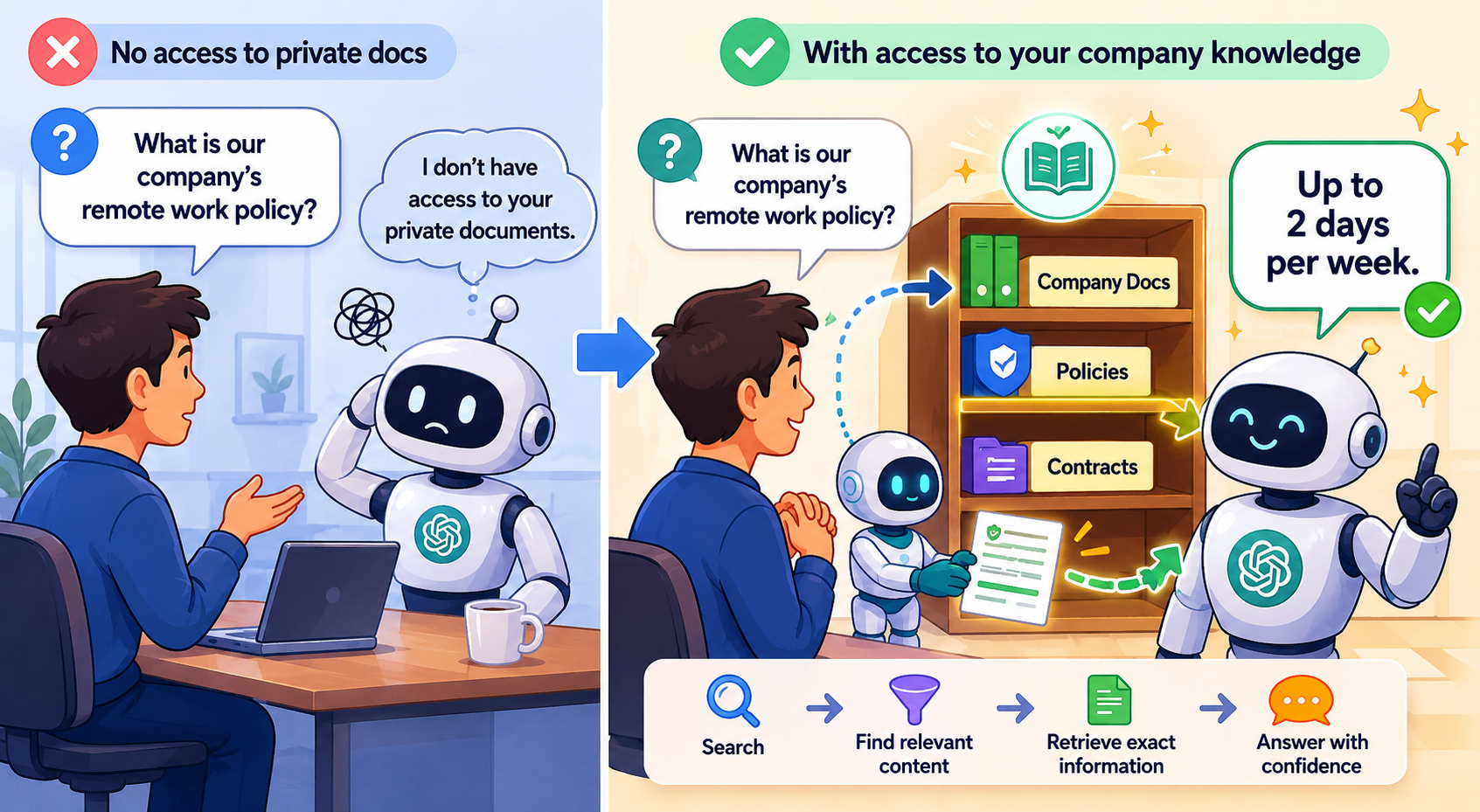
“우리 회사 규정 좀 알려줘”를 AI가 못 하는 이유
ChatGPT는 세계의 많은 것을 알고 있다. 역사, 과학, 일반 지식, 프로그래밍. 그런데 아래 같은 질문은 못 한다.
