“이 데이터 외부로 못 나가는데요”
AI 기능을 붙이려다 벽에 부딪히는 순간이 있다.
“이 고객 데이터는 OpenAI로 보내면 안 돼요.”
“사내 문서는 절대 외부 API 넘기지 마세요. 법무팀 체크 사항입니다.”
“프롬프트 실험하다가 요금 30만 원 나왔어요. 이거 집에서 감당 안 됩니다.”
공용 API가 막히거나 부담스러운 상황은 의외로 흔하다. 금융·의료·공공 분야처럼 규제가 엄격한 업계, 내부 문서 기반 RAG를 만드는 회사, 비용을 걱정하는 개인 개발자. 이럴 때 꺼낼 수 있는 카드가 ‘로컬 LLM’이다.
이 글은 ‘로컬 LLM이 뭐고, 왜 쓰고, 어떻게 처음 시작하는가’에 초점을 둔다. 모델별 벤치마크 비교나 세부 튜닝은 이 글의 목표가 아니다. 그건 아래쪽 ‘개발자를 위한 추가 메모’ 블록에 몰아두었다.
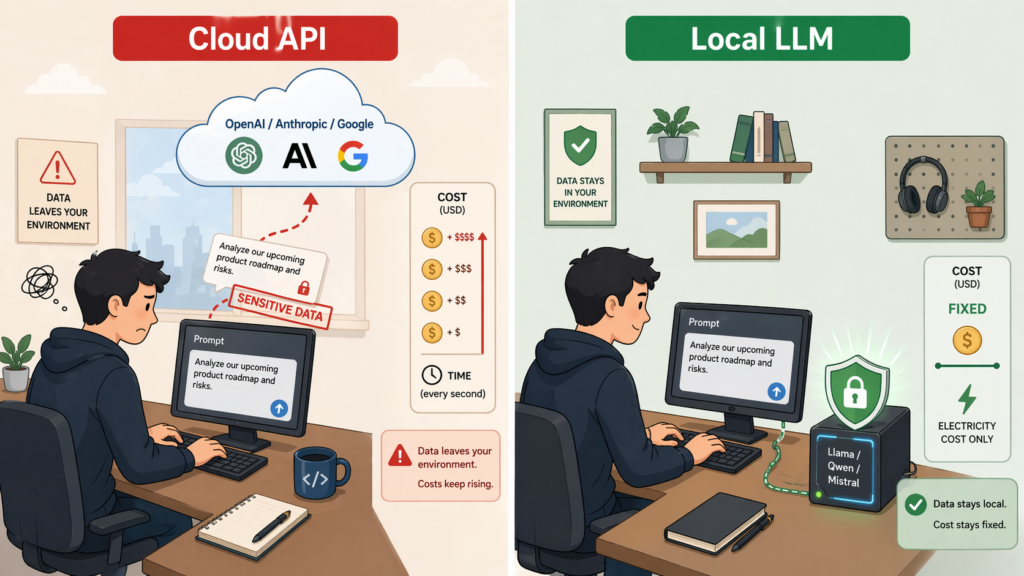
로컬 LLM이란? — 한 문장 정의
‘한 줄 요약: 로컬 = 내 컴퓨터 또는 우리 회사가 직접 관리하는 서버 안에서 AI를 돌리는 방식.’
평소 쓰는 ChatGPT, Claude, Gemini는 ‘클라우드 API’다. 내 질문이 인터넷 너머 회사 서버로 날아가고, 그쪽에서 답을 만들어 돌아온다. 반면 ‘로컬 LLM’은 AI 모델 파일을 내 노트북이나 사내 서버에 설치해서 그 안에서 바로 답을 만든다. 데이터가 외부로 한 번도 나가지 않는다.
즉 ‘로컬 LLM은 인터넷이 연결되지 않아도 상관없이 사용할 수 있다.’ 비행기 안이든, 외부망이 차단된 사내망이든, 와이파이가 끊긴 카페든, 모델 파일만 내 컴퓨터에 있으면 그대로 돈다.
쉽게 비유하면,
- ‘클라우드 API’ = 질문을 택배로 외부 전문가에게 보내고 답을 받는다. 편하고 빠르지만 내용이 택배를 탄다.
- ‘로컬 LLM’ = 전문가가 회사 안으로 이사 온다. 월세와 관리비는 내가 내지만 문서는 밖으로 나가지 않는다.
왜 로컬에서 돌리나
‘한 줄 요약: 데이터가 밖으로 안 나가고, 토큰 과금이 없고, 오프라인에서도 된다.’
