«¿Eh? ¿Ya terminó la build?»
Después de probar lo cómodo que era Docker, empecé a mover poco a poco mi entorno de desarrollo a Docker sin decírselo al jefe del equipo. Escribí un plano llamado Dockerfile y ejecuté el comando docker build.
La primera vez tardó bastante. Entre descargar Ubuntu, instalar Java y bajar las librerías, los JAR, de mi proyecto, se fueron unos cinco minutos. «Bueno, como es la primera vez, es normal que tarde.»
Pero cuando corregí un simple error tipográfico en el código y volví a lanzar la build, dudé de mis propios ojos. En cuanto pulsé Enter, en la terminal apareció el mensaje Successfully built. El tiempo empleado: apenas 0,1 segundos.
«¿No se habrá roto? Hace un momento tardaba cinco minutos. ¿Cómo puede terminar de golpe en un instante?»
Encendí el servidor con cierto miedo, pero el código estaba corregido perfectamente. Entonces, ¿qué estaba ocurriendo dentro de Docker? El secreto de esa velocidad absurda estaba en una forma de almacenamiento muy particular llamada «capa», Layer.
Imagen y contenedor
Antes de entrar a fondo en el mecanismo, aclaremos primero dos términos que suelen confundirse.
Lo que enviamos al servidor durante el despliegue no es un «contenedor», sino una «imagen». El servidor solo tiene que recibir esa imagen y ejecutarla.
Layer: la magia del celofán transparente
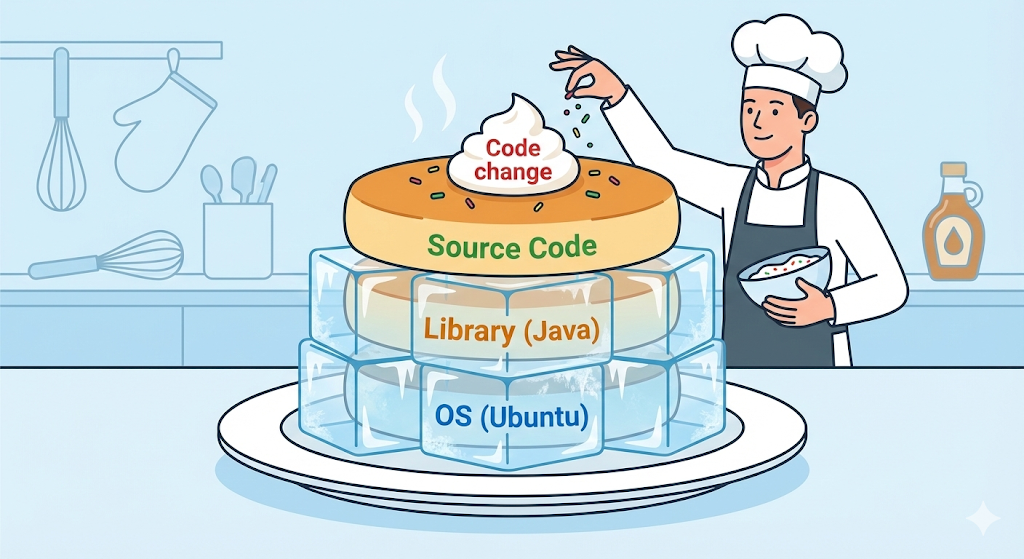
Una imagen de Docker no es un archivo único y monolítico. Se parece más a varias láminas de celofán transparente, layers, apiladas unas sobre otras. Cada línea de instrucción escrita en un Dockerfile se convierte en su propia capa.
Veámoslo con un ejemplo.
# Capa 1: instalar Ubuntu (SO)
FROM ubuntu:20.04
# Capa 2: instalar Java
RUN apt-get install openjdk-17-jdk
# Capa 3: copiar mi codigo
COPY my-app.jar /app/my-app.jar
# Capa 4: ejecutar
CMD ["java", "-jar", "/app/my-app.jar"]
Si lees con calma el contenido de un Dockerfile, ves que la estructura no es tan complicada. «Instala Ubuntu, FROM, instala Java, RUN, trae mi código, COPY, y ejecútalo, CMD.»
