“Data duplication is absolute evil”
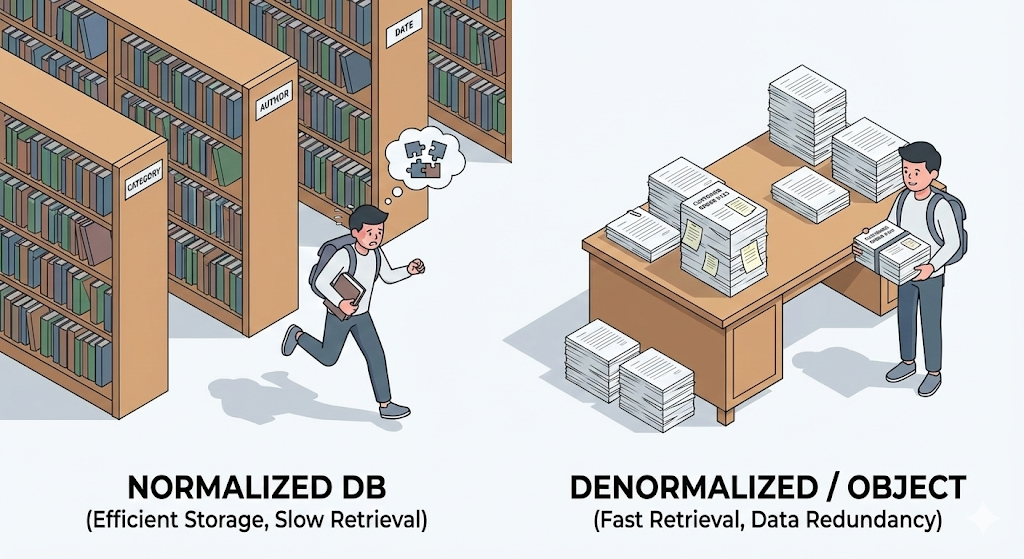
In my university database class, the professor emphasized it so hard that spit was flying. “First normal form, second normal form, third normal form… duplicated data wastes storage space and damages integrity. Split it up, and then split it again!”
I followed that teaching faithfully. During my graduation project, I split tables into 10, then 20 separate pieces. ‘User’, ‘Address’, ‘City’, ‘Zipcode’… My database design was so perfectly “by the book” that storing a single address required three different tables.
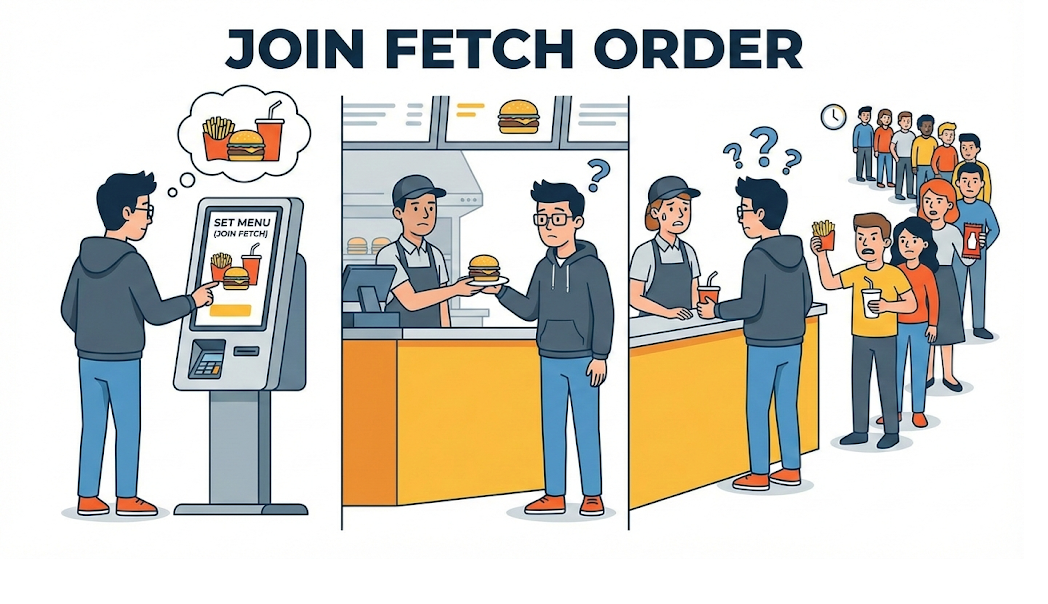
But in real-world work, that perfect design turned into a disaster. I only wanted to fetch a single customer list, and yet I had to write five JOINs. The query became complicated, performance got slower, and worst of all, moving that data into Java objects was painfully cumbersome.