로컬을 선택하는 이유는 대체로 이 셋 중 하나다.
- ‘데이터 보안’: 고객 정보, 사내 문서, 환자 기록 같은 건 외부 API로 보내기 곤란하다. 로컬이면 애초에 밖으로 안 나간다.
- ‘비용 예측’: 공용 API는 쓸수록 돈이 올라간다. 트래픽이 꾸준한 서비스라면 하드웨어/전기 같은 고정비로 바꾸는 게 더 쌀 수 있다.
- ‘오프라인/폐쇄망’: 인터넷이 안 되는 환경, 외부망 연결이 금지된 환경에서도 써야 할 때가 있다.
반대로, 로컬을 선택하지 않는 이유도 분명하다.
- ‘설치·운영이 번거롭다.’ API는 키 하나면 끝나지만, 로컬은 내가 깔고 돌리고 관리해야 한다.
- ‘최신 최강 모델은 보통 API 쪽이다.’ 2026년 기준 Gemini 3.1, GPT-5.4, Claude Opus 4.7 같은 frontier 모델을 그대로 내 컴퓨터에서 돌리는 건 사실상 불가능하다.
- ‘내 컴퓨터 성능에 크게 좌우된다.’ GPU가 약하면 느리거나 아예 안 돌아간다.
그래서 실무의 결정은 ‘최고 품질이 얼마나 필요한가’ vs ‘데이터/비용 통제가 얼마나 중요한가’의 저울질 문제다.
‘최근 트렌드 — 에이전트가 로컬로 가는 이유’: 2026년 들어 컴퓨터를 직접 조작하는 AI 에이전트(OpenClaw 등)가 크게 유행했다. 이런 도구는 대화 한 번에 도구 호출·파일 읽기·작업 루프가 반복되면서 토큰이 폭발적으로 쌓이는 구조라, API 요금 청구서에 놀란 사용자가 Mac Mini·Mac Studio 같은 워크스테이션을 구입해 ‘에이전트도 돌리고 로컬 LLM도 돌리는’ 구성으로 넘어가는 사례가 늘고 있다. ‘루틴 작업은 로컬, 어려운 것만 유료 API’라는 하이브리드 설계가 실무에서 가장 현실적인 해법으로 자리 잡는 중이다.
처음 시작한다면 Ollama
‘한 줄 요약: 개인 실험은 Ollama가 가장 쉽다. 여러 사람이 동시에 쓰는 서버가 필요해지면 그때 vLLM 같은 전용 엔진을 본다.’
로컬 LLM 도구는 수십 개 있지만, 처음 한 번 깔아볼 거라면 ‘Ollama’ 하나만 알아도 충분하다.
# macOS / Linux curl -fsSL https://ollama.com/install.sh | sh # 모델 실행 (첫 실행 시 자동 다운로드) ollama run llama3.2
‘Windows 사용자는 조금 다르다.’ 터미널 명령 대신 [ollama.com/download](https://ollama.com/download)에서 Windows 설치 파일(OllamaSetup.exe)을 받아 실행하면 된다. 설치 후에는 명령 프롬프트(cmd)나 PowerShell에서 ollama run llama3.2로 동일하게 쓸 수 있다. 참고로 로컬 LLM을 제대로 돌리려면 NVIDIA GPU 드라이버(CUDA)가 최신이어야 한다. 그래픽카드 드라이버를 오래 안 올렸다면 먼저 GeForce Experience나 NVIDIA 홈페이지에서 업데이트부터 하자.
설치 뒤는 OS 상관없이 똑같다. 터미널에서 바로 대화할 수 있고, http://localhost:11434에서 OpenAI 호환 API도 자동으로 열린다. 기존 OpenAI SDK의 base URL만 바꿔 끼우면 그대로 로컬 모델을 호출하는 식으로도 쓸 수 있다.
다만 Ollama는 ‘개인·소규모용’이다. 여러 사용자가 동시에 몰리는 사내 API 서버로 올리려면 처리량 최적화가 부족하다. 그런 용도로는 ‘vLLM’이나 ‘TGI’, ‘SGLang’ 같은 프로덕션 서빙 엔진이 쓰인다. 설치와 튜닝이 더 어렵지만 동시 요청 처리량이 훨씬 높다. 이 정도만 알아두고, 일단은 Ollama로 감을 잡는 편이 실용적이다.