Al final, lo que hicimos fue tomar ese proceso de configuración del servidor que antes escribíamos a mano en una VM o en la terminal del servidor y convertirlo en un documento. Con solo ese documento, Docker realiza por sí mismo toda la instalación sin que nadie tenga que ir guiándolo paso a paso. Este concepto también conecta más adelante con el principio central de la automatización de CI/CD.
Pero, si es así, ¿por qué Docker no compacta todo el proceso en un solo paso? ¿Por qué lo divide a propósito línea por línea en capas y las apila con cuidado?
La respuesta es la reutilización, el caching. Si yo modifico el código y vuelvo a hacer la build, Docker piensa de forma inteligente: «La primera planta, el SO, y la segunda, Java, son exactamente iguales que antes. Entonces no hace falta reconstruirlas. Lo correcto es reutilizar las capas en caché que ya estaban creadas.»
Después reconstruye solo desde la tercera planta que cambió, es decir, la copia del código. Por eso la segunda build terminó en apenas 0,1 segundos.
[Code Verification] Ver el caché de capas con tus propios ojos
No nos quedemos solo con palabras. Verifiquémoslo con código. Basta con crear un Dockerfile simple y hacer la build dos veces.
FROM alpine:latest
RUN echo "1. Instalando utils basicos..." && sleep 2 # Tarda 2 segundos
COPY test.txt /app/test.txt
CMD ["cat", "/app/test.txt"]
$ docker build -t my-test:v1 .
# Resultado:
# [2/3] RUN echo "1. Instalando utils basicos..." ... 2.1s (tardo 2s)
$ docker build -t my-test:v2 .
# Resultado:
# [2/3] RUN echo "1. Instalando utils basicos..." ... CACHED (0s!)
¿Ves la palabra CACHED claramente marcada en el log? Esa es la prueba de que Docker se saltó el trabajo que normalmente tarda dos segundos.
Consejo práctico: el orden lo es todo
Cuando entiendes este principio del caché por capas, la respuesta a cómo escribir un Dockerfile se vuelve evidente. La idea central es simple: «Pon abajo, antes, lo que casi no cambia, y arriba, después, lo que cambia a menudo.»
Mal ejemplo:
# 1. Copiar primero el codigo fuente (cambia a menudo)
COPY . .
# 2. Instalar librerias (casi no cambia)
RUN npm install
El código fuente cambia decenas de veces al día. Si cambia el paso 1, Docker invalida también la caché del paso 2, la instalación de librerías, y vuelve a ejecutar todo. Corriges una sola línea y acabas esperando otra vez a npm install.
Buen ejemplo:
# 1. Copiar primero solo package.json
COPY package.json .
# 2. Instalar librerias (queda en cache)
RUN npm install
# 3. Copiar el codigo fuente
COPY . .
Solo con cambiar el orden así, la velocidad de build puede multiplicarse por diez. Esa es la diferencia entre alguien que empieza con Docker y alguien que de verdad sabe usarlo.
Consejo práctico 2: las tags son tu salvavidas
En el ejemplo de arriba escribí docker build -t my-test:v1 .. Aquí, el v1 que aparece tras los dos puntos, :, es la tag.
Muchos principiantes no ponen tags porque les da pereza. Cuando eso pasa, Docker asigna automáticamente la etiqueta latest.
Ese simple hábito de usar tags te salvará muchas horas de salida en el futuro.
Para cerrar: tener en la mano la magia de los 0,1 segundos
Una imagen de Docker no es solo un montón de archivos. Es un artefacto técnico apilado capa por capa para entregar un entorno de la forma más eficiente posible. Si entiendes el caché por capas y ordenas bien tu Dockerfile, puedes construir un entorno de despliegue ligero y rápido que termina en 0,1 segundos.
Ahora ya está todo listo para congelar perfectamente el entorno de mi computadora en una image y enviarlo al servidor.
Pero cuando intenté ejecutar esa imagen en el servidor, apareció una nueva preocupación. Un servicio web no funciona solo con un contenedor de servidor. También necesita una base de datos, Redis y un servidor frontend.
¿De verdad se pueden gestionar todos esos contenedores encendiéndolos y apagándolos uno por uno con comandos separados? ¿Cómo se comunican entre sí? Más allá de una sola ‘image’, ¿cómo se estructura una aplicación completa? La próxima vez, ampliemos el mundo de Docker con los conceptos de contenedores, servicios y stacks.