“다음 단어를 예측한다” — 이게 전부라고?
ChatGPT에게 “한국의 수도는?”이라고 물으면 “서울입니다”라고 답한다. 마치 진짜로 이해하고 대답하는 것처럼 보인다.
그런데 LLM이 실제로 하는 일을 한 줄로 요약하면 이렇다.
“지금까지 입력된 텍스트 다음에 올 가장 그럴듯한 단어를 예측한다.”
정확히는 ‘단어’가 아니라 ‘토큰’이지만(뒤에서 설명한다), 일단은 감을 잡기 위해 단어로 이해해도 된다. 처음 들으면 허무하다. “한국의 수도는?” 다음에 “서울”이 가장 그럴듯한 단어니까 출력하고, “서울” 다음에는 “입니다”가 그럴듯하니까 출력하고. 이걸 반복할 뿐이다.
그런데 이 단순한 구조에 ‘엄청난 양의 데이터’와 ‘Transformer’라는 신경망 구조가 결합되면, 마치 이해하는 것처럼 보이는 결과가 나온다. 이번 글에서는 이 마법 아닌 마법의 내부를 들여다본다. 토큰이 뭔지, Transformer가 어떻게 문맥을 이해하는지, 왜 컨텍스트 윈도우가 중요한지까지.

토큰: LLM이 보는 세상의 단위
LLM은 사실 ‘단어’로 텍스트를 처리하지 않는다. ‘토큰(Token)’이라는 단위로 처리한다.
토큰은 단어보다 작거나 클 수 있다. 영어에서는 보통 한 단어가 1~2 토큰이고, 흔하지 않은 단어는 여러 토큰으로 쪼개진다. 한국어는 영어보다 토큰 수가 더 많이 나오는 경우가 많다.
아래는 대략적인 예시다. 실제 토큰 수는 모델과 tokenizer에 따라 달라진다는 점을 기억하자.
| 텍스트 | 영어 토큰 (대략) | 한국어 토큰 (대략) |
|---|---|---|
| “Hello” / “안녕하세요” | 1 | 여러 개 |
| “programming” / “프로그래밍” | 1 | 여러 개 |
| “ChatGPT” | 1 | 1 |
이 차이가 실무에서 의미가 있다. 같은 양의 정보를 영어로 보내면 한국어보다 적은 토큰을 쓰는 경우가 많다. API 비용이 토큰 단위로 청구되기 때문에, 영어로 프롬프트를 작성하면 비용 차이가 생길 수 있다. 정확한 토큰 수가 필요하면 OpenAI, Gemini, Anthropic이 각각 제공하는 token counting 기능으로 직접 재는 것이 원칙이다.
‘컨텍스트 윈도우’는 LLM이 한 번에 처리할 수 있는 토큰 수의 한계다. 모델마다 다르며, 뒤에서 자세히 다룬다.
왜 단어가 아니라 토큰인가
세상에는 단어가 너무 많다. 영어에만 수십만 개, 모든 언어를 합치면 수백만 개. 게다가 새로운 단어, 합성어, 신조어가 계속 생긴다.
만약 LLM이 단어 단위로 학습했다면, 한 번도 본 적 없는 단어는 처리할 수 없다. 토큰은 이 문제를 해결한다. 자주 쓰는 패턴을 토큰으로 만들고, 흔하지 않은 단어는 작은 토큰들의 조합으로 표현한다.
# 개념 설명용 예시 (실제 분해는 tokenizer마다 다름) "unhappiness" → ["un", "happi", "ness"] "happy" → ["happy"] "unhappy" → ["un", "happy"]
이렇게 하면 어떤 새로운 단어도 기존 토큰의 조합으로 표현할 수 있다.
Transformer: 문맥을 보는 능력
토큰을 받아서 다음 토큰을 예측하는 신경망이 ‘Transformer’다. 2017년 Google이 발표한 “Attention is All You Need” 논문이 시작이고, 현재 모든 주요 LLM의 기반 구조다.