양자화: 큰 모델을 내 컴퓨터에 욱여넣기 위한 압축
‘한 줄 요약: 원본 모델은 너무 커서 내 GPU에 안 들어간다. 숫자 정밀도를 낮춰 용량을 줄이면 들어간다. 대신 약간의 품질 저하.’
로컬 LLM을 만지면 반드시 마주치는 단어가 ‘양자화(quantization)’다. 이름은 어렵지만 개념은 단순하다.
AI 모델은 수십억 개의 숫자(‘가중치’)로 이루어져 있다. 원본은 이 숫자들을 정밀한 포맷(FP16)으로 저장하는데, 그만큼 파일이 크고 메모리도 많이 먹는다. 양자화는 이 숫자들을 대충 ‘소수점 자리 수를 줄이듯’ 간략화해서 용량을 줄이는 기법이다.
| 정밀도 | 7B 모델 크기 | 체감 품질 |
|---|---|---|
| FP16 (원본) | 약 14GB | 최고 |
| Q8 (8-bit) | 약 7GB | 원본과 거의 같음 |
| Q4 (4-bit) | 약 4GB | 약간 떨어지지만 실용 수준 |
예를 들어 원본은 16GB GPU가 필요한 모델이, Q4로 줄이면 8GB GPU에서도 돈다. 대부분의 로컬 실험은 ‘일단 Q4로 시작’하는 게 무난하다. Ollama의 기본 모델 태그도 대체로 이런 경량화된 버전을 가리킨다. 품질이 절대적으로 중요하면 :fp16 같은 태그로 원본 계열을 명시할 수 있다.
어느 정도 컴퓨터가 필요한가
‘한 줄 요약: CPU만 있어도 되긴 된다. GPU(그래픽카드) 8~16GB면 입문, 24GB+는 꽤 본격적.’
처음 질문은 거의 다 “GPU(그래픽카드) 없어도 돼요?”다. 답은 이렇다.
- ‘CPU만 (GPU 없음)’: 3B 이하 작은 모델은 된다. 다만 답이 한 글자씩 천천히 흘러나오는 수준이라 체감이 답답하다. “가능은 하다” 수준.
- ‘GPU(그래픽카드) 8~16GB (예: RTX 5060/5070)’: 입문용으로 충분하다. 7~8B급 Q4 모델이 실시간에 가깝게 돈다. 로컬 코드 보조나 개인 실험에 편하다.
- ‘GPU 24GB+ (예: RTX 5090)’: 20~30B급 모델까지 Q4로 시도해볼 수 있다. 꽤 본격적인 실험이 가능한 선.
- ‘A100/H100급 서버 GPU, 멀티 GPU’: 이건 ‘프로덕션 서빙’ 영역이다. 개인이 쓸 일은 거의 없다.
- ‘맥(Apple Silicon)’: 통합 메모리 구조라 램 용량이 곧 모델 크기다. 32GB 이상이면 의외로 강하다.
처음이라면 고민하지 말고 ‘가진 컴퓨터 + Q4’로 제일 작은 모델부터 돌려보는 게 낫다. 그래픽카드 업그레이드는 그 뒤에 생각해도 늦지 않다.
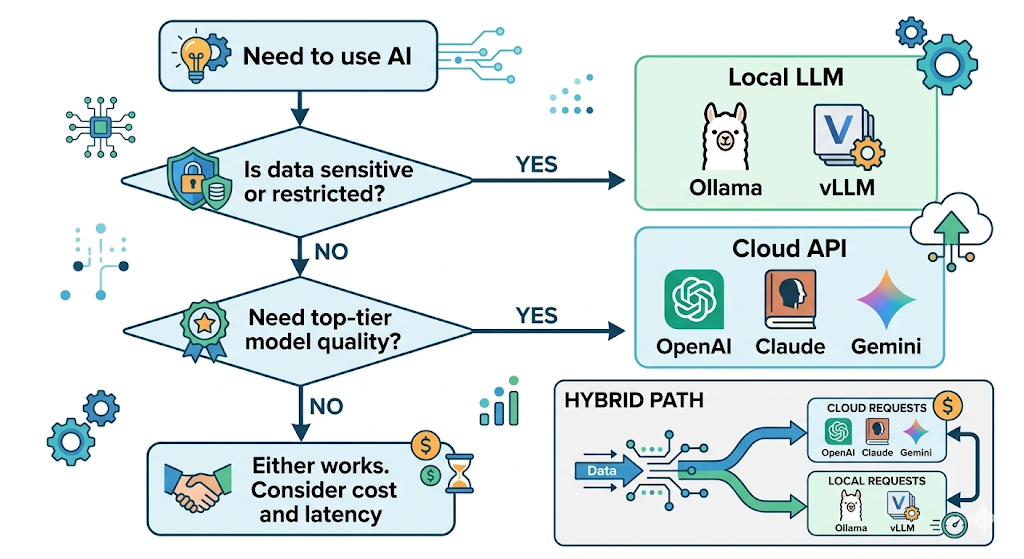
언제 로컬, 언제 API?