- “우리 회사 규정상 재택근무 가능 일수가 며칠이야?”
- “내가 어제 쓴 이 프로젝트 문서 요약해줘.”
- “이 PDF 계약서에서 위약금 관련 조항 찾아줘.”
이유는 단순하다. 기본 LLM은 ‘학습 과정에서 본 데이터’와 ‘현재 입력으로 받은 정보’만 바탕으로 답한다. 회사 규정, 내 개인 문서, 사내 데이터베이스처럼 모델 학습에도 없고 현재 대화에도 제공되지 않은 자료는 알 수 없다.
이전 글에서 이 문제의 한 가지 해법으로 ‘외부 도구 연결(함수 호출, MCP)’을 다뤘다. 이 글에서 다룰 ‘RAG’는 같은 문제에 대한 또 다른 패턴이다. 질문과 관련된 자료를 ‘먼저 검색해서’ AI에게 보여준 뒤 답하게 만드는 방식이다.
RAG는 함수 호출이나 MCP의 경쟁 개념이 아니다. ‘외부 자료를 검색해서 컨텍스트에 넣는 패턴’ 자체를 부르는 이름에 가깝다. 이 검색기를 직접 만들 수도 있고, 함수 호출 도구로 붙일 수도 있고, OpenAI File Search나 Gemini File Search 같은 관리형 기능으로 쓸 수도 있다.
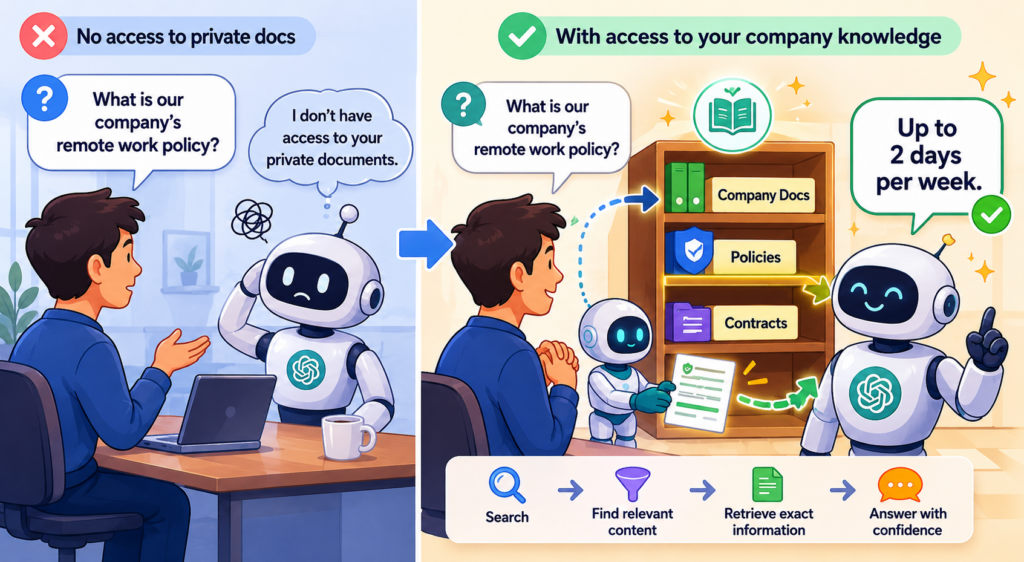
RAG가 뭔가: 검색 + 생성
‘한 줄 요약: 질문에 답하기 전에 관련된 자료를 먼저 찾아서 AI에게 보여주고, 그걸 보고 답하게 만드는 방식이다.’
RAG(Retrieval-Augmented Generation)는 이름을 그대로 풀면 ‘검색으로 증강된 생성’이다. 말이 어렵지만 구조는 간단하다.
