검색은 깔끔해졌는데, 쿼리 로그가 이상하다
이전 글에서 QueryDSL로 동적 검색을 깔끔하게 만들었다. 조건이 늘어나도 코드 구조가 망가지지 않았다. 검색 기능 자체는 만족스러웠다.
그런데 운영 중에 목록 조회가 느리다는 피드백이 들어왔다. 원인을 찾기 위해 Hibernate SQL 로그를 켰다.
# application.yml
spring:
jpa:
show-sql: true
properties:
hibernate:
format_sql: true
프로젝트 목록 10개를 조회했을 뿐인데, 로그에 찍힌 쿼리가 이랬다.
Hibernate: select p.* from project p where ... -- 1번: 프로젝트 목록 Hibernate: select m.* from member m where m.id = ? -- 2번: 1번 프로젝트의 담당자 Hibernate: select m.* from member m where m.id = ? -- 3번: 2번 프로젝트의 담당자 Hibernate: select m.* from member m where m.id = ? -- 4번: 3번 프로젝트의 담당자 ... Hibernate: select m.* from member m where m.id = ? -- 11번: 10번 프로젝트의 담당자
프로젝트 10개를 가져오는 쿼리 1개, 각 프로젝트의 담당자를 가져오는 쿼리 10개. 총 11개. 프로젝트가 100개면 101개, 1000개면 1001개.
이것이 JPA를 쓰면 거의 반드시 만나게 되는 ‘N+1 문제’다.
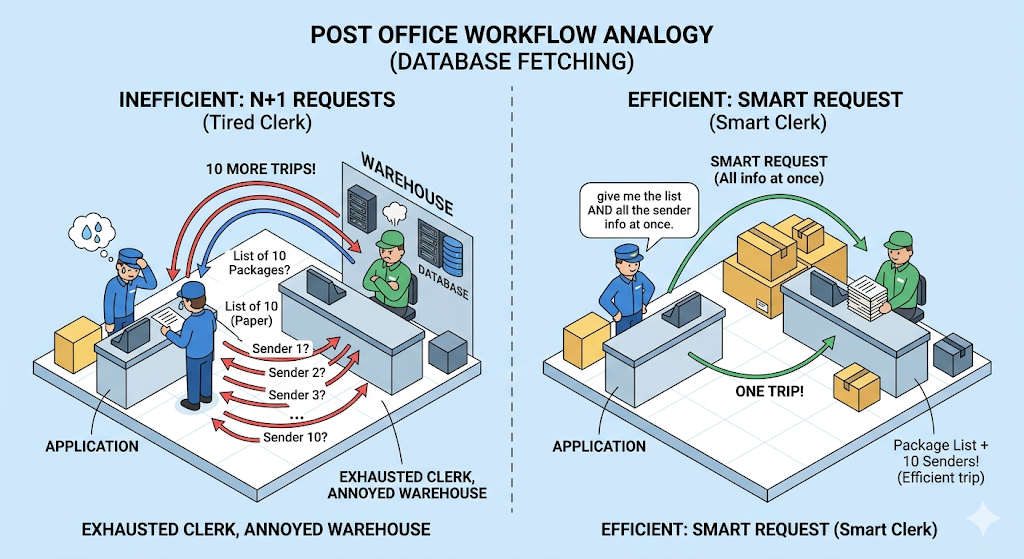
N+1 문제란 무엇인가
N+1 문제의 구조는 단순하다.
- 1번 쿼리: 엔티티 목록을 조회한다 (프로젝트 10개)
- N번 쿼리: 각 엔티티의 연관 엔티티를 개별 조회한다 (담당자 10명)
왜 이런 일이 생길까? JPA의 ‘지연 로딩(Lazy Loading)’ 때문이다.
@Entity
public class Project {
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY) // 지연 로딩
private Member manager; // 담당자
}
FetchType.LAZY로 설정하면, 프로젝트를 조회할 때 담당자 정보를 바로 가져오지 않는다. 대신 담당자에 접근하는 시점에 추가 쿼리를 실행한다. ‘필요할 때 가져온다’는 합리적인 전략이지만, 목록 조회에서는 함정이 된다.
// N+1이 터지는 코드
List<Project> projects = projectRepository.findAll(); // 쿼리 1번
for (Project project : projects) {
String managerName = project.getManager().getName(); // 프로젝트마다 추가 쿼리!