‘한 줄 요약: 최고 품질/빠른 실험은 API, 데이터 보안/고정 비용/커스터마이징은 로컬. 하이브리드도 정석이다.’
| 상황 | 추천 |
|---|---|
| 민감 데이터 외부 전송 금지 | 로컬 |
| 최신 최강 모델 품질이 필요 | 공용 API |
| 토큰 과금 예측이 어려운 고트래픽 서비스 | 로컬 고려 |
| 빠른 프로토타이핑 | 공용 API |
| 오프라인/폐쇄망 환경 | 로컬 |
| 일회성 실험/개인 학습 | 둘 다 OK (Ollama도 좋음) |
많은 회사가 실제로는 ‘하이브리드’로 간다. 예를 들어 ‘민감 데이터가 포함된 RAG는 사내 로컬 서버’, ‘일반 공개 문서 질의는 공용 API’ 식으로 역할을 나눈다. Spring AI 같은 프레임워크는 같은 ChatClient 인터페이스로 두 경로를 라우팅할 수 있어서, 이런 구조가 의외로 단순하게 짜인다.
한 가지 오해는 짚고 가자. ‘클라우드 API로 보낸 데이터가 무조건 학습에 쓰인다’는 건 틀린 말이다. 주요 공급자의 비즈니스/API 서비스는 기본적으로 고객 데이터를 모델 학습에 쓰지 않는 정책을 제공한다. 다만 데이터가 조직 밖으로 ‘전송된다는 사실’ 자체가 규제나 내부 정책상 문제가 될 수 있다. 그래서 로컬 LLM의 장점은 ‘학습에 안 쓰임’보다 ‘외부 전송 자체를 줄일 수 있다’에 더 가깝다.
막상 해 보면 부딪히는 것들
‘한 줄 요약: 로컬이 API보다 “편한” 게 아니라 “다른 고생”이다. 모델 선택, 메모리, 속도, 업데이트, 보안 전부 내 몫.’
로컬 LLM을 실제로 운영해 보면, 생각보다 할 일이 많다.
- ‘모델 선택부터 일이다.’ Hugging Face에 매주 새 모델이 올라온다. 이름, 크기, 라이선스, 한국어 성능이 다 달라서 고르는 데 시간이 든다.
- ‘메모리 계산 실수’. “이 모델 내 GPU에 들어갈까?”를 파일 크기만으로 판단하면 안 된다. 긴 문장을 처리하는 동안 쌓이는 내부 버퍼(KV cache 등)가 추가로 필요하다. 여유분으로 ‘파일 크기의 1.5~2배’는 잡는 게 안전하다.
- ‘속도가 생각보다 느릴 수 있다.’ 소비자용 GPU에서 돌리는 7B Q4 모델은 초당 20~40 토큰 정도다. 짧은 답에는 충분하지만 긴 답변에서는 체감이 처진다.
- ‘업데이트도 내 책임.’ API는 공급사가 모델을 올려주지만, 로컬은 내가 직접 새 모델 받고 호환성 확인하고 바꿔야 한다.
- ‘보안이 끝나는 게 아니다.’ “로컬이니까 안전하다”는 반만 맞다. 프롬프트 인젝션, 잘못된 답, 권한 없는 문서 조회 같은 문제는 그대로 남는다. 가드레일과 로그 관리가 필요하다.
개인 경험: 저는 이렇게 쓰고 있습니다
글을 끝내기 전에, 제가 평소에 로컬 LLM을 쓰는 방식을 짧게 공유한다. 대단한 세팅은 아니다.
‘개인 PC에서 Ollama로 7~13B Q4 모델을 돌려 로컬 AI 보조로 쓴다.’ API 키 걱정 없고, 과금 걱정 없고, 실험적 프롬프트를 무한정 던져볼 수 있다. 성능은 공용 API보다 분명히 떨어지지만 ‘빠른 초안, 오프라인 질문, 민감 코드 리뷰’에는 충분하다.