GPT(Generative Pre-trained Transformer)라는 이름 자체에 Transformer가 들어 있다.
Transformer 이전에는
Transformer 이전의 자연어 처리 모델(RNN, LSTM)은 텍스트를 ‘순서대로 한 토큰씩’ 처리했다. “나는 오늘 학교에 갔다”를 처리하려면 ‘나는’ → ‘오늘’ → ‘학교에’ → ‘갔다’ 순서대로 하나씩 읽어야 했다.
이 방식의 문제는 두 가지다.
- '병렬 처리가 안 됨.' 순서대로 읽어야 하니까 GPU의 병렬 연산을 활용하기 어렵다.
- '먼 토큰 사이의 관계를 잘 못 봄.' 문장이 길어질수록 앞 단어의 영향이 흐려진다. “나는 어제 카페에서 친구를 만나서 커피를 마셨고, 그가 추천한 책을 읽었다”에서 '그가'가 '친구'를 가리킨다는 걸 알기 어렵다.
Transformer의 핵심: Attention
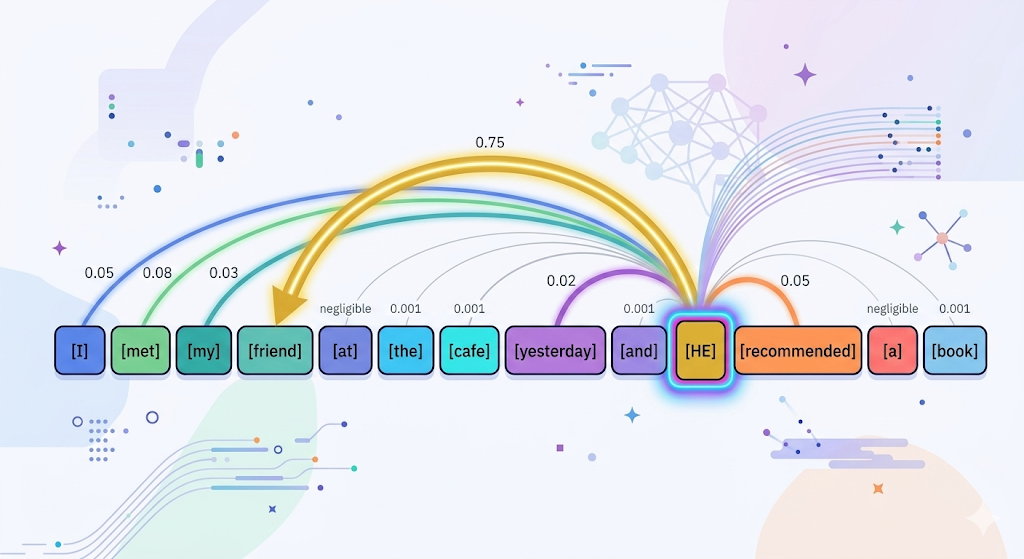
Transformer는 ‘Attention’이라는 메커니즘으로 이 문제를 해결했다. Attention을 한국어로 옮기면 ‘주의’지만, 여기서는 ‘어떤 토큰이 다른 어떤 토큰과 얼마나 관련 있는지’를 나타내는 가중치로 이해하면 된다.
핵심 아이디어를 단순화하면 이렇다. ‘각 토큰을 처리할 때, 입력의 모든 토큰을 동시에 보고, 어떤 토큰과 얼마나 관련이 있는지 가중치를 계산한다.’
