“Hè? Was die build net al klaar?”
Nadat ik had geproefd hoe handig Docker was, begon ik stiekem, zonder dat mijn teamlead het wist, mijn ontwikkelomgeving beetje bij beetje naar Docker te verplaatsen. Ik schreef een bouwtekening genaamd Dockerfile en voerde het commando docker build uit.
De eerste keer duurde het best lang. Ubuntu downloaden, Java installeren en de libraries, JARs, van mijn project ophalen kostte samen ongeveer vijf minuten. “Tja, de eerste keer duurt het natuurlijk langer.”
Maar toen ik een simpele typefout in de code had gecorrigeerd en opnieuw bouwde, geloofde ik mijn eigen ogen niet. Nauwelijks had ik op Enter gedrukt of de terminal liet al Successfully built zien. Totale tijd: slechts 0,1 seconde.
“Wacht, is dit stuk? Net duurde het nog vijf minuten. Hoe kan het nu ineens meteen klaar zijn?”
Ik startte de server zenuwachtig op, maar de code was perfect aangepast. Dus wat gebeurde er in hemelsnaam binnen Docker? Het geheim achter die krankzinnige snelheid zat in een bijzondere manier van opslaan die ‘layers’ heet.
Image en container
Voordat we echt in het mechanisme duiken, laten we eerst twee termen verduidelijken die vaak door elkaar worden gehaald.
Wat we tijdens deployment naar de server sturen, is geen ‘container’, maar een ‘image’. De server hoeft dat image alleen maar te ontvangen en uit te voeren.
Layer: de magie van transparant cellofaan
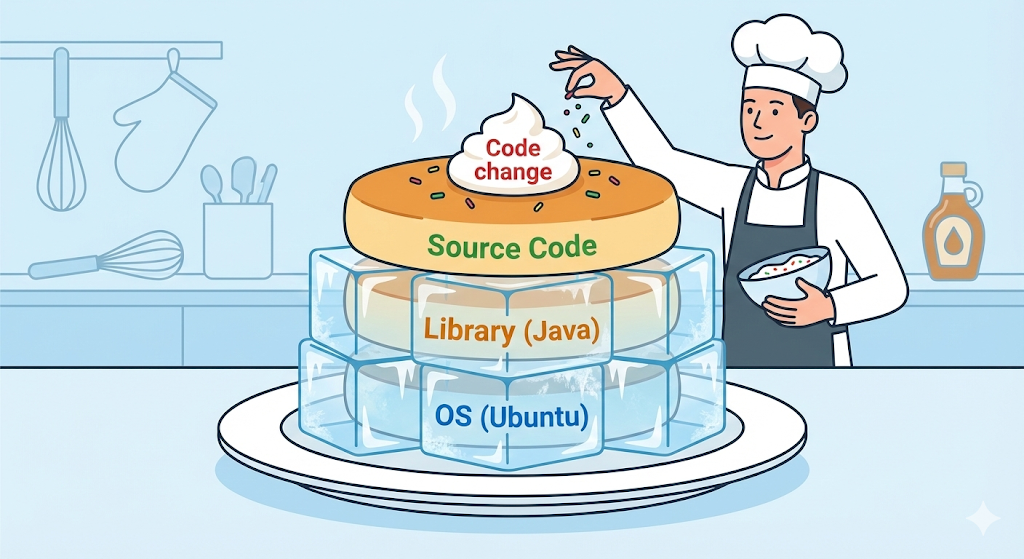
Een Docker-image is niet één massief bestand. Het lijkt eerder op meerdere vellen transparant cellofaan, layers, die op elkaar gestapeld zijn. Elke afzonderlijke instructieregel in een Dockerfile wordt een eigen laag.
Laten we een voorbeeld nemen.
# Laag 1: Ubuntu (OS) installeren
FROM ubuntu:20.04
# Laag 2: Java installeren
RUN apt-get install openjdk-17-jdk
# Laag 3: mijn code kopieren
COPY my-app.jar /app/my-app.jar
# Laag 4: uitvoeren
CMD ["java", "-jar", "/app/my-app.jar"]
Als je rustig naar de inhoud van een Dockerfile kijkt, zie je dat de structuur niet zo ingewikkeld is. “Installeer Ubuntu, FROM, installeer Java, RUN, haal mijn code binnen, COPY, en voer hem uit, CMD.”