반대로 ‘진짜 중요한 작업(프로덕션 코드 설계)은 Claude Pro/Max’를 쓴다. 결과물의 품질 차이가 여전히 크기 때문이다. 로컬은 ‘저렴한 실험 파트너’, 공용 API는 ‘정식 작업용’으로 역할 분담이 자연스럽게 된다.
📦 개발자를 위한 추가 메모
일반 독자는 여기부터 건너뛰어도 된다. 아래는 직접 로컬 LLM을 운영하려는 개발자용 보충이다.
2026년 4월 기준 주목할 오픈웨이트 모델
| 계열 | 포지션 | 특징 |
|---|---|---|
| Gemma 4 | Google의 최신 오픈웨이트 | E2B/E4B/26B A4B/31B, Apache 2.0, 멀티모달, 128K~256K 컨텍스트 |
| Qwen3.6 | 추론·코딩 강자 | 27B, 35B A3B 등. Apache 2.0, vLLM/SGLang/llama.cpp/MLX 지원 |
| Mistral 3 | 유럽권 Apache 2.0 | Ministral 3 3B/8B/14B, Mistral Large 3 MoE(675B total / 41B active) |
| Llama 4 | Meta의 멀티모달 MoE | Scout/Maverick 등. Meta 자체 라이선스라 상용 조건 확인 필요 |
전부 같은 의미의 ‘오픈소스’는 아니다. Gemma 4/Qwen3.6/Mistral 3는 Apache 2.0 계열, Llama 4는 Meta 자체 라이선스. 상용 서비스라면 성능만 보지 말고 라이선스부터 확인.
Gemma 4 vs Gemini 2.5 Pro — 조심해서 읽을 비교
| 항목 | Gemma 4 31B | Gemma 4 26B A4B | Gemini 2.5 Pro |
|---|---|---|---|
| 컨텍스트 | 256K | 256K | 약 1M 입력 / 65K 출력 |
| GPQA Diamond | 84.3 | 82.3 | 86.4 |
| HLE (no tools) | 19.5 | 8.7 | 21.6 |
| LiveCodeBench | 80.0 | 77.1 | 74.2 |
| AIME | 2026: 89.2 | 2026: 88.3 | 2025: 88.0 |
| MMMU 계열 | MMMU Pro 76.9 | MMMU Pro 73.8 | MMMU 82.0 |
해석: Gemma 4 31B는 ‘오픈웨이트치고는’ 매우 강해서 Gemini 2.5 Pro의 일부 지표에 근접한다. 단 벤치마크 버전·측정 조건이 달라 직접 승패 단정 불가. 또한 2026년 4월 기준 frontier API는 이미 Gemini 3.1 / GPT-5.4 / Claude Opus 4.7 쪽으로 한 세대 더 올라가 있다. “로컬이 클라우드를 완전히 대체한다”가 아니라 “일부 작업에서는 로컬도 충분히 쓸 만하다”가 정확하다.
Gemma 4 공식 메모리 표 (가중치 기준)
| 모델 | BF16 | SFP8 | Q4_0 |
|---|---|---|---|
| Gemma 4 E2B | 9.6GB | 4.6GB | 3.2GB |
| Gemma 4 E4B | 15GB | 7.5GB | 5GB |
| Gemma 4 31B | 58.3GB | 30.4GB | 17.4GB |
| Gemma 4 26B A4B | 48GB | 25GB | 15.6GB |
주의: 위 수치는 가중치 기준이다. 실제 실행에는 컨텍스트 길이에 따른 KV cache, 런타임 오버헤드, 배치 크기가 추가로 붙는다. ‘Q4_0 17.4GB = 18GB GPU에서 편히 돈다’는 뜻이 아니다.
vLLM 예시와 플랫폼
# Llama 3.1 8B를 OpenAI 호환 API 서버로 pip install vllm vllm serve meta-llama/Llama-3.1-8B-Instruct # Gemma 4 26B A4B 같은 최신 오픈웨이트 모델 vllm serve google/gemma-4-26b-a4b-it
실제 Hugging Face 모델 ID는 공개 저장소에서 정확한 이름을 확인하고 쓰는 편이 안전하다. 출시 직후 조직명·태그가 바뀌는 경우가 있다. vLLM은 가장 검증된 경로가 NVIDIA CUDA지만, 2026년 기준 AMD ROCm, Intel XPU, CPU, TPU, Gaudi, Apple Silicon 등 지원 범위가 넓어지고 있다. 실제로는 ‘지원 여부’보다 ‘내 하드웨어+모델+양자화 조합이 안정적으로 빠른가’가 중요하다.
