기능은 완성했는데, ‘느리다’는 말이 돌아왔다
CI/CD 파이프라인도 갖추고, 브랜치 전략도 정비하고, 개발 서버와 운영 서버도 분리했다. 배포는 더 이상 두렵지 않았다. 이제야 좀 안정적으로 기능 개발에 집중할 수 있겠다 싶었는데, 예상치 못한 곳에서 문제가 터졌다.
“OO씨, 목록 페이지가 너무 느려요. 한 3초? 걸리는 것 같은데 이거 좀 빨리 안 될까요?”
담당자의 피드백이었다. 3초. 사실 나한테는 크게 느리다고 느껴지지 않았다. 하지만 사용자 입장에서 목록 버튼을 누르고 3초를 기다리는 건 꽤 고통스러운 일이다. 구글 리서치에 따르면, 페이지 로딩 시간이 3초를 넘기면 사용자의 53%가 이탈한다고 한다.
나는 일단 원인을 찾기 위해 서버 로그를 열었다.
[2025-01-15 14:32:01] GET /api/projects - 2847ms
[2025-01-15 14:32:15] GET /api/projects - 3102ms
[2025-01-15 14:32:33] GET /api/projects - 2956ms
API 응답 시간이 거의 3초에 육박했다. 코드를 따라가 보니 원인은 명확했다. 프로젝트 목록을 불러올 때마다, 매번 데이터베이스에서 전체 데이터를 조회하고, 관련 테이블을 JOIN하고, 정렬까지 하고 있었다. 데이터가 수백 건이었을 때는 문제없었지만, 수천 건을 넘어가면서 쿼리 자체가 무거워진 것이다.
“잠깐, 이 목록 데이터가 1분에 한 번이라도 바뀌나?”
생각해 보니 프로젝트 목록은 하루에 한두 건 추가될까 말까 한 데이터였다. 그런데 사용자가 페이지를 열 때마다 매번 DB에 같은 질문을 던지고 있었다. 마치 식당에서 "오늘 메뉴 뭐예요?"라고 물을 때마다 주방장이 매번 냉장고를 열어보는 것과 같았다.
‘메뉴판을 한 번 만들어서 카운터에 붙여놓으면 되는 거 아닌가?’
이 ‘메뉴판’의 정식 이름이 바로 ‘캐시(Cache)’였다.

캐시(Cache)란 무엇인가
캐시는 ‘자주 쓰는 데이터를 가까운 곳에 미리 복사해두는 것’이다. 컴퓨터 세계에서 캐시는 어디에나 존재한다.
| 종류 | 위치 | 속도 | 예시 |
|---|---|---|---|
| CPU 캐시 | CPU 내부 | 가장 빠름 | L1, L2, L3 캐시 |
| 브라우저 캐시 | 사용자 PC | 빠름 | 이미지, CSS, JS 파일 저장 |
| 애플리케이션 캐시 | 서버 메모리 | 빠름 | Redis, Memcached |
| CDN | 전 세계 엣지 서버 | 빠름 | 정적 파일 배포 |
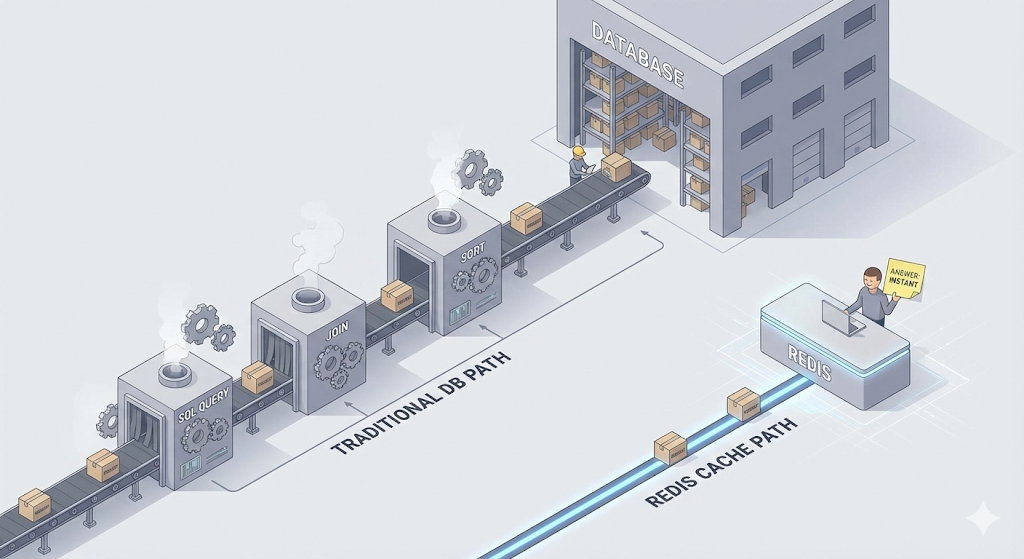
우리가 지금 다룰 것은 세 번째, ‘애플리케이션 레벨의 캐시’다. 서버와 데이터베이스 사이에 ‘빠른 메모장’을 하나 끼워 넣는 것이다.
