„Hä? Ist der Build gerade wirklich schon fertig?“
Nachdem ich erlebt hatte, wie praktisch Docker war, begann ich heimlich, ohne dass mein Teamleiter es wusste, meine Entwicklungsumgebung nach und nach auf Docker umzustellen. Ich schrieb einen Bauplan namens Dockerfile und führte den Befehl docker build aus.
Beim ersten Mal dauerte es ziemlich lange. Ubuntu musste heruntergeladen werden, Java wurde installiert und die Bibliotheken, JARs, meines Projekts mussten geladen werden. Insgesamt dauerte das ungefähr fünf Minuten. „Na gut, beim ersten Mal dauert es eben länger.“
Doch als ich nur einen einzigen Tippfehler im Code korrigierte und den Build erneut startete, traute ich meinen Augen nicht. Kaum hatte ich Enter gedrückt, erschien im Terminal schon die Meldung Successfully built. Benötigte Zeit: gerade einmal 0,1 Sekunden.
„Moment, ist das kaputt? Vorhin hat es noch fünf Minuten gedauert. Wie kann das plötzlich augenblicklich fertig sein?“
Aus Unsicherheit startete ich den Server, aber der Code war perfekt aktualisiert. Was genau geschah also in Docker? Das Geheimnis hinter dieser verrückten Geschwindigkeit lag in einer besonderen Speicherweise namens ‘Layer’.
Image und Container
Bevor wir uns die eigentliche Funktionsweise anschauen, klären wir erst zwei Begriffe, die oft durcheinandergeraten.
Was wir beim Deployment an den Server schicken, ist kein ‘Container’, sondern ein ‘Image’. Der Server muss dieses Image nur empfangen und ausführen.
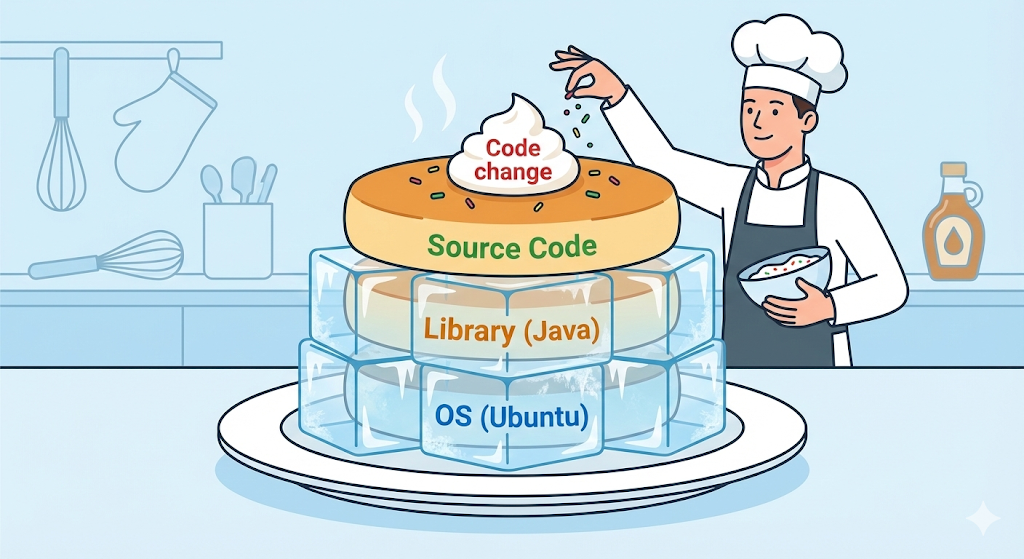
Layer: die Magie transparenter Zellophanfolien
Ein Docker-Image ist keine einzige monolithische Datei. Es ist eher so, als würde man mehrere transparente Zellophanfolien, also Layer, übereinanderlegen. Jede einzelne Befehlszeile im Dockerfile wird zu einer eigenen Schicht.
Nehmen wir ein Beispiel.
# Schicht 1: Ubuntu (OS) installieren
FROM ubuntu:20.04
# Schicht 2: Java installieren
RUN apt-get install openjdk-17-jdk
# Schicht 3: meinen Code kopieren
COPY my-app.jar /app/my-app.jar
# Schicht 4: ausfuehren
CMD ["java", "-jar", "/app/my-app.jar"]
Wenn man die Inhalte eines Dockerfile genau liest, merkt man, dass die Struktur gar nicht so kompliziert ist. „Installiere Ubuntu, FROM, installiere Java, RUN, hole meinen Code hinein, COPY, und führe ihn aus, CMD.“
Am Ende haben wir also einfach den Server-Setup-Prozess, den wir früher in einer VM oder direkt im Server-Terminal von Hand eingetippt haben, in ein Dokument geschrieben. Mit nur diesem einen Dokument führt Docker alle Installationsschritte automatisch aus. Dieses Konzept hängt später auch direkt mit dem Kernprinzip von CI/CD-Automatisierung zusammen.