비용 — 로컬은 공짜가 아니다
API 비용 = 입력 토큰 + 출력 토큰 + 도구/검색/캐시 비용 로컬 비용 = GPU + 전기/냉각 + 운영 인력 + 서빙 인프라 + 평가/보안 비용
로컬이 이기는 경우는 ‘GPU를 충분히 높은 사용률로 계속 돌릴 수 있을 때’다. GPU가 대부분 놀고 있다면 로컬이 API보다 비쌀 수 있다.
모델 선택 체크리스트
| 기준 | 질문 |
|---|---|
| 성능 | 일반 대화/코딩/수학/RAG/멀티모달 중 내 작업은? |
| 언어 | 한국어 성능이 실제로 검증됐는가? |
| 크기 | 내 GPU/메모리에 실제로 올라가는가? |
| 컨텍스트 | 필요한 문서 길이를 감당하는가? |
| 라이선스 | 상용 사용 가능? 재배포 조건은? |
| 포맷 | Ollama/GGUF, vLLM/safetensors, MLX 등 내 도구와 맞나? |
| 평가 | 내 대표 질문 세트로 API 모델과 직접 비교했나? |
로컬 모델은 ‘리더보드 1등’을 고르는 문제가 아니라 ‘내 환경에서 가장 안정적으로 도는’ 모델을 고르는 문제다.
기타 실무 포인트
- ‘모델 포맷’: GGUF(llama.cpp/Ollama), safetensors(Hugging Face 표준), AWQ/GPTQ/EXL2(특정 양자화 방식). 도구마다 호환이 다르다.
- ‘서빙 성능 개선’: PagedAttention(vLLM), continuous batching, speculative decoding, prefix caching. 동일 하드웨어로 throughput을 수 배 올릴 수 있다.
- ‘관측성’: vLLM은 Prometheus 메트릭 노출. Ollama도 토큰/로드 시간 로그 제공. OpenTelemetry 연동으로 기존 APM에 붙일 수 있다.
- ‘RAG 통합’: BGE, E5, mxbai-embed 같은 오픈 임베딩 + pgvector/Qdrant 조합으로 완전 로컬 RAG 가능. Spring AI의
OllamaEmbeddingModel이 편하다. - ‘파인튜닝’: LoRA/QLoRA로 소비자 GPU에서도 도메인 학습 가능. Axolotl, Unsloth가 흔히 쓰인다.
- ‘보안’: 로컬도 프롬프트 인젝션·권한 없는 문서 조회·웹 UI 노출·공급망 리스크가 그대로 남는다. 도구 호출에는 승인 단계를 붙여야 한다.
마치며: 로컬 LLM은 “대체재”가 아니라 “옵션”
정리하면:
- 로컬 LLM = 내 컴퓨터/사내 서버 안에서 AI를 돌리는 방식. ‘데이터가 밖으로 안 나간다’는 점이 가장 큰 차별점이다.
- ‘데이터 보안, 비용 예측, 오프라인’이 중요할 때 꺼내는 카드다. 대신 ‘최신 최강 품질, 운영 편의성’은 어느 정도 포기한다.
- 처음 시작한다면 Ollama 하나로 충분하다. 여러 사람이 쓰는 서버가 필요해지면 vLLM 같은 엔진으로 넘어가는 순서가 자연스럽다.
- 양자화(Q4)는 ‘내 GPU에 욱여넣기 위한 압축’이라고 생각하면 쉽다. 대부분의 로컬 실험은 Q4로 시작한다.
- 많은 실무 팀은 하이브리드로 간다. 민감 작업은 로컬, 일반 작업은 공용 API.
로컬 LLM을 ‘공용 API의 완전한 대체재’로 생각하면 실망한다. ‘선택지를 하나 더 가진 상태’로 접근하는 편이 맞다. 내 요구가 공용 API로 충분하면 굳이 로컬로 갈 이유는 없다. 반대로 데이터 제약이나 비용 예측 가능성이 중요하다면 로컬은 강력한 카드다.
다음 글에서는 지금까지 다룬 모든 AI 기술이 놓치기 쉬운 주제, ‘신뢰성·보안·윤리·저작권’ 이야기를 다룬다. AI가 만든 결과물을 그대로 써도 되는지, 환각을 어떻게 걸러내는지, 데이터 학습에 대한 최근 법적 흐름까지. 개발자가 놓치면 나중에 큰 비용을 치를 수 있는 주제들이다.