System.out.println(project.getName() + " - " + managerName);
}
findAll()로 프로젝트 10개를 가져온다 (1번). 반복문에서 getManager().getName()을 호출할 때마다 Hibernate가 담당자를 개별 조회한다 (N번). 결과적으로 1 + N = 11번의 쿼리가 실행된다.
그렇다면 ‘즉시 로딩(EAGER)’으로 바꾸면 해결될까?
@ManyToOne(fetch = FetchType.EAGER) // 즉시 로딩 private Member manager;
아니다. EAGER로 바꿔도 N+1은 여전히 발생할 수 있다. EAGER는 “무조건 같이 가져오라”는 지시이지, “한 쿼리로 가져오라”는 지시가 아니다. Hibernate는 EAGER 관계를 각각의 SELECT로 처리할 수 있다. 게다가 EAGER는 해당 연관을 사용하지 않는 곳에서도 항상 로딩되므로, 오히려 성능이 나빠진다.
결론은 명확하다. ‘로딩 전략(LAZY/EAGER)으로는 N+1을 근본 해결할 수 없다. 해결은 쿼리에서 해야 한다.’
해결: fetch join으로 한 번에 가져오기
fetch join은 “이 연관 엔티티를 별도 쿼리가 아니라 같은 쿼리의 JOIN으로 한 번에 가져와라”는 지시다.
일반 JOIN과 fetch join의 차이를 먼저 이해하자.
-- 일반 JOIN: 조건 필터링만, 연관 엔티티 데이터를 가져오지 않음 SELECT p FROM Project p JOIN p.manager m WHERE m.name = '홍길동' -- fetch JOIN: 연관 엔티티 데이터까지 한 번에 가져옴 SELECT p FROM Project p JOIN FETCH p.manager
일반 JOIN은 “담당자가 홍길동인 프로젝트를 찾아라”처럼 조건에만 쓰인다. 프로젝트는 가져오지만 담당자 데이터 자체는 로딩하지 않는다. 나중에 getManager()를 호출하면 여전히 추가 쿼리가 나간다.
fetch JOIN은 프로젝트와 담당자를 한 쿼리로 동시에 가져온다. getManager()를 호출해도 추가 쿼리가 나가지 않는다.
JPQL에서 fetch join
@Query("SELECT p FROM Project p JOIN FETCH p.manager")
List<Project> findAllWithManager();
이것 하나로 쿼리가 11개에서 1개로 줄어든다.
-- 실행되는 SQL (1번만 실행) SELECT p.*, m.* FROM project p INNER JOIN member m ON p.manager_id = m.id
QueryDSL에서 fetch join
이전 글에서 만든 QueryDSL 검색에도 같은 원리를 적용할 수 있다.
public List<Project> searchWithFetchJoin(ProjectSearchCondition condition) {
QProject project = QProject.project;
QMember manager = QMember.member;
return queryFactory
.selectFrom(project)
.join(project.manager, manager).fetchJoin() // fetch join
.where(
statusEq(condition.getStatus()),
regionEq(condition.getRegion())
)
.fetch();
}
.join().fetchJoin()을 추가하는 것만으로 N+1이 해결된다. 기존 QueryDSL 코드 구조를 거의 건드리지 않아도 된다.

보조 대안: @EntityGraph
fetch join을 JPQL이나 QueryDSL 없이, Spring Data JPA의 메서드 쿼리에서도 사용하고 싶을 때가 있다. 이때 @EntityGraph를 쓸 수 있다.
public interface ProjectRepository extends JpaRepository<Project, Long> {
@EntityGraph(attributePaths = {"manager"})
List<Project> findAll();
@EntityGraph(attributePaths = {"manager"})
List<Project> findByStatus(String status);
}
어노테이션 하나로 fetch join과 동일한 효과를 낸다. 코드 변경이 최소화되는 것이 장점이다.
| 방식 | 장점 | 단점 |
|---|---|---|
| JPQL fetch join | 명시적, 유연한 조건 조합 | 쿼리 문자열 직접 작성 |
| QueryDSL fetch join | 동적 쿼리와 결합 가능, 타입 안전 | QueryDSL 설정 필요 |
| @EntityGraph | 코드 변경 최소, 간결 | 동적 조건 조합 불가, 복잡한 그래프에 한계 |
단순한 정적 조회에는 @EntityGraph가 편하고, 동적 검색에는 QueryDSL fetch join이 적합하다. 상황에 맞게 선택하면 된다.