Redis: 메모리 위의 초고속 메모장
그 ‘메모장’ 역할을 하는 대표적인 도구가 바로 ‘Redis(레디스)’다.
Redis는 데이터를 하드디스크가 아닌 ‘메모리(RAM)’에 저장하는 데이터베이스다. 앞서 배웠던 것을 떠올려 보자. RAM은 디스크보다 수만 배 빠르다. 디지털 물류 센터 비유로 말하자면, 영구 보관 창고(디스크/DB)까지 가지 않고 작업자 바로 옆 개인 작업대(RAM/Redis)에서 데이터를 꺼내는 것이다.
일반 DB(PostgreSQL, MySQL) 조회: ~10ms Redis 조회: ~0.1ms (약 100배 빠름)
Redis의 핵심 특징을 정리하면 이렇다.
| 특징 | 설명 |
|---|---|
| In-Memory | 데이터를 메모리에 저장. 디스크 I/O 없이 초고속. |
| Key-Value 구조 | 키: 값 형태로 단순 저장. 복잡한 쿼리 불필요. |
| TTL(Time To Live) | 데이터에 유효 기간 설정 가능. 시간이 지나면 자동 삭제. |
| 다양한 자료구조 | String, List, Set, Hash, Sorted Set 등 지원. |
캐싱 전략: 언제 메모하고, 언제 버릴 것인가
캐시를 도입하는 건 쉽다. 하지만 ‘어떻게 운영할 것인가’가 진짜 문제다. 잘못 관리하면 사용자에게 오래된(틀린) 데이터를 보여주거나, 캐시가 아무 역할도 못 하는 상황이 벌어진다.
대표적인 캐싱 전략 두 가지를 알아보자.
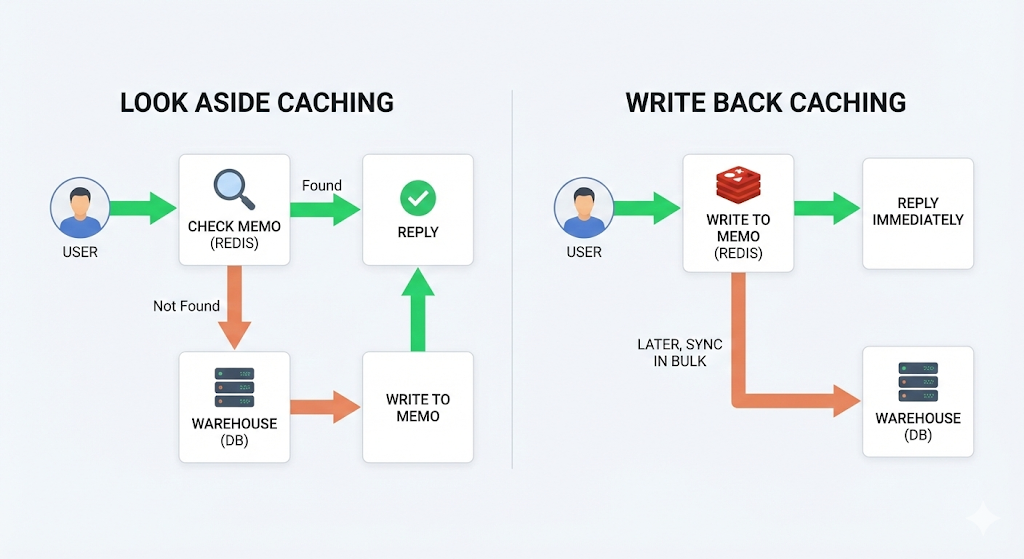
전략 1: Look Aside (= Cache Aside) — 가장 보편적
‘먼저 캐시를 확인하고, 없으면 DB에서 가져와서 캐시에 저장한다.’
