« Hein ? Le build vient vraiment de se terminer ? »
Après avoir goûté au confort de Docker, j’ai commencé à déplacer progressivement mon environnement de développement vers Docker en cachette de mon chef d’équipe. J’ai rédigé un plan appelé Dockerfile et lancé la commande docker build.
La première fois, cela a pris un certain temps. Entre le téléchargement d’Ubuntu, l’installation de Java et le téléchargement des bibliothèques, des JAR, de mon projet, cela a pris environ cinq minutes. « Bon, c’est normal que ce soit plus long la première fois. »
Mais quand j’ai corrigé une simple faute de frappe dans le code et relancé le build, j’ai cru halluciner. À peine avais-je appuyé sur Entrée que le message Successfully built s’affichait déjà dans le terminal. Temps total écoulé : à peine 0,1 seconde.
« Attends, c’est cassé ou quoi ? Tout à l’heure ça prenait cinq minutes. Comment ça peut soudain se terminer instantanément ? »
J’ai lancé le serveur avec une certaine inquiétude, mais le code avait bien été modifié. Alors que se passait-il exactement dans Docker ? Le secret de cette vitesse folle se trouvait dans un mode de stockage très particulier appelé « layer ».
Image et container
Avant d’entrer dans le mécanisme lui-même, clarifions d’abord deux termes qui prêtent souvent à confusion.
Ce que nous envoyons au serveur pendant le déploiement n’est pas un « container », mais une « image ». Le serveur n’a plus qu’à recevoir cette image et à l’exécuter.
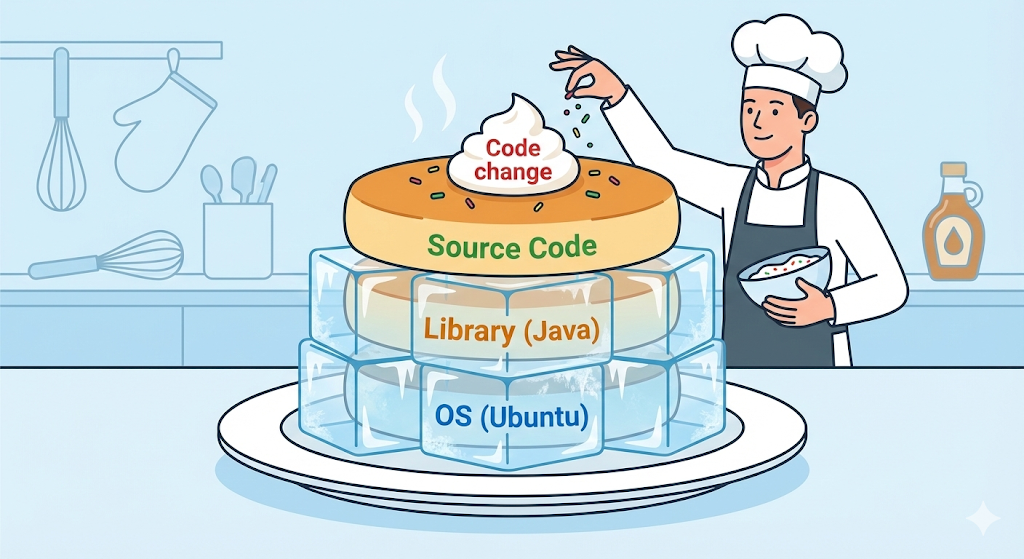
Layer : la magie du cellophane transparent
Une image Docker n’est pas un seul gros fichier monolithique. Elle ressemble plutôt à plusieurs feuilles de cellophane transparent, des layers, empilées les unes sur les autres. Chaque ligne d’instruction écrite dans un Dockerfile devient sa propre couche.
Prenons un exemple.
# Couche 1 : installer Ubuntu (OS)
FROM ubuntu:20.04
# Couche 2 : installer Java
RUN apt-get install openjdk-17-jdk
# Couche 3 : copier mon code
COPY my-app.jar /app/my-app.jar
# Couche 4 : executer
CMD ["java", "-jar", "/app/my-app.jar"]
Quand on lit tranquillement le contenu d’un Dockerfile, on se rend compte que sa structure n’est pas si compliquée. « Installe Ubuntu, FROM, installe Java, RUN, apporte mon code, COPY, puis exécute-le, CMD. »
Au fond, on a simplement pris le processus de configuration du serveur que l’on tapait autrefois à la main dans une VM ou dans un terminal serveur, et on l’a écrit noir sur blanc dans un document. Avec cette seule feuille, Docker déroule l’installation tout seul, sans qu’on ait besoin de l’accompagner pas à pas. Cette idée rejoint aussi, plus tard, le principe central de l’automatisation CI/CD.
