Jeśli serwer działa wolno, zwiększyć liczbę wątków?
Kiedy dołączyłem do firmy, serwer Spring Boot API, za który odpowiadałem, zwalniał, gdy był duży ruch. Ponieważ nie znałem przyczyny, zacząłem od Google.
„Powolna reakcja serwera Spring Boot” „Dostrajanie wydajności Tomcat”
W wyniku wyszukiwania najczęstsza rada znajdowana na blogach i społecznościach była prosta. 'Zwiększ rozmiar puli wątków Tomcat. Twoja prośba oczekuje, ponieważ nie ma wystarczającej liczby pracowników.”.
Pomyślałem: „Aha, brakuje nam pracowników!” Myślałem po prostu. Natychmiast otworzyłem ustawienia application.yml i zwiększyłem liczbę wątków z domyślnych 200 do 2000. Według moich obliczeń liczba pracowników wzrosła 10-krotnie, więc prędkość przetwarzania musiała być większa.
Ale po zobaczeniu ekranu monitorowania po wdrożeniu zamarłem. Serwer faktycznie działał wolniej, użycie procesora wzrosło, ale liczba przetwarzanych żądań w rzeczywistości spadła. Wydawało się, że robotnicy po prostu kopali w powietrzu, nie wykonując żadnej pracy.
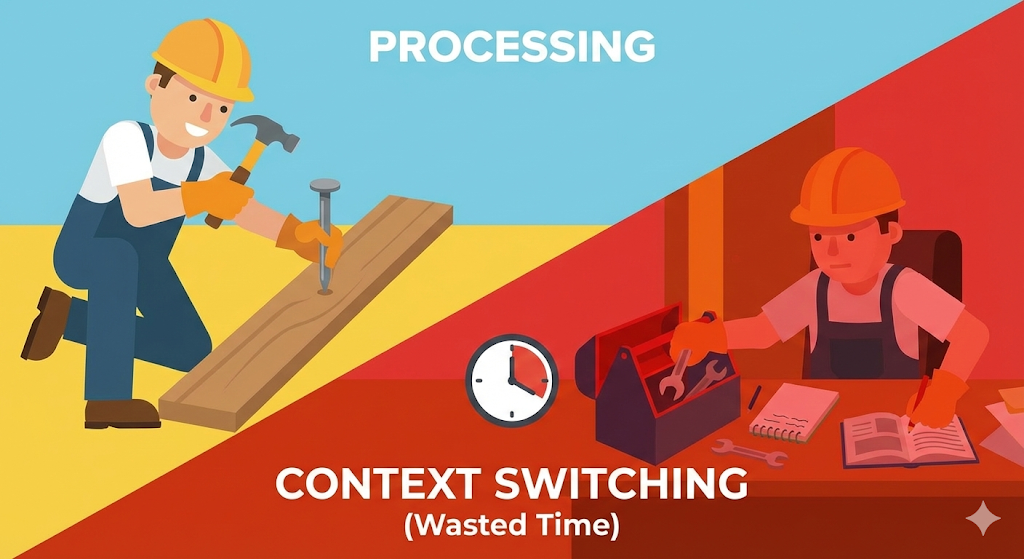
Dlaczego, u licha, wzrosła liczba pracowników, a fabryka działała wolniej? Szukając przyczyny, natknąłem się na najdroższy koszt systemu operacyjnego, „przełączanie kontekstu”.

Recenzja: wątki, pamiętasz?
Dla tych, którzy czytają ten artykuł po raz pierwszy lub dla tych, którzy nie są zaznajomieni z treścią poprzedniego artykułu (Część 4: Procesy i wątki), przewińmy na chwilę.
W naszym światopoglądzie „cyfrowego centrum logistycznego”:
Sping Boot jest w zasadzie wielowątkowy. Za każdym razem, gdy przychodzi żądanie, do wykonania pracy przydzielany jest jeden proces roboczy (wątek). Pomyślałem więc po prostu: „Jeśli będzie więcej pracowników, więcej wniosków zostanie przetworzonych jednocześnie, prawda?”