입력: "나는 어제 카페에서 친구를 만나서 그와 커피를 마셨다" '그와'라는 토큰을 처리할 때, Transformer는 모든 토큰을 동시에 보고 가중치를 매긴다: 나는 : 0.05 어제 : 0.02 카페에서 : 0.03 친구를 : 0.75 ← 가장 관련이 높은 토큰! 만나서 : 0.05 ... → '그와'는 '친구를'을 가리킨다고 판단
이 메커니즘 덕분에 Transformer는 문장의 길이와 상관없이 멀리 떨어진 토큰 사이의 관계를 잡아낼 수 있다. 그리고 모든 토큰을 동시에 처리할 수 있어서 GPU 병렬화가 가능하다. 이것이 LLM이 거대해질 수 있었던 기술적 기반이다.
모델은 어떻게 학습되는가
Transformer 구조 자체는 빈 그릇이다. 여기에 ‘학습’을 통해 패턴을 채운다.
LLM 학습의 핵심은 단순하다. 인터넷에서 수집한 엄청난 양의 텍스트를 보여주고, ‘N개 토큰이 주어졌을 때, N+1번째 토큰을 맞춰라’는 문제를 무한히 반복시킨다.
입력: "한국의 수도는" 정답: "서울" 입력: "한국의 수도는 서울" 정답: "이다" 입력: "한국의 수도는 서울이다" 정답: "."
수십억 개의 문장에 대해 이런 예측을 반복하면, 모델 내부의 수많은 가중치가 점점 조정된다. 결국 모델은 ‘인간이 쓴 텍스트의 통계적 패턴’을 학습한다.
여기서 한 가지 중요한 점은, ‘모델은 사실을 외우는 게 아니라 패턴을 학습한다’는 것이다. 그래서 LLM은 가끔 그럴듯한 거짓말을 한다(이것을 ‘환각, hallucination’이라고 부른다). 사실을 검색해서 답하는 게 아니라, “이런 질문에는 이런 형태의 답이 그럴듯하다”는 패턴으로 생성하기 때문이다.
실제 동작 흐름: 한 토큰씩 생성하기
이제 ChatGPT가 답을 생성하는 흐름을 따라가 보자.
[사용자 입력] "파이썬으로 1부터 10까지 합 구하는 코드 짜줘" [1단계: 토큰화] 이 문장을 토큰들로 변환 → [파이썬, 으로, 1, 부터, 10, 까지, 합, 구하는, 코드, 짜, 줘] [2단계: Transformer가 다음 토큰 예측] 입력 토큰들을 보고, 다음에 올 가장 그럴듯한 토큰을 확률로 계산 → "다음에 올 토큰: '```'(95%), '여기'(3%), '간단'(1%), ..." → '```' 출력 [3단계: 새 토큰을 입력에 추가하고 반복] 입력: [..., 짜, 줘, ```] → 다음 토큰 예측: 'python' (90%) → 'python' 출력 [4단계: 종료 조건까지 반복] 한 토큰씩 생성하면서 입력에 추가하고, 다시 예측 "sum(range(1, 11))"이라는 코드가 토큰 단위로 차례차례 나옴 [5단계: 사용자에게 표시] 누적된 토큰들을 다시 텍스트로 변환해서 보여줌
ChatGPT 화면에서 답이 한 글자씩(정확히는 한 토큰씩) 흘러나오는 것이 바로 이 과정이다. 미리 답을 다 만들어두고 보여주는 게 아니라, 실시간으로 한 토큰씩 생성하는 중이다.