기존 방식:
사용자 질문 → AI → 답변 (AI가 아는 것만 가지고)
RAG 방식:
사용자 질문
↓
내 자료 중에서 관련 문서 검색
↓
"이 문서들을 참고해서 답해줘" + 원래 질문
↓
AI → 답변 (내 자료를 참고한 상태로)
핵심은 ‘AI에게 답을 시키기 전에, 관련 정보를 먼저 찾아서 주는 것’이다. AI는 자기 기억에 있는 일반 지식 대신(또는 더해서) 그 자료를 보고 답한다.
이 글에서는 가장 흔한 형태인 ‘벡터 검색 기반 RAG’를 중심으로 설명한다. 다만 RAG가 반드시 벡터 DB를 써야 하는 것은 아니다. 키워드 검색, SQL, 검색 엔진, 그래프 DB도 ‘관련 자료를 찾아 모델에 제공한다’는 목적을 만족하면 RAG의 일부가 될 수 있다.
왜 그냥 “자료 전체”를 AI에게 주면 안 돼?
‘한 줄 요약: 자료가 많으면 한 번에 다 못 넣고, 넣어도 비싸고 느리고 AI가 중간을 놓친다.’
“RAG 말고 그냥 회사 문서 전체를 AI 프롬프트에 넣으면 되는 거 아닌가?”라는 생각이 들 수 있다. 이론적으론 가능하지만, 현실에선 세 가지 문제가 있다.
| 문제 | 설명 |
|---|---|
| 컨텍스트 한계 | 아무리 큰 모델도 한 번에 넣을 수 있는 양에 제한이 있다 |
| 비용과 속도 | 입력 토큰이 많을수록 비싸지고 느려진다 |
| 품질 저하 | 이전 글에서 말한 ‘context rot’ — 입력이 길어지면 AI가 중간 부분을 놓친다 |
RAG는 “모든 문서를 다 넣지 말고, 질문과 관련된 일부만 찾아서 넣자”는 접근이다.
또 다른 선택지로 ‘파인튜닝(fine-tuning)’이 있다. 모델을 내 데이터로 추가 학습시키는 방법이다. 파인튜닝은 모델의 답변 스타일, 출력 형식, 특정 작업 수행 방식을 안정화하는 데 유용하다. 반면 자주 바뀌는 지식이나 출처가 필요한 문서 기반 답변에는 RAG가 더 적합한 경우가 많다. 둘은 경쟁 관계라기보다 함께 쓰이기도 한다. 예를 들어 RAG로 최신 근거를 가져오고, 파인튜닝으로 답변 스타일이나 판단 방식을 다듬는 식이다.
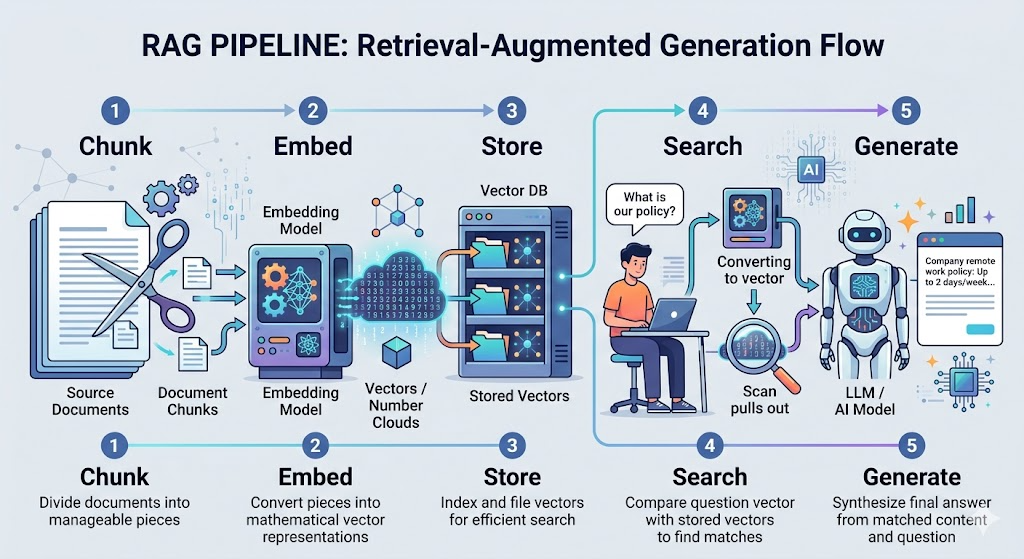
RAG의 5단계 파이프라인
‘한 줄 요약: 문서를 작게 쪼개 → 의미로 저장 → 질문과 관련된 조각 검색 → AI에게 전달 → 답 생성.’