Mais pourquoi Docker ne compacte-t-il pas tout ce processus en une seule étape ? Pourquoi le découpe-t-il volontairement ligne par ligne en layers et les empile-t-il soigneusement ?
La réponse, c’est la réutilisation par le cache. Si je modifie le code et que je rebuild, Docker réfléchit intelligemment : « Le premier étage, l’OS, et le deuxième, Java, sont exactement les mêmes qu’avant. Il n’y a donc aucune raison de les reconstruire. Je vais simplement réutiliser les layers déjà présents dans le cache. »
Ensuite, il ne reconstruit qu’à partir du troisième étage modifié, c’est-à-dire la copie du code. C’est pour cela que le deuxième build s’est terminé en seulement 0,1 seconde.
[Code Verification] Voir le cache des layers de ses propres yeux
Ne nous contentons pas de le dire, vérifions-le avec du code. Il suffit de créer un Dockerfile simple et de lancer deux builds.
FROM alpine:latest
RUN echo "1. Installation des outils de base..." && sleep 2 # Prend 2 secondes
COPY test.txt /app/test.txt
CMD ["cat", "/app/test.txt"]
$ docker build -t my-test:v1 .
# Resultat :
# [2/3] RUN echo "1. Installation des outils de base..." ... 2.1s (a pris 2s)
$ docker build -t my-test:v2 .
# Resultat :
# [2/3] RUN echo "1. Installation des outils de base..." ... CACHED (0s !)
Vous voyez ce mot CACHED clairement affiché dans les logs ? C’est la preuve que Docker a sauté une opération qui prend normalement deux secondes.
Conseil pratique : l’ordre est vital
Quand on comprend ce principe de cache par layer, la façon de rédiger un Dockerfile devient évidente. L’idée centrale est simple : « Mettez en bas, donc en premier, ce qui change peu, et en haut, donc plus tard, ce qui change souvent. »
Mauvais exemple :
# 1. Copier d abord le code source (change souvent)
COPY . .
# 2. Installer les bibliotheques (rarement modifie)
RUN npm install
Le code source change des dizaines de fois par jour. Si l’étape 1 change, Docker invalide aussi le cache de l’étape 2, l’installation des bibliothèques, et relance tout. On corrige une seule ligne de code et on se retrouve à attendre de nouveau npm install.
Bon exemple :
# 1. Copier uniquement package.json d abord
COPY package.json .
# 2. Installer les bibliotheques (reste en cache)
RUN npm install
# 3. Copier le code source
COPY . .
En changeant simplement l’ordre, on peut rendre le build dix fois plus rapide. C’est exactement la différence entre un débutant sur Docker et quelqu’un qui le maîtrise vraiment.
Conseil pratique 2 : les tags sont une ligne de vie
Dans l’exemple ci-dessus, j’ai écrit docker build -t my-test:v1 .. Ici, le v1 qui apparaît après les deux-points, :, est le tag.
Beaucoup de débutants ne mettent pas de tag parce qu’ils trouvent cela fastidieux. Dans ce cas, Docker attribue automatiquement le tag latest.
Cette simple habitude de tag vous fera gagner de nombreuses soirées plus tard.
En conclusion : tenir entre ses mains la magie des 0,1 seconde
Une image Docker n’est pas juste un paquet de fichiers. C’est un condensé de technique empilé couche par couche pour livrer un environnement de la manière la plus efficace possible. Si l’on comprend le cache des layers et que l’on ordonne bien son Dockerfile, on peut mettre en place un environnement de déploiement léger et rapide qui se construit en 0,1 seconde.
Tout est désormais prêt pour figer parfaitement l’environnement de mon ordinateur sous forme d’image et l’envoyer au serveur.
Mais quand j’ai voulu réellement lancer cette image sur le serveur, une nouvelle question est apparue. Un service web ne tourne pas avec un seul container serveur. Il lui faut aussi une base de données, Redis et un serveur frontend.
Peut-on vraiment gérer tous ces containers en les allumant et les éteignant un par un avec des commandes séparées ? Comment communiquent-ils entre eux ? Au-delà d’une simple « image », comment structure-t-on une application entière ? La prochaine fois, élargissons l’univers Docker avec les concepts de containers, services et stacks.