Ale było coś, co przeoczyłem. Jest to liczba rdzeni procesora, kluczowych pracowników naszej fabryki.
Praca zmianowa w cyfrowym centrum dystrybucji
W rzeczywistości rdzeń procesora, główny pracownik komputera, może wykonywać tylko jedno zadanie na raz. (Na podstawie jednego rdzenia) Jednak jednocześnie słuchamy piosenek, kodujemy i korzystamy z KakaoTalk. Jak to możliwe?
Dzieje się tak, ponieważ kierownik fabryki (OS) nakazuje pracownikom (CPU) „pracę zmianową” z niewiarygodną szybkością. „Odtwarzaj piosenkę przez 0,001 sekundy i zatrzymaj! Wyślij KakaoTalk przez następne 0,001 sekundy i zatrzymaj!”
To jest „dzielenie czasu”, a proces, w którym pracownik odkłada narzędzie i bierze nowe, to „przełączanie kontekstu”.
Cena zmiany zadań: czas na zmianę ubrania
Tak się stało, gdy zwiększyłem liczbę wątków do 2000.
Procesor to pojedynczy korpus, w którym 2000 pracowników obsługujących wątki krzyczy: „Pozbądź się go!” Procesor spotyka się na zmianę z 2000 osób, aby rzetelnie przetwarzać prace.
Problem polega na tym, że przejście z pracy pracownika A do pracy pracownika B wymaga „czasu przygotowania”.
Ten „czas na nagranie, odłożenie i przeczytanie” nazywany jest „kosztem zmiany kontekstu (kosztem ogólnym)”. Przy wystarczającej liczbie pracowników koszt ten jest znikomy. Co jednak, jeśli pracowników jest za dużo? CPU znajduje się w sytuacji, w której przez cały dzień organizuje księgi pracowników, ale nie jest w stanie wykonać żadnej „faktycznej pracy (obliczeń)”. To był prawdziwy powód spowolnienia mojego serwera.
[Weryfikacja kodu] Czy koniecznie jest to szybsze tylko dlatego, że jest dużo wątków?
Warto zobaczyć i usłyszeć. Udowodnijmy to kodem. Porównajmy szybkość wykonania tej samej ilości operacji dodawania przy użyciu jednego wątku i podzielenia jej na 1 milion wątków. Zdrowy rozsądek podpowiada, że 1 milion jednostek powinno być szybsze, ale rzeczywistość jest inna.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class ContextSwitchingTest {
private static final int TASK_COUNT = 1_000_000;
public static void main(String[] args) throws InterruptedException {
// 1. Przetwarzanie jednym watkiem (bez zmian)
long start = System.currentTimeMillis();
for (int i = 0; i < TASK_COUNT; i++) {
simpleTask();
}
System.out.println("Czas jednego watku: " + (System.currentTimeMillis() - start) + "ms");
// 2. Przetwarzanie z ogromna liczba watkow (wywoluje przelaczanie kontekstu)
// Utworz nieograniczona pule watkow (uwaga: komputer moze sie zawiesic)
ExecutorService executor = Executors.newCachedThreadPool();
start = System.currentTimeMillis();
for (int i = 0; i < TASK_COUNT; i++) {
executor.submit(() -> simpleTask());
}
executor.shutdown();
executor.awaitTermination(1, TimeUnit.HOURS);
System.out.println("Czas wielu watkow: " + (System.currentTimeMillis() - start) + "ms");
}
private static void simpleTask() {
int a = 1 + 1; // Bardzo lekka praca
}
}
Przykładowe wyniki (różnią się w zależności od środowiska):
Analiza: Samo zadanie (1+1) jest tak proste, że można je wykonać w mgnieniu oka. Jednak w metodzie wielowątkowej koszt utworzenia miliona wątków i przełączania się systemu operacyjnego między nimi jest tysiące razy droższy niż czas operacji. Pępek jest większy niż brzuch
Wnioski z praktyki: znajdowanie idealnego miejsca
Ile wątków jest zatem odpowiednich dla serwera Spring Boot? Odpowiedź zależy od tego, „co robi serwer”.