실무 조언: fetch join이 만능은 아니다
fetch join은 N+1의 핵심 해결책이지만, 모든 상황에서 쓸 수 있는 것은 아니다.
1. 컬렉션 fetch join과 페이징은 같이 쓰면 위험하다
@OneToMany 같은 컬렉션 관계에서 fetch join과 페이징을 함께 사용하면, Hibernate가 경고를 띄운다.
WARN - firstResult/maxResults specified with collection fetch; applying in memory!
이 경고의 의미는 이렇다. 컬렉션 fetch join을 하면 결과 행이 뻥튀기된다 (프로젝트 1개에 태스크 5개면 5행). Hibernate는 DB에서 페이징을 할 수 없으니, 모든 데이터를 메모리에 올린 뒤 애플리케이션에서 페이징을 한다. 데이터가 많으면 메모리 부족(OOM)이 발생할 수 있다.
대안은 두 가지다.
// 대안 1: Batch Size 설정 (fetch join 대신)
@Entity
public class Project {
@OneToMany(mappedBy = "project")
@BatchSize(size = 100) // IN 절로 100개씩 묶어서 조회
private List<Task> tasks;
}
// 또는 글로벌 설정
// application.yml
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100
Batch Size는 N+1을 ‘1+1’로 줄여준다. 프로젝트 10개의 태스크를 한 번의 IN 쿼리로 가져온다. fetch join만큼 극적이지는 않지만, 페이징과 충돌하지 않는다.
-- Batch Size 적용 시 SELECT * FROM project WHERE ... LIMIT 10 OFFSET 0; -- 페이징 OK SELECT * FROM task WHERE project_id IN (1,2,3,4,5,6,7,8,9,10); -- 1번으로 해결
// 대안 2: ID를 먼저 조회한 뒤 fetch join으로 재조회
List<Long> projectIds = queryFactory
.select(project.id)
.from(project)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
List<Project> result = queryFactory
.selectFrom(project)
.join(project.tasks, task).fetchJoin()
.where(project.id.in(projectIds))
.fetch();
2. MultipleBagFetchException
두 개 이상의 컬렉션(@OneToMany)을 동시에 fetch join하면 예외가 발생한다.
// 이렇게 하면 에러!
SELECT p FROM Project p
JOIN FETCH p.tasks
JOIN FETCH p.comments
해결법은 하나만 fetch join하고 나머지는 Batch Size로 처리하거나, 컬렉션 타입을 List 대신 Set으로 바꾸는 것이다.
3. N+1 탐지: 실무 체크리스트
| 시점 | 방법 |
|---|---|
| 개발 중 | spring.jpa.show-sql=true로 쿼리 수 확인 |
| 테스트 | 쿼리 카운트 검증 (예: hibernate.session.metrics) |
| 운영 | 슬로우 쿼리 모니터링, APM 도구 활용 |
가장 확실한 방법은 “목록 조회 후 로그에 쿼리가 몇 개 찍히는지 세는 것”이다. 목록 10개를 조회했는데 쿼리가 10개 넘게 나오면, N+1을 의심하자.

마치며: 쿼리 수를 세는 습관
N+1 문제는 JPA를 쓰는 한 계속 마주칠 수밖에 없는 문제다. 하지만 원리를 알면 대응은 간단하다.
- 연관 엔티티를 함께 조회해야 한다면 → fetch join
- 페이징이 필요하거나 컬렉션이 여러 개라면 → Batch Size
- 단순한 정적 조회라면 → @EntityGraph
핵심은 “쿼리가 몇 개 나가는지 세는 습관”이다. show-sql을 켜고 목록 조회 한 번 해보면, 최적화할 곳이 바로 보인다.
지금까지 Spring Garden 시리즈에서 인증(Security), 쿼리(QueryDSL), 성능(N+1)을 다뤘다. 이 코드들이 제대로 동작하는지는 어떻게 검증할까? 수동으로 Postman을 띄워서 하나씩 확인하는 건 한계가 있다.
다음 글에서는 Spring Boot에서 테스트를 작성하는 실무적인 방법을 다뤄보겠다. MockMvc로 API를 검증하고, Testcontainers로 실제 DB를 띄워서 통합 테스트까지.