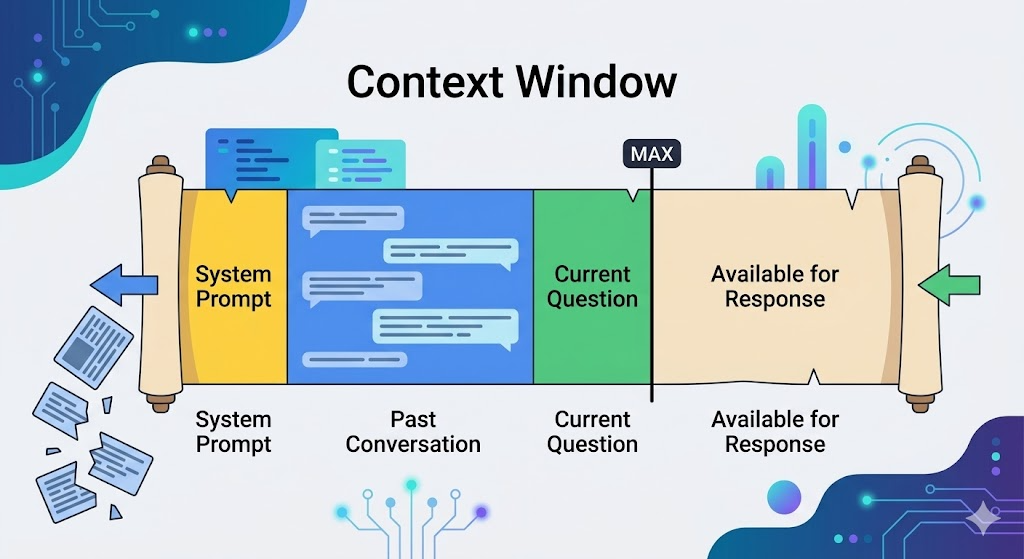
컨텍스트 윈도우: 한 번에 볼 수 있는 토큰의 한계
LLM에는 ‘한 번에 처리할 수 있는 토큰의 최대 개수’가 있다. 이것을 ‘컨텍스트 윈도우(Context Window)’라고 부른다. 대부분의 모델은 입력 가능한 컨텍스트와 한 번에 출력 가능한 최대 길이를 따로 제시한다.
2026년 4월 기준 주요 모델의 공식 한도를 정리하면 이렇다 (모델 업데이트에 따라 바뀔 수 있음).
| 모델 | 입력 컨텍스트 | 최대 출력 |
|---|---|---|
| Claude Opus 4.6 / Sonnet 4.6 | 약 1M 토큰 | 모델/모드별 상이 |
| Gemini 2.5 Pro | 약 1M 토큰 | 약 64K 토큰 |
| GPT-4.1 | 약 1M 토큰 | 약 32K 토큰 |
| GPT-5.4 | 약 1M 토큰 | 약 128K 토큰 |
이 한계 안에는 ‘시스템 프롬프트, 이전 대화, 현재 질문, 그리고 생성 중인 답변’이 모두 포함된다. 코딩 도구라면 여기에 ‘프로젝트 코드’까지 들어간다.
이 개념을 이해하면 실무에서 자주 나오는 현상들이 설명된다.
1. 긴 대화는 제품마다 처리 방식이 다르다
대화가 길어져서 컨텍스트 윈도우를 넘으면, 모델 자체는 보통 에러를 반환한다. 하지만 ChatGPT, Claude 앱 같은 제품은 그 위에 자체 처리를 올린다. 오래된 메시지를 잘라내는 truncation, 과거 내용을 요약으로 압축하는 compaction, 또는 그냥 에러를 사용자에게 노출하는 방식 등으로 서비스마다 다르게 동작한다. “ChatGPT가 옛날 대화를 잊어버렸다”는 현상은 이 제품 레이어에서 일어나는 것이지, 모델이 맘대로 잊는 것은 아니다.
2. 큰 코드베이스는 한 번에 다 못 본다
Claude Code가 “프로젝트 전체를 이해한다”는 말은 컨텍스트 윈도우가 큰 모델 + 영리한 파일 선택 알고리즘의 조합이지, 정말로 모든 코드를 통째로 로드하는 것은 아니다.
3. 한국어는 컨텍스트를 더 빨리 소진한다
같은 정보를 한국어로 넣으면 영어보다 토큰 수가 더 많이 나오는 경우가 많다. 컨텍스트 윈도우도 그만큼 빨리 채워진다. 정확한 차이는 tokenizer와 문맥에 따라 달라지니, 큰 문서라면 미리 재보는 편이 좋다.