RAG 시스템은 보통 다섯 단계로 돌아간다. 앞의 세 단계는 ‘자료를 준비하는 단계'(인덱싱), 뒤의 두 단계는 ‘질문이 들어올 때마다 돌아가는 단계'(질의)다.
준비 단계: 자료를 검색 가능하게 만들기
[1단계] 문서를 작게 쪼갠다 (청킹, Chunking) - PDF 100페이지 → 500~1000자 정도의 조각 수십~수백 개로 분할 [2단계] 각 조각을 "의미 벡터"로 변환한다 (임베딩, Embedding) - 글의 의미를 숫자 배열(예: 1536개의 숫자)로 표현 - 비슷한 의미의 글은 비슷한 벡터 값을 가짐 [3단계] 벡터를 특수한 DB에 저장한다 (벡터 DB) - 나중에 "이 질문과 비슷한 의미의 조각 찾아줘" 할 수 있게
질의 단계: 사용자 질문이 들어올 때마다
[4단계] 질문을 같은 방식으로 벡터로 만들어 가장 비슷한 조각들을 검색 - 예: 질문과 가장 가까운 조각 5개 찾기 [5단계] 찾은 조각들을 AI 프롬프트에 붙여서 답변 생성 - "다음 문서를 참고해서 답해줘: [조각1] [조각2] [조각3]..." - "질문: [사용자 원본 질문]" → AI가 그 조각들을 근거로 답변 생성
이게 RAG의 전체 모습이다. 용어가 낯설 뿐 흐름 자체는 도서관에서 책 찾는 것과 비슷하다. 책을 주제별 인덱스로 정리해두고(준비), 질문이 오면 관련 책을 꺼내와서(검색) 참고해 답한다(생성).
핵심 개념 쉽게 정리
‘한 줄 요약: 청킹은 “자료 쪼개기”, 임베딩은 “의미를 숫자로”, 벡터 DB는 “의미로 검색 가능한 저장소”.’
위에서 나온 용어들을 조금 더 풀어보자.
청킹 (Chunking): 어떻게 쪼갤까
문서 전체를 한 덩어리로 넣으면 검색 정확도가 낮다. 예를 들어 100페이지 보고서 중에 “재택근무 관련 조항”이 1페이지에만 있는데, 전체가 한 덩어리면 질문과 관련도가 희석된다.
그래서 적당한 크기로 쪼갠다. 청크 크기에는 ‘정답’이 없다. 500~1000자 또는 512~800토큰 정도에서 시작해볼 수 있지만, 이건 공식 기준이 아니라 시작값일 뿐이다. 문서 구조, 언어, 임베딩 모델, 질문 유형에 따라 최적값이 크게 달라진다. 참고로 OpenAI File Search의 기본값은 800토큰/400토큰 overlap이다.
쪼개는 방식도 여러 가지다.