Jednak podobnie jak w sytuacji, której doświadczyłem, ślepe zwiększanie liczby do 2000 to za dużo. Dzieje się tak dlatego, że wraz ze wzrostem liczby wątków zużywa się więcej pamięci (stosu), a procesor jest przeciążony z powodu kosztów przełączania kontekstu.
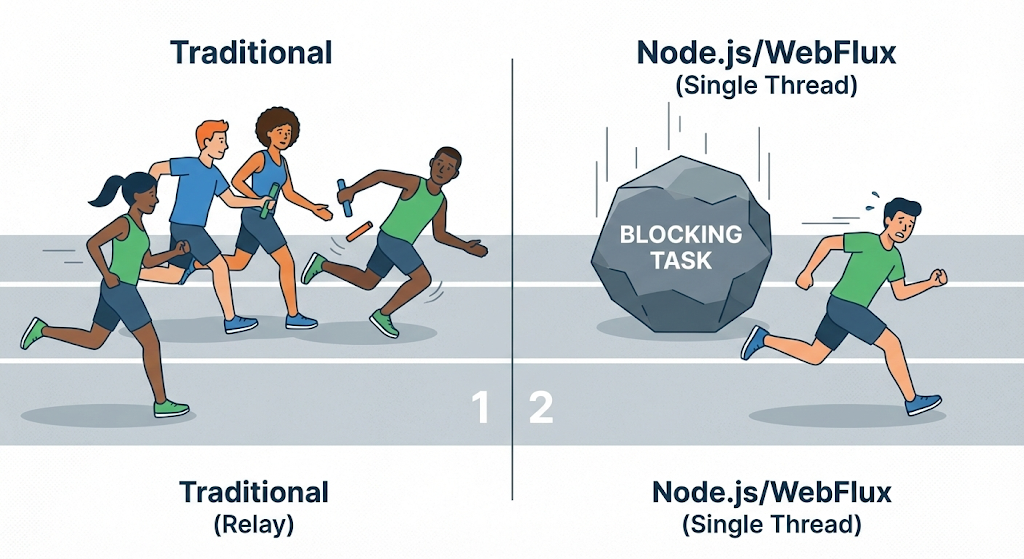
Ostatnio uwagę zwracają technologie nieblokujące, takie jak Node.js i WebFlux firmy Spring, które mogą pomóc w rozwiązaniu tego problemu. Stosują strategię „nie zwiększaj liczby wątków, pozwól jednej osobie przetwarzać szybko, bez zatrzymywania”.
Zamknięcie: nie ma bezpłatnego lunchu
Często błędnie wierzymy, że „jednoczesne przetwarzanie rzeczy jest szybsze”. Jednak w świecie komputerów „jednoczesna” to tak naprawdę praca zmianowa z dużą szybkością, co jest niemal sztuczką.
Kiedy zrozumiesz przełączanie kontekstu, zrozumiesz, dlaczego dostrajanie serwerów nie polega tylko na „podkręcaniu liczb”. Bezkrytycznie zwiększana liczba wątków może w rzeczywistości stać się trucizną, która dławi serwer.
Teraz wewnętrzne fabryki komputera (procesor, pamięć RAM, proces) wydają się działać całkiem dobrze. Otwórzmy teraz drzwi fabryki i wyjdźmy na zewnątrz. Jak wysyłamy dane utworzone w naszej fabryce do innej odległej fabryki (klienta)?
Następnym razem porozmawiamy o sieciach, HTTP i tej niewidzialnej sieci drogowej.