동작 흐름은 이렇다.
- 사용자가 데이터를 요청한다.
- 서버가 Redis에 해당 데이터가 있는지 확인한다. (Cache Hit?)
- 있으면(Hit) → Redis에서 바로 응답. 끝.
- 없으면(Miss) → DB에서 조회 → 결과를 Redis에 저장 → 응답.
// Look Aside 패턴 (의사 코드)
public List<Project> getProjects() {
// 1. 캐시 확인
String cacheKey = "projects:list";
List<Project> cached = redis.get(cacheKey);
if (cached != null) {
return cached; // Cache Hit! DB 안 가도 됨
}
// 2. Cache Miss → DB 조회
List<Project> projects = projectRepository.findAll();
// 3. 결과를 캐시에 저장 (5분 동안 유효)
redis.set(cacheKey, projects, Duration.ofMinutes(5));
return projects;
}
첫 번째 사용자는 DB까지 가야 하지만(Miss), 두 번째 사용자부터는 Redis에서 바로 받는다(Hit). 5분 내에 100명이 같은 페이지를 열어도 DB 쿼리는 딱 1번만 실행된다.
| 장점 | 단점 |
|---|---|
| 구현이 단순하다 | 첫 요청은 여전히 느리다 (Cold Start) |
| 읽기(Read)가 압도적으로 많은 경우 최적 | 캐시와 DB 사이 데이터 불일치 가능성 |
| Redis가 죽어도 DB에서 직접 조회 가능 | TTL 설정이 중요 (너무 길면 오래된 데이터, 너무 짧으면 효과 없음) |
전략 2: Write Back (= Write Behind) — 쓰기 성능 최적화
‘데이터를 바로 DB에 쓰지 않고, 일단 캐시에만 쓴 뒤 나중에 한꺼번에 DB에 반영한다.’
동작 흐름은 이렇다.
- 데이터 변경 요청이 들어온다.
- Redis에만 먼저 저장한다. (응답 완료, 빠름)
- 일정 시간이 지나거나, 일정량이 쌓이면 한꺼번에 DB에 반영한다. (Batch Write)
[사용자] → [Redis에 쓰기] → 즉시 응답 (빠름!)
↓
(일정 시간 후)
↓
[DB에 일괄 반영]
비유하자면, 편의점 POS기의 판매 기록이다. 물건을 팔 때마다 본사에 보고하지 않는다. 하루치를 모았다가 밤에 한 번 전송한다.
| 장점 | 단점 |
|---|---|
| 쓰기(Write) 성능이 매우 빠르다 | Redis가 죽으면 미반영 데이터 유실 위험 |
| DB 부하를 크게 줄일 수 있다 | 구현 복잡도가 높다 |
| 대량 쓰기에 유리 (로그, 조회수 등) | DB와의 데이터 정합성 관리 필요 |
실전 적용: 3초를 0.1초로 줄인 이야기
이론을 알았으니 실제로 적용해 보자. 내 상황에 가장 맞는 전략은 ‘Look Aside’였다. 프로젝트 목록은 읽기 요청이 압도적으로 많고, 데이터 변경은 드물었기 때문이다.
Redis 설치 (Docker로 3초 완성)
이미 Docker를 쓰고 있으니, Redis도 한 줄이면 된다.
# Redis 컨테이너 실행
docker run -d --name redis \
-p 6379:6379 \
--restart always \
redis:alpine
Spring Boot에서 Redis 연동
# application.yml
spring:
data:
redis:
host: localhost
port: 6379
// 캐시 적용 - @Cacheable 어노테이션 한 줄이면 끝
@Service
public class ProjectService {
@Cacheable(value = "projects", key = "'list'")
public List<Project> getProjects() {
// 이 메서드의 결과가 자동으로 Redis에 캐싱된다.
// 두 번째 호출부터는 이 메서드 자체가 실행되지 않는다.
return projectRepository.findAll();
}
@CacheEvict(value = "projects", allEntries = true)
public void createProject(ProjectDto dto) {
// 새 프로젝트 생성 시, 캐시를 무효화한다.