- 글자 수 고정 (단순)
- 문단/섹션 경계로 (자연스러움)
- 의미 단위로 (정확하지만 구현 복잡)
좋은 청킹은 ‘의미가 잘리지 않으면서 적당히 작은’ 선을 찾는 것이다. 중요한 건 ‘청크 크기 자체’가 아니라, 대표 질문으로 검색 평가를 돌려서 실제로 관련 조각이 잘 뽑히는지 확인하는 것이다.
임베딩 (Embedding): 의미를 숫자로
컴퓨터가 “비슷한 의미”를 찾으려면 글을 어떻게든 비교 가능한 형태로 바꿔야 한다. 임베딩은 글의 ‘의미’를 긴 숫자 배열로 변환한다. 예를 들어 OpenAI의 text-embedding-3-small은 기본 1,536차원 벡터를 만든다. 차원 수는 모델마다 다르다(text-embedding-3-large는 3,072차원 등).
중요한 건 이 숫자들이 ‘의미적으로 비슷한 글은 비슷한 값’을 가진다는 것이다.
"집에서 일하는 거 가능한가요?" → [0.12, -0.45, 0.78, ...] "재택근무 정책은?" → [0.15, -0.42, 0.80, ...] (비슷!) "오늘 점심 뭐 먹지?" → [0.89, 0.11, -0.34, ...] (다름)
사용자 질문을 임베딩해서, 내 자료 조각들의 임베딩 중 ‘숫자가 비슷한 것’을 찾으면 의미가 비슷한 조각을 발견한 셈이다.
벡터 DB: 의미로 검색되는 저장소
일반 DB는 “이름이 ‘홍길동’인 사람 찾아줘” 같은 정확한 값 매칭에 특화돼 있다. 벡터 DB는 ‘가장 비슷한 벡터 찾기’에 특화된 DB다. 수백만 개의 벡터 중에서도 빠르게 유사한 것들을 찾아낼 수 있다.
대표적인 선택지들:
- ‘Pinecone, Weaviate, Qdrant’: 전용 벡터 DB
- ‘pgvector’: PostgreSQL의 벡터 확장
- ‘Elasticsearch, OpenSearch’: 검색 엔진에 벡터 기능 추가
내 팀이 이미 PostgreSQL을 쓰고 있으면 pgvector가 가장 단순하다. 대규모 전용 운영이 필요하면 Pinecone 같은 전문 서비스로 간다.
리랭킹 (Reranking): 검색 결과를 다시 정렬
임베딩 기반 검색은 빠르지만 완벽하지 않다. “비슷해 보이지만 사실 맞지 않는 조각”이 뽑힐 수 있다. 리랭킹은 1차로 찾은 여러 후보를 더 정교한 모델로 다시 평가해서 순위를 매기는 단계다.
- 1차 검색: 빠르게 상위 50개 조각 찾음
- 리랭킹: 이 50개를 더 정확한 모델로 재평가해 상위 5개만 최종 선택
리랭킹은 검색 품질을 올리는 대신 비용과 응답 시간이 늘어난다. 그래서 모든 질문에 무조건 붙이기보다, 정확도가 중요한 검색이나 1차 검색 결과가 불안정한 경우에 우선 적용한다.
언제 RAG를 쓰고, 언제 안 써도 되나
‘한 줄 요약: 자료가 많거나 자주 바뀌면 RAG, 자료가 적거나 한 번만 쓰고 버릴 거면 그냥 컨텍스트에 넣는다.’
RAG는 만능이 아니다. 상황에 따라 판단해야 한다.
| 상황 | 추천 접근 |
|---|---|
| 자료가 몇 페이지 수준, 한 번 쓰고 버림 | 그냥 프롬프트에 붙여라 (RAG 과잉) |
| 자료가 수십~수백 페이지, 자주 질의 | RAG가 적합 |
| 자료가 자주 업데이트됨 | RAG가 적합 (파인튜닝은 매번 재학습 필요) |
| 특정 말투/형식을 학습시켜야 함 | 파인튜닝 고려 |
| 실시간 정보(날씨, 주가) | RAG가 아니라 API 연결(함수 호출) |
RAG는 ‘자료가 많고, 자주 바뀌고, 의미 기반 검색이 필요한’ 상황에 적합하다.