“Why is the code this complicated when I’m just trying to fetch one row of data to show on the screen?”
Only then did I realize it. In school, they taught us how to optimize for storing data. In real work, optimizing reads matters far more. And between an object-oriented language like Java and a relational database, there flows a river that is much harder to cross than I had imagined.
Paradigm mismatch: squares and circles
The fundamental cause of this pain is what we call an impedance mismatch between paradigms.
Back in college, I forced these two worlds together by writing SQL directly. I broke Java objects apart to store them in the database with INSERTs, then pulled rows back out with SELECT, reading them line by line from a ResultSet and stuffing them one by one into Java collections like Set or List. I did not feel like a developer. I felt like a data translator.
What appeared to solve that tedious repetition was JPA (Java Persistence API), in other words, ORM (Object-Relational Mapping).
JPA and ORM: handling databases through objects
ORM literally means a technology that maps objects and relational databases together. As the term suggests, the key idea is that you define and work with database tables as if they were Java objects.
We no longer need to handwrite CREATE TABLE queries. Instead, we create a Java class and attach a sticker called @Entity. Then JPA, the Java standard for ORM, looks at that class and says, “Ah, so this is the shape of the table you need,” and creates the table in the database automatically.
Saving data also stops being a matter of writing SQL. You can just write something like repository.save(member), the way you would add something to a Java collection. The developer stays completely in an object-oriented way of thinking, while the messy SQL translation work gets pushed onto JPA.
But as we learned in the Re: Booting series, convenience always has a price. Because I trusted that automatic translator called JPA too much, I planted a time bomb in my code: the N+1 problem.
[Code Verification] The N+1 problem, a bomb made of queries
This is a problem that practically every junior developer runs into the first time they use JPA. The situation is simple: “Print every member together with the name of the team that member belongs to.”
// 1. Fetch all members (1 query fired)
List<Member> members = memberRepository.findAll();
for (Member member : members) {
// 2. Print each members team name
// If there are 100 members, 100 extra queries run to fetch team info!
System.out.println(member.getTeam().getName());
}
The query we expected: SELECT * FROM Member JOIN Team ... (just once)
The query that actually happened:
If there are 100 members, the database gets hit with 101 queries: 1 + N. If there are 10,000 members? Then 10,001 queries slam into the database. That is the infamous N+1 problem, the kind of issue that can bring down a server. JPA tried to be convenient by loading related data lazily, one piece at a time, and that very convenience turned into the disaster.
Practical advice: pragmatic database design
So what should we do in real work? We need to strike a balance between textbook normalization and the convenience of JPA.
Closing: to get more convenience, you have to know more
JPA is absolutely a revolution. It freed us from the mind-numbing repetition of writing SQL over and over again. But thinking, “Since I use JPA now, I don’t need to know SQL anymore,” is dangerous.
JPA is not a magician. It is just a secretary that writes SQL on your behalf. If you give bad instructions to that secretary, through a poor mapping, eager loading, and so on, the secretary will quietly fire off one hundred queries and bring down the database. To monitor and tune whether the SQL generated by JPA is actually efficient, you paradoxically need to understand SQL more deeply. Comfort always comes with responsibility.
Now we know how to put data into objects. But can we just send those objects, those entities, straight to the frontend, to Vue.js? What if the User entity contains a password? And what happens to security if we send the frontend information it was never supposed to receive?
Next time, let’s talk about DTOs, Data Transfer Objects, and REST API design, the techniques used to package data safely for delivery.