// 다음 조회 때 DB에서 새로 가져와 캐시를 갱신한다.
projectRepository.save(dto.toEntity());
}
}
| 어노테이션 | 역할 |
|---|---|
@Cacheable |
결과를 캐시에 저장. 다음 호출 시 캐시에서 반환. |
@CacheEvict |
캐시를 삭제. 데이터 변경 시 오래된 캐시를 지운다. |
@CachePut |
캐시를 갱신. 메서드를 실행하고 결과로 캐시를 업데이트. |
결과는 극적이었다.
[Before] GET /api/projects - 2847ms
[After] GET /api/projects - 47ms (Cache Miss, 첫 조회)
[After] GET /api/projects - 3ms (Cache Hit, 이후 조회)
3초 → 0.003초. 약 1000배 빨라졌다.
실무 조언: 캐시의 함정들
캐시는 ‘은탄환(Silver Bullet)’이 아니다. 도입 전에 반드시 알아야 할 함정들이 있다.
1. 캐시 무효화(Invalidation) — 가장 어려운 문제
컴퓨터 과학에서 어려운 것은 딱 두 가지다. 캐시 무효화와 이름 짓기. — Phil Karlton
데이터가 변경되었는데 캐시에는 옛날 데이터가 남아 있으면? 사용자는 이미 삭제된 프로젝트를 목록에서 계속 보게 된다. 그래서 데이터가 변경될 때 반드시 관련 캐시를 지우거나 갱신해야 한다. 위 코드의 @CacheEvict가 바로 그 역할이다.
2. TTL(유효 시간) 설정
캐시에 유효 시간을 설정하지 않으면, 한번 저장된 데이터가 영원히 남는다. 반드시 적절한 TTL을 설정하자.
| 데이터 유형 | 권장 TTL | 이유 |
|---|---|---|
| 거의 안 바뀌는 설정값 | 1시간~1일 | 변경 빈도 낮음 |
| 목록/리스트 | 5분~30분 | 적당한 실시간성 |
| 사용자 세션 | 30분 | 보안상 자동 만료 필요 |
| 실시간 데이터 (주가, 채팅) | 캐싱 부적합 | 매번 최신 데이터 필요 |
3. 캐시를 쓰면 안 되는 경우
모든 데이터에 캐시를 다는 건 오히려 독이다.
- 실시간 정합성이 중요한 데이터 (결제, 재고)
- 매번 다른 결과가 나오는 데이터 (개인화 추천)
- 한 번만 조회되고 재사용되지 않는 데이터
캐시의 핵심 원칙: ‘같은 질문이 반복되는가?’ 반복되지 않는다면 캐시는 오히려 메모리 낭비다.
4. Redis가 죽으면?
Redis는 메모리 기반이라, 서버가 재시작되면 데이터가 날아간다. Look Aside 전략을 쓰고 있다면 걱정할 필요 없다. Redis가 없으면 자연스럽게 DB에서 가져오면 되니까. 하지만 Write Back을 쓰고 있었다면? 아직 DB에 반영되지 않은 데이터가 증발한다. 그래서 중요한 데이터를 Write Back으로 처리할 때는 Redis의 영속성(Persistence) 설정(RDB/AOF)을 반드시 켜둬야 한다.
마치며: ‘빠르게’가 아니라 ‘불필요하게 느리지 않게’
성능 최적화라고 하면 거창한 기술이 필요할 것 같지만, 실상은 단순했다. ‘변하지 않는 데이터를 매번 새로 계산하지 마라.’ 이 하나의 원칙을 지키는 것만으로 3초가 0.003초로 줄었다.
Redis를 도입한 후 담당자가 말했다. “어? 갑자기 왜 이렇게 빨라졌어요?” “캐시를 달았습니다.” “캐시? 그게 뭔데요?” “메뉴판을 만들었다고 생각하시면 됩니다.”
하지만 서비스가 빨라진 게 끝이 아니었다. 담당자 확인용 개발 서버, 실제 운영 서버, 그리고 이제 Redis 서버까지. 점점 늘어나는 서버들 사이에서 요청이 어디로 가야 하는지 교통정리가 필요해졌다.
다음 시간에는 이 교통정리의 핵심, ‘Nginx와 리버스 프록시’에 대해 알아보자. 우리 서비스 앞에 ‘문지기’를 세워서, 들어오는 요청을 적절한 곳으로 안내하는 방법이다.