실무에서 흔히 부딪히는 문제들
‘한 줄 요약: 문서 파싱, 청킹, 검색 정확도, 자료 업데이트, 권한 관리, 환각까지 실제로 다듬을 게 많다.’
RAG를 실제로 돌려보면 생각보다 다듬을 게 많다. 그리고 한 가지 중요한 전제: ‘RAG의 실패는 생성보다 검색에서 시작되는 경우가 많다.’ 답변이 이상할 때 모델만 탓할 게 아니라, 먼저 “관련 조각을 제대로 찾았나”를 봐야 한다.
1. 문서 파싱이 의외로 첫 관문이다
RAG 실패는 청킹이나 임베딩 이전에, 문서에서 텍스트를 제대로 뽑지 못해서 생기기도 한다. PDF의 표, 이미지, 스캔 문서, 각주, 머리말/꼬리말, 페이지 번호가 엉키면 좋은 벡터 DB를 써도 결과가 나빠진다. ‘좋은 RAG는 좋은 임베딩보다 먼저 좋은 문서 추출에서 시작한다.’
2. 청킹이 까다롭다
너무 작게 쪼개면 맥락이 끊긴다. “이 조항은 제3항과 함께 해석된다”는 문장이 있는데 제3항이 다른 조각에 있으면 AI가 제대로 이해하지 못한다. 너무 크게 쪼개면 질문과 관련 없는 내용이 섞여서 검색 품질이 떨어진다.
‘overlap’이라는 기법도 쓴다. 조각들 사이 경계를 일부 겹치게 해서 맥락이 끊기지 않게 만드는 것이다.
3. 벡터 검색만으로는 부족할 때가 많다
“2026년 3월 매출 자료”, “제12조”, “ERR-0421″같이 ‘정확한 날짜·조항 번호·에러 코드·사람 이름’이 중요한 질의는 의미 검색만으로 약하다. 실무 RAG는 벡터 검색(semantic search)과 키워드 검색(BM25 등)을 합친 ‘하이브리드 검색’을 쓰는 경우가 많다.
4. 권한도 함께 검색되어야 한다
사내 RAG에서 가장 위험한 함정이다. 사용자 A가 볼 수 없는 문서가 벡터 DB에 들어가 있고 검색 필터가 허술하면, 모델이 그 내용을 답변으로 흘릴 수 있다. ‘사용자가 볼 수 없는 문서는 검색 결과에도 나오면 안 된다.’ 문서를 벡터 DB에 넣을 때 부서, 권한, 보안 등급, 날짜 같은 메타데이터를 함께 저장하고, 질의 시점에 반드시 필터링해야 한다.
5. 자료가 바뀌면 인덱스도 다시
문서가 업데이트되면 해당 부분의 임베딩을 다시 만들어 DB에 반영해야 한다. 실시간성이 중요하면 이 업데이트 파이프라인을 따로 설계해야 한다.
6. 환각은 여전히 있다
RAG를 쓰면 환각이 줄어들지만 사라지진 않는다. 검색된 자료에 답이 없는데도 AI가 그럴듯하게 지어낼 수 있다. 프롬프트에 “자료에 없는 내용은 ‘자료에 없습니다’라고 답하라”를 명시하고, 답변 근거(인용 구간)를 함께 반환하게 만드는 것이 기본 안전장치다.
직접 구축 vs 관리형 RAG
‘한 줄 요약: 처음부터 벡터 DB를 직접 깔 필요는 없다. 공급사가 제공하는 관리형 RAG 기능도 있다.’
위 파이프라인을 전부 직접 만들 수도 있지만, 요즘은 주요 공급사들이 ‘관리형 RAG’ 기능을 제공한다. 파일 업로드, 청킹, 임베딩, 검색, 출처 표시 같은 상당 부분을 대신 처리해준다.