4. 긴 컨텍스트 = 긴 기억이 아니다
컨텍스트가 길어질수록 응답이 느려지고 비용도 늘어난다. 그뿐 아니라, 입력이 너무 길어지면 모델이 중간/끝 부분을 놓치는 ‘context rot’ 현상도 보고된다. 1M 컨텍스트라고 해도, 처음부터 끝까지를 완벽히 기억하는 건 아니라는 의미다. 작업에 필요한 만큼만 쓰는 것이 성능/비용 양쪽에서 효율적이다.
헷갈리는 용어: 토큰 / 사용량 / rate limit / quota
이 개념들은 비슷해 보이지만 다르다. 실무에서 429 에러가 날 때마다 헷갈리는 지점이기도 하다.
| 용어 | 의미 |
|---|---|
| 토큰 수(token count) | 텍스트가 얼마나 큰지 재는 단위 |
| 사용량(usage) | 실제 호출에서 소비된 토큰 수 (청구 기준) |
| rate limit | ‘얼마나 빨리’ 쓸 수 있는지 제한 (분당/일당 처리량, RPM/TPM 등) |
| quota / spend cap | ‘얼마나 많이’ 쓸 수 있는지 총량 한도 (프로젝트/계정 단위) |
429 에러 메시지가 “quota exceeded”와 “rate limit exceeded” 둘 다 나올 수 있는데, 엄밀히는 다른 뜻이다. 전자는 더 넓은 한도 개념, 후자는 단기간 처리량 초과에 가깝다. 다만 Google은 quota를 상위 개념처럼 쓰기도 해서 벤더마다 용법이 조금씩 다르다.
정리: LLM의 핵심 동작 한 장
이 글에서 본 LLM의 동작을 한 그림으로 정리하면 이렇다.
[입력 텍스트] ↓ [토큰화] - 텍스트를 토큰 단위로 변환 ↓ [Transformer] - Attention으로 모든 토큰의 관계를 파악 ↓ [다음 토큰 예측] - 가장 확률 높은 다음 토큰 선택 ↓ [새 토큰을 입력에 추가] - 컨텍스트 윈도우 안에서 ↓ (반복: 종료 토큰이 나오거나 최대 길이 도달까지) ↓ [출력 텍스트]
핵심을 요약하면:
- LLM은 ‘다음 토큰을 예측’하는 단순한 동작을 반복한다.
- ‘토큰’은 단어보다 작거나 큰, LLM이 보는 텍스트의 기본 단위다.
- ‘Transformer’의 Attention 덕분에 멀리 떨어진 토큰 사이의 관계도 본다.
- ‘컨텍스트 윈도우’는 한 번에 처리 가능한 토큰의 한계이고, 모델/제품 레이어에서 처리 방식이 다르다.
- LLM은 사실을 외우는 게 아니라 패턴을 학습하므로, 환각이 발생할 수 있다.
그리고 한 가지 더. LLM은 ‘모델 코어’와 ‘실제 제품’이 구분된다. 코어는 다음 토큰 예측기지만, ChatGPT나 Claude 같은 실제 제품은 그 위에 시스템 프롬프트, 웹 검색, 파일 분석, 코드 실행, 함수 호출 같은 레이어가 얹혀 있다. “그냥 다음 토큰 예측인데 왜 이렇게 똑똑해 보이지?”의 답은, 코어 능력과 제품 레이어가 결합됐기 때문이다.
‘실전 팁’: 토큰 수를 감으로 추정하지 말고, OpenAI/Gemini/Anthropic이 각각 제공하는 count_tokens 기능으로 직접 재자. 비용 예측, 컨텍스트 관리, 프롬프트 최적화 모두 여기서 시작된다.
다음 글에서는 이 동작 방식 위에서 만들어진 GPT, Claude, Gemini, Llama 같은 주요 모델들이 어떻게 다른지, 무엇을 기준으로 모델을 골라야 하는지를 다룬다.