Aber warum fasst Docker diesen Ablauf nicht einfach zu einem einzigen Schritt zusammen? Warum wird alles bewusst Zeile für Zeile in Layer aufgeteilt und sauber aufeinander gestapelt?
Der Grund ist Wiederverwendung durch Caching. Wenn ich den Code ändere und neu baue, denkt Docker clever: „Die erste Etage, also das OS, und die zweite Etage, also Java, sind genau gleich wie vorher. Dann muss ich sie nicht neu erzeugen. Ich kann einfach die bereits vorhandenen Cache-Layer weiterverwenden.“
Nur ab der veränderten dritten Etage, also ab dem Kopieren des Codes, baut Docker neu. Deshalb war der zweite Build in nur 0,1 Sekunden fertig.
[Code Verification] Den Layer-Cache mit eigenen Augen sehen
Verlassen wir uns nicht nur auf Worte, sondern überprüfen wir es mit Code. Dafür reicht es, ein einfaches Dockerfile zu erstellen und zweimal zu bauen.
FROM alpine:latest
RUN echo "1. Basis-Utils werden installiert..." && sleep 2 # Dauert 2 Sekunden
COPY test.txt /app/test.txt
CMD ["cat", "/app/test.txt"]
$ docker build -t my-test:v1 .
# Ergebnis:
# [2/3] RUN echo "1. Basis-Utils werden installiert..." ... 2.1s (2s gedauert)
$ docker build -t my-test:v2 .
# Ergebnis:
# [2/3] RUN echo "1. Basis-Utils werden installiert..." ... CACHED (0s!)
Sehen Sie das Wort CACHED, das deutlich im Log auftaucht? Das ist der Beweis dafür, dass Docker die sonst zwei Sekunden dauernde Arbeit übersprungen hat.
Praxis-Tipp: Die Reihenfolge ist entscheidend
Wenn man das Prinzip des Layer-Cachings verstanden hat, wird klar, wie ein Dockerfile aufgebaut sein sollte. Der Kern ist einfach: „Was sich selten ändert, gehört nach unten, also früh. Was sich häufig ändert, gehört nach oben, also spät.“
Schlechtes Beispiel:
# 1. Zuerst Quellcode kopieren (aendert sich haeufig)
COPY . .
# 2. Bibliotheken installieren (aendert sich selten)
RUN npm install
Quellcode ändert sich dutzende Male am Tag. Wenn sich Schritt 1 ändert, verwirft Docker auch den Cache für Schritt 2, also die Bibliotheksinstallation, und führt alles neu aus. Man korrigiert eine Zeile Code und wartet erneut auf npm install.
Gutes Beispiel:
# 1. Nur package.json zuerst kopieren
COPY package.json .
# 2. Bibliotheken installieren (bleibt gecached)
RUN npm install
# 3. Quellcode kopieren
COPY . .
Schon allein das Umstellen der Reihenfolge kann den Build zehnmal schneller machen. Genau das ist der Unterschied zwischen einem Docker-Anfänger und jemandem, der Docker wirklich beherrscht.
Praxis-Tipp 2: Tags sind Ihre Lebensleine
Im obigen Beispiel steht docker build -t my-test:v1 .. Das v1 hinter dem Doppelpunkt, :, ist der Tag.
Viele Anfänger sparen sich Tags, weil sie lästig erscheinen. In diesem Fall versieht Docker das Image automatisch mit dem Tag latest.
Diese eine Gewohnheit mit Tags wird später einmal Ihre Feierabende retten.
Zum Schluss: Die Magie von 0,1 Sekunden in der Hand halten
Ein Docker-Image ist nicht bloß ein Bündel von Dateien, sondern ein technisches Kunstwerk, Schicht für Schicht aufgebaut, um eine Umgebung möglichst effizient auszuliefern. Wenn man Layer-Caching versteht und die Reihenfolge im Dockerfile richtig setzt, kann man eine leichte, schnelle Deployment-Umgebung aufbauen, die in 0,1 Sekunden fertig ist.
Jetzt ist alles bereit, meine eigene Computerumgebung perfekt als Image einzufrieren und an den Server zu schicken.
Doch als ich dieses Image tatsächlich auf dem Server starten wollte, tauchte ein neues Problem auf. Ein Webservice läuft nicht mit nur einem einzelnen Server-Container. Man braucht auch eine Datenbank, Redis und einen Frontend-Server.
Lassen sich all diese Container wirklich einzeln per Befehl ein- und ausschalten? Wie kommunizieren sie miteinander? Wie baut man aus einem einzelnen Image eine ganze Anwendung? Beim nächsten Mal erweitern wir das Docker-Weltbild um die Konzepte Container, Service und Stack.