- ‘OpenAI File Search’: Responses API에 붙는 내장 RAG. vector store에 파일 업로드만 하면 검색까지 연결
- ‘Gemini File Search’: Gemini API의 fully managed RAG. 문서 저장·청킹·임베딩·검색·컨텍스트 주입 처리
- ‘Azure AI Search’: classic RAG와 agentic retrieval 선택지 제공
- ‘Vertex AI RAG Engine’: Google Cloud의 관리형 RAG
‘직접 구축’은 제어권이 크고 커스터마이징이 자유롭다. ‘관리형’은 시작이 빠르고 유지보수 부담이 적다. 처음이라면 관리형으로 프로토타입을 빠르게 만들어 보고, 필요에 따라 직접 구축으로 넘어가는 것도 좋은 순서다.
개발자를 위한 추가 메모
일반 독자는 여기까지 읽어도 충분하다. 아래는 직접 RAG를 구축하려는 개발자용 보충이다.
- ‘시작 스택’: LangChain, LlamaIndex 같은 프레임워크가 청킹~검색~생성 파이프라인을 대부분 추상화해준다. 프로토타입은 며칠이면 만들 수 있다.
- ‘임베딩 모델 선택’: OpenAI text-embedding-3, Cohere embed-v3, 오픈소스로는 BGE, E5 등. 언어(한국어 지원), 차원 수, 비용을 기준으로 고른다. Gemini의 최신 embedding은 텍스트·이미지·비디오·오디오를 같은 공간에 매핑하는 멀티모달 임베딩도 지원한다.
- ‘평가는 검색과 답변을 나눠서’: RAG 품질 측정은 프롬프트보다 더 까다롭다. ‘검색 평가'(관련 조각이 제대로 뽑혔나 – recall)와 ‘답변 평가'(뽑힌 조각을 근거로 충실히 답했나 – faithfulness, correctness)를 분리해서 봐야 한다. LlamaIndex 문서도 둘을 분리해서 설명한다.
- ‘GraphRAG, Agentic RAG’: 최근엔 단순 검색을 넘어 ‘에이전트가 여러 번 검색하면서 답을 조합하는’ 복합 RAG도 활발하다. 복잡한 질의에 강하지만 비용/시간은 늘어난다.
마치며: AI에게 “근거를 가지고 답하게” 만드는 기술
정리하면:
- 기본 LLM은 학습 데이터와 현재 입력에 없는 자료를 모른다. RAG는 관련 자료를 ‘찾아서 보여주고’ 답하게 만드는 패턴이다.
- RAG는 함수 호출·MCP의 경쟁자가 아니라 ‘검색-주입 패턴’의 이름이다. 직접 구축할 수도, 관리형 기능(OpenAI/Gemini File Search 등)으로 쓸 수도 있다.
- 벡터 검색 기반 파이프라인은 5단계: 청킹 → 임베딩 → 벡터 DB 저장 → 검색 → 생성. 다만 키워드/SQL/그래프 검색도 RAG의 일부가 될 수 있다.
- 실무에서는 문서 파싱, 청킹 전략, 하이브리드 검색, 권한 기반 필터링, 인덱스 업데이트, 환각 방지 프롬프트가 관건이다.
- 평가는 검색과 답변을 분리해서 봐야 한다. RAG 실패는 생성보다 검색에서 시작되는 경우가 많다.
- RAG는 ‘자주 바뀌고 양이 많은 자료’ 상황에 적합하다. 짧은 자료나 실시간 정보는 다른 방법이 낫다.
RAG를 쓰면 AI가 “내가 모르는 걸 아는 척”하는 게 아니라 “근거를 가지고 답하는” 쪽으로 움직인다. 이것이 요즘 많은 AI 서비스가 “답변에 출처 표시”를 함께 내보내는 이유다.