Uiteindelijk hebben we dus gewoon het server-setup-proces dat we vroeger met de hand in een VM of in een serverterminal intikten, opgeschreven in een document. Met alleen dat document voert Docker alle installatiestappen zelf uit. Dit concept hangt later ook direct samen met het kernprincipe van CI/CD-automatisering.
Maar waarom plat Docker dit hele proces niet gewoon af tot één stap? Waarom splitst het alles bewust regel voor regel op in layers en stapelt het ze netjes op?
Het antwoord is hergebruik, oftewel caching. Als ik de code wijzig en opnieuw build, denkt Docker slim na: “De eerste verdieping, het OS, en de tweede verdieping, Java, zijn exact hetzelfde als hiervoor. Dan hoef ik die niet opnieuw te bouwen. Ik kan gewoon de eerder gemaakte cache-layers hergebruiken.”
Daarna bouwt het alleen opnieuw vanaf de gewijzigde derde verdieping, het kopiëren van de code. Daarom duurde die tweede build maar 0,1 seconde.
[Code Verification] De layer-cache met eigen ogen zien
Laten we niet alleen zeggen dat het zo werkt, maar het ook met code controleren. Alles wat je hoeft te doen is een simpele Dockerfile maken en twee keer builden.
FROM alpine:latest
RUN echo "1. Basis utils installeren..." && sleep 2 # Duurt 2 seconden
COPY test.txt /app/test.txt
CMD ["cat", "/app/test.txt"]
$ docker build -t my-test:v1 .
# Resultaat:
# [2/3] RUN echo "1. Basis utils installeren..." ... 2.1s (duurde 2s)
$ docker build -t my-test:v2 .
# Resultaat:
# [2/3] RUN echo "1. Basis utils installeren..." ... CACHED (0s!)
Zie je het woord CACHED duidelijk in de log staan? Dat is het bewijs dat Docker een stap van twee seconden heeft overgeslagen.
Praktisch advies: volgorde is alles
Zodra je dit principe van layer-caching begrijpt, wordt ook duidelijk hoe je een Dockerfile moet schrijven. De kern is eenvoudig: “Zet wat bijna niet verandert onderaan, dus eerder, en wat vaak verandert bovenaan, dus later.”
Slecht voorbeeld:
# 1. Eerst broncode kopieren (verandert vaak)
COPY . .
# 2. Libraries installeren (verandert nauwelijks)
RUN npm install
Broncode verandert tientallen keren per dag. Als stap 1 verandert, maakt Docker ook de cache van stap 2, library-installatie, ongeldig en voert alles opnieuw uit. Je corrigeert één regel code en moet weer wachten op npm install.
Goed voorbeeld:
# 1. Kopieer eerst alleen package.json
COPY package.json .
# 2. Libraries installeren (blijft gecached)
RUN npm install
# 3. Broncode kopieren
COPY . .
Alleen al door de volgorde zo aan te passen, kan de build tien keer sneller worden. Dat is precies het verschil tussen een Docker-beginner en iemand die het echt begrijpt.
Praktisch advies 2: tags zijn je reddingslijn
In het voorbeeld hierboven schreef ik docker build -t my-test:v1 .. Hier is de v1 achter de dubbele punt, :, de tag.
Veel beginners laten tags weg omdat ze het gedoe vinden. In dat geval geeft Docker automatisch de tag latest.
Die ene tag-gewoonte gaat later je avonden beschermen.
Tot slot: de magie van 0,1 seconde in handen krijgen
Een Docker-image is niet zomaar een stapel bestanden, maar een technisch kunstwerk dat laag voor laag zo efficiënt mogelijk is opgebouwd om een omgeving te leveren. Als je layer-caching begrijpt en je Dockerfile goed ordent, kun je een lichtgewicht en snelle deploy-omgeving bouwen die in 0,1 seconde klaar is.
Nu is alles klaar om mijn computeromgeving perfect in te vriezen als image en naar de server te sturen.
Maar toen ik dat image daadwerkelijk op de server wilde draaien, ontstond er een nieuw probleem. Een webservice draait niet op slechts één servercontainer. Er is ook een database nodig, Redis en een frontendserver.
Kun je al die containers echt beheren door ze één voor één met losse commando’s aan en uit te zetten? Hoe communiceren ze met elkaar? Hoe bouw je, voorbij één enkel image, een volledige applicatie op? Laten we het de volgende keer hebben over het grotere Docker-wereldbeeld: containers, services en stacks.